
Open Access Journal of Applied Science and Technology(OAJAST)
ISSN: 2993-5377 | DOI: 10.33140/OAJAST
Impact Factor: 1.08


Research Article - (2026) Volume 4, Issue 1
Quantum Hierarchy for Understanding LLM Representations by Modeling Linear Projections and Nonlinear Dynamics
Received Date: Jan 23, 2026 / Accepted Date: Feb 27, 2026 / Published Date: Mar 04, 2026
Copyright: ©2026 Timo Aukusti Laine. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Laine, T. A. (2026). Quantum Hierarchy for Understanding LLM Representations by Modeling Linear Projections and Nonlinear Dynamics. OA J Applied Sci Technol, 4(1), 01-43.
Abstract
Large Language Models (LLMs) excel in natural language tasks, but their high-dimensional embedding spaces pose significant interpretability challenges. Current approaches often linearize these spaces, overlooking the complex dynamics inherent in Transformer architectures. This article proposes a quantum framework to analyze LLM representations, leveraging quantum mechanical tools to explore semantic relationships and contextual influences. We introduce a layered hierarchy of semantic spaces and demonstrate that a classical LLM embedding system has an exact quantum mechanical analogue. Using this analogue, we model phenomena such as the modulation of Semantic Noise, the emergence of hallucinations via quantum tunneling, and the formation of stable semantic representations as soliton solutions. Furthermore, we present a simple quantum circuit design, demonstrating the possibility of using quantum computers to probe, analyze and go beyond real-valued LLM embedding spaces, potentially revealing structural information and relationships not readily accessible through classical techniques. This perspective enhances our understanding of LLM representations, leading to improved methods for analyzing and controlling LLM behavior, and supporting research into more efficient, reliable, and trustworthy AI systems.
Introduction
Large Language Models (LLMs) have achieved remarkable success in natural language processing, yet their underlying mechanisms remain largely opaque. The high-dimensional embedding spaces that power LLMs pose significant challenges to interpretability, hindering our ability to fully understand and control their behavior. Current approaches often rely on linearizing these spaces, an oversimplification that overlooks crucial nonlinear dynamics, such as those present in the Transformer architecture. Specifically, the attention mechanism, a core component of the Transformer, introduces complex, non-local interactions between words, which are not adequately captured by static, linear representations. Furthermore, the activation functions within the feedforward networks introduce nonlinear transformations that shape the semantic landscape in intricate ways.
The development and deployment of current LLMs demand vast computational resources, making them expensive to train and use. This raises a critical question: Can we develop more efficient LLM architectures, or find ways to optimize the use of existing LLM architectures? Also, the tendency of LLMs to generate factually incorrect or nonsensical statements (hallucinations) limits their reliability and hinders their adoption in business-critical applications. These hallucinations are not simply random errors; they often exhibit a degree of semantic coherence, suggesting that they arise from complex interactions within the LLM’s internal representations. A deeper understanding of the origins and dynamics of hallucinations is essential for building more trustworthy and robust LLMs.
To address these challenges, this article proposes a quantum framework for analyzing LLM representations. We leverage the tools and concepts of quantum mechanics to explore semantic relationships, contextual influences, and the underlying dynamics of LLM embedding spaces. Our approach is motivated by the discrete nature of LLM embedding spaces and the inherent uncertainties associated with semantic meaning, both of which find natural parallels in quantum mechanics. This work synthesizes and extends our previous research, providing a unified perspective on these quantum-inspired models while also introducing new insights and, crucially, establishing a concrete link to quantum computation, demonstrating the potential for using quantum computers to directly probe and analyze LLM embedding spaces.
The key contributions of this article are:
• A Layered Quantum Hierarchy: We introduce a layered hierarchy of semantic spaces, ranging from the linearized embedding space to the full Transformer architecture, with intermediate layers incorporating linear and nonlinear quantum dynamics.
• An Exact Quantum Analogue: We demonstrate the existence of a classical LLM embedding system and a quantum mechanical LLM Embedding Quantum System whose mathematical descriptions are equivalent, providing a concrete link between the classical and quantum domains.
• Quantum Explanations: We show how the quantum system can be used to explain phenomena such as the management of Semantic Noise (through local U(1) symmetry), hallucinations (through quantum tunneling), and the emergence of Self-Sustaining Semantic Structures, i.e., stable, localized patterns of semantic meaning which we also refer to as localized semantic stability (through soliton solutions).
• A Path to Quantum Computation: We present a simple quantum circuit design for calculating cosine similarity, demonstrating the potential for using quantum computers to probe and analyze LLM embedding spaces.
This quantum perspective offers a framework for understanding LLM representations, leading to improved methods for analyzing and controlling LLM behavior. By providing a framework for applying quantum computing techniques to LLMs, we promote the way for future research into more efficient, reliable, and trustworthy AI systems, leveraging the insights gained from our quantum analysis, particularly through a deeper understanding of semantic relationships and the mitigation of hallucinations.
Background and Related Work
Large Language Models (LLMs) have revolutionized natural language processing, achieving remarkable feats in text generation, translation, and question answering. Trained on massive datasets of text and code, these models learn to predict the next word in a sequence, a process that gives rise to their emergent capacity for sophisticated language understanding and generation [1]. A core component of LLMs is the embedding space: a high-dimensional vector space where words, phrases, and even entire documents are represented as points. The location of each point is carefully learned to reflect the semantic meaning of the corresponding linguistic unit. Semantically similar words, or those used in similar contexts, are clustered together, enabling the model to recognize and exploit complex relationships within language.
Early techniques like Word2Vec and GloVe pioneered the development of word embeddings, mapping words to vectors where proximity reflects semantic similarity [2,3]. These advancements built upon foundational work by Bengio et al. on neural probabilistic language models and the principles of distributional semantics, which posits that a word’s meaning is intrinsically linked to the contexts in which it appears [4,5]. Research on semantic compositionality, such as that by Socher et al., explores how the meanings of individual words combine to form the meaning of larger phrases and sentences [6]. Modern LLMs, particularly those based on the Transformer architecture, leverage contextualized word embeddings, where a word’s meaning is not fixed but dynamically determined by the surrounding words in the sentence [1]. This contextual sensitivity, enabled by the Transformer’s attention mechanisms, allows for a more nuanced and flexible representation of language, overcoming limitations of earlier, static word embeddings. The attention mechanism also facilitates parallel processing and improved handling of long-range dependencies.
While embedding spaces, analyzed through techniques like cosine similarity, have proven incredibly powerful, they offer an inherently incomplete representation of the complex internal state of an LLM. Projecting the model’s intricate dynamics onto a linear vector space inevitably results in a loss of information. Certain dynamic and nonlinear aspects of semantic meaning are simply not captured by these static representations. This inherent incompleteness can manifest in various ways, including the generation of factually incorrect or nonsensical statements, commonly known as hallucinations. Recent surveys have highlighted the prevalence and diverse nature of hallucinations in natural language generation. This problem is closely related to issues of factuality and knowledge representation in LLMs, as explored by Ji et al. and the challenges of relying solely on statistical correlations without a deeper understanding of causality [7,8]. While techniques based on Shannon’s information theory and Kullback-Leibler divergence offer tools for quantifying information and measuring differences between probability distributions, they often fall short of capturing the subtle nuances of semantic representation that are crucial for understanding and mitigating issues like hallucinations in LLMs [9-12].
The principles of quantum mechanics, while developed for the physical world, offer a unique perspective on handling uncertainty and contextuality that may be relevant to understanding LLMs. The potential for quantum computation to enhance machine learning is an active area of research [13,14]. Quantum algorithms, such as Grover’s algorithm and Shor’s algorithm, offer potential speedups for certain computational tasks, and quantum circuits are being explored for use in machine learning models [15-17]. DiVincenzo’s criteria for physical implementations of quantum computation highlight the challenges of building actual quantum computers, but also underscore the fundamental principles that govern quantum information processing. Moreover, the application of quantum-inspired methods to machine learning, such as quantum-enhanced feature spaces and quantum neural networks, demonstrates the potential for quantum concepts to improve classical machine learning algorithms [18-20]. Nielsen and Chuang’s seminal work on quantum computation and quantum information provides a solid foundation for understanding these concepts [21]. Khrennikov’s work on ubiquitous quantum structure explores the application of quantum-like models in various domains, including cognition and decision-making, providing further justification for our approach. Hybrid quantum-classical approaches are also being explored to enhance LLM fine-tuning, with some studies demonstrating improved accuracy compared to purely classical models [22,23].
The Hamiltonian operator represents the total energy of a quantum system. We can adapt this concept to represent the energy landscape of semantic meaning, capturing the relative stability of different semantic states. Just as the Schrödinger equation describes the time evolution of a quantum system, we can use it to model the dynamics of semantic meaning as it unfolds over time. Concepts from statistical mechanics, such as phase transitions and critical phenomena, may provide insights into the emergent behavior of LLMs and the transitions between different semantic states [24–27]. The use of path integrals provides a powerful tool for analyzing quantum systems and may offer insights into the long-range dependencies in LLMs, as explored in our previous work [28,29]. These quantum mechanical principles, while seemingly abstract, offer a powerful framework for addressing the limitations of traditional approaches to understanding LLMs.
This motivates our exploration of concepts and mathematical tools from the seemingly disparate field of quantum mechanics. We propose to leverage quantum mechanics as a powerful analogy, providing a new perspective on the complex and uncertain nature of semantic meaning, particularly in understanding and managing Semantic Noise, a key factor influencing LLM behavior. This article builds upon our previous research exploring the application of quantum-inspired models to LLMs [29–33].
Quantum Semantic Hierarchy
This article proposes a framework to bridge the gap between the simplified, linearized embedding space and the intricate Transformer architecture. Our central idea is that these represent opposite ends of a spectrum, and a more nuanced understanding requires exploring intermediate layers that capture different facets of the LLM’s internal representations. To achieve this, we introduce a quantum semantic hierarchy, leveraging concepts and tools from quantum mechanics to analyze LLM representations.
The quantum approach is underpinned by several key motivations.
1. The discrete nature of LLM embedding spaces suggests a formalism where semantic states are treated as distinct entities, aligning well with the state-based description in quantum mechanics.
2. The prevalence of hallucinations in LLMs points to inherent uncertainties in their processing, particularly regarding the semantic validity or factual correctness of generated content, which is a core concept in quantum mechanics.
3. As we will demonstrate in later sections, a classical ”LLM Embedding System” can be defined with an exact quantum mechanical analogue exhibiting zero-point energy, providing a concrete link between the classical and quantum descriptions.
4. Additionally, the quantum mechanical analogue of the LLM Embedding System exhibits a superposition between the quantum states corresponding to the two LLM Embedding System embedding vectors, reflecting the inherent relationships between these semantic representations. These reasons, among others, provide a strong rationale for using quantum mechanics as a natural extension of the real embedding space, enabling us to leverage its tools and concepts to analyze semantic dynamics.
Based on these observations, we propose a hierarchy of intermediate layers, each progressively integrating a level of complexity and capturing different facets of the LLM’s internal representations. This layered structure comprises:
• Layer 1: Linearized Embedding Space (Classical Semantic Space): This simplest layer is a direct projection of the LLM’s internal representations into a low-dimensional vector space. It is valuable for basic semantic comparisons but lacks the capacity to model dynamic behaviors. As demonstrated in, the linear embedding space exhibits a discrete structure, meaning there is no continuous transformation between the embedding vectors [32]. The key focus of Layer 1 is providing a foundational, static representation of semantic relationships.
• Layer 2: Quantum Semantic Space (Linear Dynamics): This layer introduces linear dynamics by treating the embedding space as a quantum mechanical system. By incorporating complex state vectors and time dependence, we can employ the linear Schrödinger equation to model the evolution of semantic representations over time. This approach allows us to capture phenomena such as conservation of the Semantic Noise level, linking it to semantic ”charge” conservation, and hallucinations, which can be related to quantum mechanical tunneling.
• Layer 3: Quantum Semantic Space (Nonlinear Dynamics): This layer builds upon Layer 2 by introducing nonlinear interactions, enabling the modeling of more complex behaviors and feedback loops, including the emergence of stable, localized soliton solutions. These non-local interactions, as shown in, allow semantic meaning at one point to directly influence meaning at distant points, resembling quantum entanglement and capturing LLMs’ ability to model long-range dependencies through the Transformer’s attention mechanism [29].
• Layers 4-N: Advanced Quantum Hierarchies: These layers represent more advanced quantum models that can capture even more complex aspects of LLM behavior. They offer the potential to model dynamic creation and annihilation of semantic content.
• Layer N+1: Transformer Architecture (Common LLM Architecture): This layer represents the complete Transformer architecture, encompassing all its intricacies, with real-valued activations and parameters. It provides a concrete realization of the complex dynamics and interactions modeled in the earlier layers.
• Layer N+2: Complex Transformer Architecture (Complex Semantic Superspace): This layer builds upon Layer N+1 by extending the Transformer architecture to operate with complex-valued representations. It leverages complex-valued representations to improve robustness and performance in specific domains.
The hierarchy of the layers is shown in Figure 1
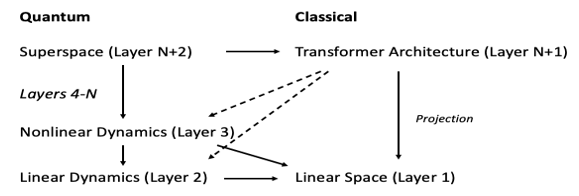
Figure 1: The Quantum Semantic Hierarchy: A multi-layered framework for understanding LLM representations. The hierarchy spans from the classical linearized embedding space (Layer 1) to the complex Transformer architecture (Layers N+1 and N+2), with intermediate quantum layers (Layers 2, 3, and 4-N) progressively incorporating linear and nonlinear dynamics. This layered approach allows for analyzing LLM behavior at different levels of abstraction, with each layer serving as a projection or sub-layer of the layer above.
The guiding principle is that each layer serves as a projection or sub-layer of the layer above it: Layer 1 projects onto Layer 2, Layer 2 onto Layer 3, and Layer 3 onto Layers 4-N. Layers 4-N are sub-layers of Layer N+2, and Layer N+1 is a sub-layer of Layer N+2. While quantum sub-layers 2 and 3 incorporate characteristics of Layer N+2, the mapping from Layer N+1 (the Transformer architecture) to these complex sub-layers is not always straightforward. The Transformer architecture possesses a complex internal structure absent in the quantum sub-layers, and conversely, the quantum sub-layers introduce a phase component not present in Layer N+1. However, as demonstrated in later sections, similarities and shared structures emerge when the system is examined in its eigenspace. Consequently, each layer captures a simplified view of the underlying complexity, with each projection resulting in some loss of information. The appropriate layer to use depends on the specific phenomenon under investigation. For instance, if we are interested in the dynamics of Semantic Noise and its relationship to hallucinations, Layer 2 (Quantum Semantic Space with Linear Dynamics) might suffice, allowing us to model the interplay between inherent uncertainty and contextual influences.
After analyzing a phenomenon using a particular layer, we can project the results back to the linearized embedding space (Layer 1) to establish connections with familiar semantic representations. This is exemplified in Section X, where we demonstrate how the properties of the linearized embedding space can be recovered by applying specific approximations to equations in Layer 2 and 3.
The layered approach offers several advantages over existing methods. By providing intermediate levels of abstraction, it allows us to analyze LLM representations with the appropriate level of complexity, avoiding the oversimplification of linear models while remaining more tractable than analyzing the full Transformer architecture directly. The quantum framework provides a new set of tools and concepts for understanding LLM behavior, leading to new insights and improved analytical techniques. Also, as a quantum-based approach, it enables us to use quantum computers for testing and validating the results.
Essentially, we are proposing a ”zoom lens” approach: we focus on the level of complexity necessary to understand a particular phenomenon and then zoom out to relate our findings back to the familiar linearized embedding space. This layered strategy allows us to bridge the gap between the simplicity of the linearized embedding space and the complexity of the Transformer architecture, leading to a more nuanced and comprehensive understanding of LLM representations.
In the following sections, we will detail the characteristics of each Layers 1, 2, 3, 4-N, N+1 and N+2. We also demonstrate the linearization process and provide an example of experimental validation, achieved using a quantum computer.
Layer 1: Linearized Embedding Space (Classical Semantic Space)
We begin our analysis with the simplest layer in our hierarchy: the linearized embedding space, which we also term the classical semantic space. This layer provides a foundation for understanding the fundamental properties of semantic relationships in LLMs.
The LLM Embedding System
To facilitate our analysis and gain insights into the core dynamics of LLM representations, we introduce a simplified, classical model of LLM embedding spaces, which we term the ”LLM Embedding System.” This system, detailed in reference, allows us to explore the fundamental properties of semantic relationships in a controlled and tractable setting, providing a crucial stepping stone to understanding the more complex quantum layers [32].

These assumptions allow us to create a tractable model for exploring fundamental semantic relationships and transformations, while also acknowledging the inherent limitations in capturing the full spectrum of semantic uncertainty, or Semantic Noise, present in real LLM embedding spaces. This LLM Embedding System will serve as a foundation for our subsequent analysis, providing a crucial link to the more complex quantum layers.
Classical Hamiltonian Representation
To facilitate a quantum analysis of the LLM Embedding System, we now introduce a Hamiltonian representation [32]. This allows us to leverage the tools and concepts of quantum mechanics to explore the dynamics of semantic relationships.

This transformation maps the original cosine similarity, SC (ranging from -1 to 1), to a new similarity measure, S′C (ranging from 0 to 1). This allows us to express the similarity in a form that resembles probabilities or normalized measures, which will be particularly useful when we interpret S′C as a quantum mechanical observable in later sections, especially in Layer 2, Quantum Semantic Space. We can express this transformed similarity using a modified Hamiltonian H′

Transformation and Diagonalization
To further analyze the dynamics of semantic representations and simplify the Hamiltonian, we now introduce transformations and diagonalize the Hamiltonian matrix H′. Diagonalization is a crucial step because it allows us to express the system in terms of its fundamental modes, providing a clearer understanding of its underlying structure and behavior.


The diagonalization of the Hamiltonian-like operator H′ yields two distinct types of modes: an active mode (λ1 = 1) and inactive modes (λi = 0 for i > 1). The active mode represents a general, system-wide property related to the potential for deviation from perfect coherence in the semantic representation. It reflects the level of Semantic Noise present in the system, which, as we have defined, is not simply a measure of ”fuzziness” but a crucial element that enables creativity, adaptation, and contextual sensitivity. A higher probability of the system being in the active mode indicates a greater potential for the system to explore alternative semantic interpretations. The inactive modes, on the other hand, represent specific, individual semantic features or dimensions in the embedding space. Each inactive mode corresponds to a particular aspect of the meaning being represented, such as sentiment, topic, or style. They represent coherent or ground states. If the embedding space dimension N is larger, there is a greater likelihood that the system is in a coherent state.
The LLM Embedding Quantum System exhibits a decoupled architecture: the diagonalized Hamiltonian D represents the potential for Semantic Noise as a universal property, characterized by a single active mode and numerous coherent ground states. The specific semantic relationship between vectors a and b, and thus the cosine similarity, is encoded within the unitary matrix U, particularly in the eigenvector x1 derived from the vector v. This vector defines the direction in the embedding space along which the system is most likely to deviate from perfect coherence, acting as an ”axis of Semantic Noise.” The cosine similarity, S′C , then becomes a measure of how much this potential for noise is realized in the relationship between the two vectors, highlighting the importance of considering the underlying dynamics and the management of Semantic Noise in shaping semantic representations.
Partition Function and Interpretation
We now derive and interpret a partition function based on the Hamiltonian H′. The partition function provides a tool for understanding the statistical distribution of semantic states in the LLM Embedding System [32]. This description bridges the gap between the vector representation and a system-level view of the embedding space. The classical partition function is defined as


This partition function provides a simplified model of the statistical distribution of semantic states in an LLM embedding space. The partition function, Z, quantifies the number of accessible states to the LLM embedding system at a given temperature. The term e−β represents the contribution of the excited state (associated with higher Semantic Noise), with energy 1. As the temperature T increases (Semantic Noise increases), e−β approaches 1, making the excited state more probable, and increasing the system’s capacity for exploration and adaptation. The term (N − 1) represents the contribution of the N −1 ground states (coherent), each having an energy of 0. The dimensionality N reflects the capacity of the LLM to represent different semantic features. In essence, the partition function Z describes a system that favors coherent semantic states unless Semantic Noise is sufficiently high. The dimensionality N plays a crucial role in determining the balance between these tendencies.
We can make the following conclusions about the partition function: The derived partition function suggests that higher dimensionality (N) in the LLM embedding space promotes a greater capacity for nuanced semantic representation by increasing the number of accessible coherent states. While lower dimensionality might increase Semantic Noise and exploration, this tendency is also modulated by the effective temperature (β) and the weighting of semantic features (v).
Implications for Few-Shot Learning: LLMs with higher-dimensional embedding spaces exhibits better few-shot learning capabilities, as the increased number of coherent states facilitates adaptation to new tasks with limited examples by readily providing a suitable representation within the existing semantic landscape, while still allowing for sufficient Semantic Noise to explore new combinations.
Trade-off between Coherence and Creativity: The model hints at a potential trade-off between maintaining strong semantic coherence and fostering creativity in LLMs. A strong bias towards coherence (high N, low T) constrains the exploration of new semantic combinations, while a weaker bias, allowing for greater Semantic Noise, fosters creativity at the expense of occasional incoherence.
The Role of Training Data: The characteristics of the training data likely influence the effective temperature (T) of the LLM, with highly consistent datasets leading to lower effective temperatures and a stronger bias towards coherence, while noisy or ambiguous datasets results in higher temperatures and increased exploration of states with higher Semantic Noise.
Robustness to Adversarial Attacks: LLMs biased towards coherent semantic states (high N, low T) demonstrates increased robustness to adversarial attacks, as the inherent tendency to revert to a coherent state may counteract subtle perturbations designed to mislead the model, provided that the level of Semantic Noise is not so low as to prevent adaptation to unforeseen inputs.
Layered Approach to Hallucinations: The layered hierarchy suggests that hallucinations in LLMs originates from distinct mechanisms at different levels of abstraction, ranging from errors in similarity calculations in the linearized embedding space to quantum tunneling between semantic states or complex feedback loops within the nonlinear dynamics of higher layers, with Semantic Noise playing a role in both enabling exploration and contributing to the likelihood of incoherent outputs.
Invariance of the Partition Function
We now demonstrate that the partition function is invariant under a unitary transformation. This invariance is a fundamental property that ensures the partition function is independent of the choice of basis used to describe the system. In other words, the statistical properties of the LLM Embedding System, as captured by the partition function, are not affected by a change of coordinates in the embedding space. This is important because it means that we can choose any convenient basis to analyze the system without changing the results. We begin with a unitary transformation

Conclusions of Classical Analysis
Our analysis thus far has focused on a linearized LLM Embedding System, allowing us to explore Hamiltonian dynamics, eigenvalues and eigenvectors, and even a classical partition function within a simplified framework. These linear structures reveal a surprising amount of underlying organization in the semantic space. However, when attempting to model deeper semantic concepts such as dynamic contextual influences, the emergence of hallucinations or nonlinear interactions, the limitations of this linearized embedding space become apparent. Therefore, we now turn to extending this formalism by incorporating concepts and tools from quantum mechanics, seeking to unlock a more nuanced and expressive representation of semantic dynamics, including a more complete understanding of Semantic Noise and its role in shaping LLM behavior.
Layer 2: Quantum Semantic Space (Linear Dynamics)
Having established a classical foundation, we now extend our framework by incorporating concepts from quantum mechanics. In this section, we demonstrate that by introducing time dependence and complex state vectors, the previously defined classical LLM Embedding system can be equivalently represented as a quantum mechanical system, exhibiting a characteristic zero-point energy.
Quantum Partition Function
Before introducing the ”LLM Embedding Quantum System”, we first discuss the quantum partition function. While the classical partition function provides a useful starting point for analyzing the statistical distribution of semantic states within the LLM Embedding System, its classical nature limits its ability to capture potential quantum-like properties. To explore these properties and to support the way for incorporating nonlinear effects in Layer 3, we now introduce a more general form of the partition function using a Hamiltonian operator. The quantum partition function is defined as

where Hˆ is the Hamiltonian operator representing the total energy of the system, and β is the inverse temperature. The Hamiltonian operator describes the energy landscape of the system, and its form dictates the possible states and their corresponding energies. This formalism allows us to consider a more complex energy landscape with many different energy levels and transitions between them. A key distinction from the classical partition function is that the quantum Hamiltonian, Hˆ , can include operators that do not commute. This non-commutativity is a fundamental aspect of quantum mechanics, allowing the partition function to capture effects arising from the uncertainty principle and the superposition of states, which are absent in the classical treatment. The advantage of the quantum Hamiltonian formalism lies in its ability to accommodate more complex relationships, nonlinear effects, and correlations between these components, revealing subtle effects within the embedding space that are not captured by the classical partition function. We will use the quantum partition function in the later sections.
The LLM Embedding Quantum System
There are two main fundamentals which differentiate a quantum system from a classical system: a complex state vector, which introduces the concept of phase, and the time-dependency of the state vector. To capture the dynamic evolution of semantic meaning within the LLM Embedding System, we now introduce complex coefficients and a time-dependent perspective. We refer to this new system as the ”LLM Embedding Quantum System.” The main characteristics of this system were shown in [32]. This allows us to model how semantic representations evolve over time and how they respond to external influences, such as the input of new text or changes in the surrounding context. We replace the real components of |a′⟩ with complex, time-dependent coefficients cn (t) defined as

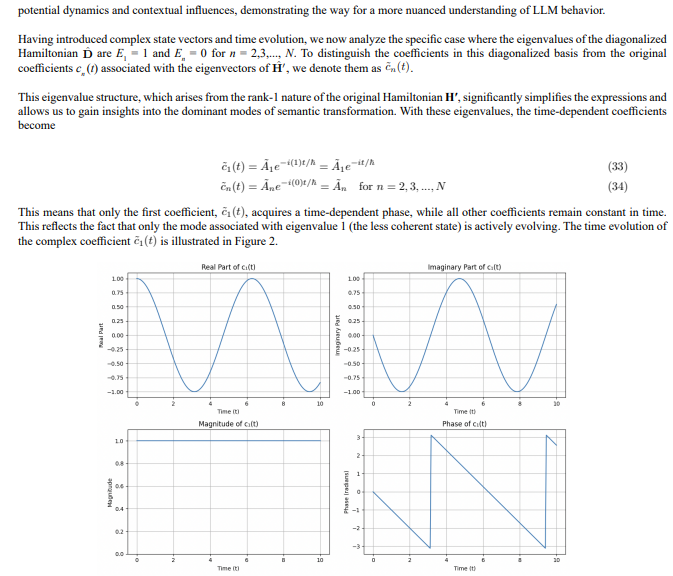
Figure 2: Time evolution of the complex coefficient c˜1(t) in the Quantum Semantic Space. The figure illustrates (a) the real part, (b) the imaginary part, (c) the magnitude, and (d) the phase of c˜1(t) as a function of time. The parameters are: amplitude A1 = 1.0 and h = 1.0.

subspace. The time evolution only affects the component in the subspace spanned by |1⟩.
In the context of LLM embedding spaces, this eigenvalue structure suggests that the semantic transformation is characterized by a single, time-evolving feature, while other features remain relatively static. This time-evolving feature, associated with Semantic Noise, allows the system to explore different semantic nuances and adapt to contextual variations. The static features represent the background context, providing a stable foundation for the dynamic transformation.
Having established the time evolution of the system, we now explore an interesting consequence of the bounded nature of the cosine similarity and the mathematical framework of the LLM: the existence of an analogue to zero-point energy. As it was shown in reference [32], this minimum allowed value can be interpreted as a zero-point energy for the LLM Embedding System.

Quantum Mechanical Average
In the LLM Embedding Quantum System, the transformed cosine similarity, denoted as S′C , provides a measure of semantic coherence, ranging from 0 to 1. Within the quantum mechanical framework, we can express the average, or expected value, of this transformed cosine similarity as

This interpretation is valid under the following assumptions:
1. Ground State Assumption: The system is assumed to be in its ground state, representing the minimum energy configuration. This implies that the observed similarity is the minimum possible similarity, and the system is trying to be as coherent as possible.
2. Transformed Basis for Interpretation: The state vector |ψ˜(t)⟩ and the Hamiltonian operator Dˆ are expressed in the transformed basis, obtained through a unitary transformation that diagonalizes the Hamiltonian. While the numerical value of the expectation value is basis-independent, this transformed basis provides the most direct and physically meaningful interpretation of the expectation value as a quantum mechanical average, particularly in relation to the ground state assumption and the quantization of semantic similarity.
Under these assumptions, the quantum mechanical approach provides a new perspective on the nature of semantic similarity. Instead of a precise, deterministic value, we obtain an average value that reflects the underlying quantum mechanical uncertainty and the probabilistic nature of semantic representations. This perspective suggests that the classical cosine similarity should be interpreted as a statistical average of an underlying quantum mechanical observable, highlighting quantum methods to provide a more nuanced understanding of LLM embedding spaces.
In our previous work, we speculated that cosine similarity should be interpreted as an average measure, even without a concrete theoretical justification [31]. The LLM Embedding Quantum System now provides a theoretical foundation for this speculation, demonstrating that the quantum mechanical analogue naturally leads to an interpretation of cosine similarity as an expectation value. This connection strengthens the validity of the quantum approach for analyzing LLM representations.
Model Quantization
A significant implication of the LLM Embedding Quantum System is the fundamental quantization of the transformed cosine similarity, S'C . This quantization arises directly from the quantum mechanical nature of the system and the discrete energy levels associated with the Hamiltonian operator.
In quantum mechanics, physical observables are often quantized, meaning they can only take on specific, discrete values. Within the LLM Embedding Quantum System, the transformed cosine similarity, S′C , is related to the expectation value of the Hamiltonian operator, Dˆ , which represents the total energy of the system. The diagonalized Hamiltonian, Dˆ , possesses discrete eigenvalues (1 and 0), implying that the energy of the system can only exist at certain quantized levels.
Since S'C is directly linked to the quantized energy levels of the system, it follows that S'C itself must also be quantized. This means that S'C cannot take on arbitrary continuous values but is restricted to a discrete set of values determined by the underlying quantum mechanical structure. This quantization is most readily apparent when considering the ground state of the system. In the ground state, the system occupies its minimum energy configuration, and S'C assumes its minimum possible value, the zero-point energy (EZP). However, even in higher energy states, where the system exists as a superposition of eigenstates, the underlying quantization of energy levels dictates that can only take on discrete values consistent with these allowed energy levels.
In [29] we observed in numerical experiments on the classical cosine similarity, SC, a tendency for it to assume distinct, discrete values, suggesting a form of discretization. In [32], we demonstrated that the embedding space exhibits discrete values along specific dimensions; however, we were only able to demonstrate a few. Now, using the LLM Embedding Quantum System, we can provide a theoretical explanation for this discretization: the transformed cosine similarity, S'C , and consequently, the original cosine similarity, SC, is fundamentally quantized. This represents a major advance, as it provides a concrete example where a quantum mechanical framework can explain the discretization phenomenon observed in a classical system. This success provides strong evidence that the quantum mechanical approach offers a valuable andÃÃÃÃÃÃÃÂ???????? insightful perspective on the nature of LLM embeddings.
Superposition of Embedding Vectors
One of the key insights is that calculating cosine similarity in an LLM embedding space can be viewed as analogous to performing a measurement on a quantum system that exists in a superposition of states. Crucially, this implies that the embedding vectors a and b themselves can be considered as basis states within a larger quantum state space. The quantum state of the system, representing a semantic concept that combines aspects of both a and b, is then a superposition of these basis states:

offers a framework for understanding how LLMs represent and process semantic relationships.
Summary of The LLM Embedding Quantum System
Remarkably, we have demonstrated that starting from a classical LLM Embedding System, where all variables are real-valued, we can construct an exact quantum mechanical analogue. This ”exactness” signifies that the quantum system models the same phenomena and exhibits the same underlying ”physics” as the classical system. Even though the state vectors in the quantum system are complex, their magnitudes (|ψ|) are preserved, mirroring the behavior of the LLM Embedding System. This analogue exhibits key quantum features, including zero-point energy and a natural interpretation of superposition. A crucial implication of this quantum analogue is that semantic similarity, as measured by the transformed cosine similarity S'C , is fundamentally quantized, meaning it can only take on certain discrete values. This suggests that classical calculations of S'C , which yield continuous floating-point values, should be interpreted as statistical averages of these underlying quantized levels.
While the underlying systems are distinct, their behavior is mathematically equivalent, allowing us to leverage the tools and concepts of quantum mechanics to analyze the dynamics of the LLM Embedding System. This equivalence provides a powerful justification for our quantum approach, suggesting that insights gained from studying the quantum analogue may offer valid perspectives on the behavior and limitations of LLMs. Of particular interest is the fact that this quantum model enables us to use a quantum computer to probe and analyze the linear embedding space. This will be discussed in later sections.
Semantic Noise and Dynamic Distribution of Uncertainty
Within the LLM Embedding Quantum System, ”Semantic Noise” is defined as the inherent uncertainty and potential for deviation from perfect coherence in semantic representations. It’s a dynamic distribution of uncertainty across different energy levels, enabling creativity, adaptation, and contextual sensitivity. As visualized in Figure 3, the distribution of semantic charge density provides a way to understand and quantify this inherent uncertainty.
Unlike a classical system where semantic meaning can be represented with precise, deterministic values, the quantum mechanical analogue introduces an inherent level of uncertainty. This uncertainty is a fundamental characteristic of the system, reflecting the inherent ambiguity and context-dependence of language.
Semantic Noise exists as a distribution across all possible energy levels, with varying probabilities of occupying coherent and less coherent states. The ground state represents the minimum possible Semantic Noise, reflecting the system’s tendency towards coherence. Excited states, on the other hand, are characterized by higher levels of Semantic Noise and a greater probability of occupying the less coherent state. This dynamic distribution of uncertainty allows the LLM to explore a wider range of semantic interpretations, generate new ideas, and adapt to new information or changing contexts.
The level of Semantic Noise is influenced by external factors. A stable and well-defined context can suppress Semantic Noise, promoting coherence and reducing ambiguity. Conversely, a rapidly changing or ambiguous context can increase Semantic Noise, leading to a wider exploration of semantic possibilities. This contextual sensitivity allows the LLM to adapt its representations to the specific demands of the task at hand.
In summary, Semantic Noise is a dynamic and multifaceted concept within the LLM Embedding Quantum System. It’s a crucial element that enables creativity, adaptation, and contextual sensitivity, manifesting as a distribution of uncertainty across different energy levels and reflecting the inherent ambiguity and probabilistic nature of semantic meaning. Understanding and controlling Semantic Noise is essential for developing more robust, reliable, and creative Large Language Models.
Conservation of Semantic Noise and Local U(1) Symmetry
In quantum mechanics, local symmetries are fundamental, often corresponding to conserved quantities that can be measured and observed. When investigating the dynamics of semantic representations in LLMs, it is natural to ask whether there exists an analogous conserved quantity that influences the system’s ability to manage Semantic Noise and maintain a stable phase relationship. To address this, we explore a quantum mechanical framework based on local symmetries and conserved quantities, concepts that are not typically considered in classical approaches to natural language processing. We propose that local U(1) symmetry, one of the simplest and most important symmetries in physics (related to the conservation of a quantity analogous to electric charge), provides a useful framework for modeling the dynamics of Semantic Noise in LLMs. The conservation of this ”semantic charge” could then be related to the LLM’s ability to balance coherence and exploration. The key takeaway is that imposing U(1) symmetry on the LLM model leads to the conservation of semantic charge, providing a mechanism for controlling the contextual sensitivity of Semantic Noise.

Figure 3: Simplified representation of semantic charge density in the LLM Embedding Quantum System. The plot shows the distribution of semantic charge across a one-dimensional semantic space, illustrating the inherent uncertainty and potential for deviation from perfect coherence. The shape of the distribution, in this case a Gaussian, reflects the relative probabilities of different semantic states, with higher charge density indicating a greater likelihood of occupying that state. The parameters are: center = 0.0 and width = 1.0.

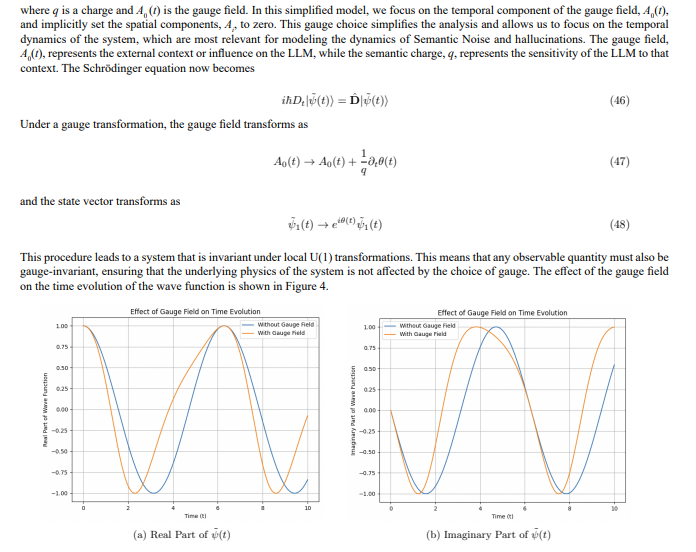
Figure 4: Effect of the gauge field on the time evolution of a simple wave function. (a) shows the real part of ψ˜(t) with and without the gauge field, and (b) shows the imaginary part of ψ˜(t) with and without the gauge field. The parameters are: charge q = 1.0, gauge field amplitude A0 = 0.5, and wave function frequency ω = 1.0.





Projecting this quantum system with U(1) symmetry onto the classical LLM Embedding System reveals that the classical system appears unchanged only when considering gauge-invariant observables like semantic coherence (S'C ). This is because the projection discards phase information, which, though not directly observable classically, provides a more complete representation by capturing the internal quantum representation of semantic states and influencing dynamics. This is akin to electric/magnetic potentials in electromagnetism: they are not directly observable, but they determine the forces.
The gauge field, A0(t), represents external influences or context, such as prompts. While cosine similarity (S'C ) can change with context due to shifts in semantic state probabilities, gauge invariance ensures that the relative amplitudes between these states, as encoded in the quantum system, are preserved, maintaining semantic charge conservation. The covariant derivative, Dt, describes the system’s response to context while upholding U(1) symmetry, analogous to how external electric fields influence charged particles while adhering to electromagnetic laws.
Although U(1) symmetry in the Quantum Semantic Space (Layer 2) aligns with observations in the LLM Embedding System (Layer 1) when focusing on gauge-invariant observables like cosine similarity, the quantum framework provides crucial insights that enrich our understanding of the classical model and its limitations. It reveals that classical analysis, relying solely on metrics like cosine similarity, may overlook key aspects of semantic representation, such as phase information encoded in the quantum state, which influences the system’s dynamics and the management of Semantic Noise.
The quantum model guides the design of features for the classical model, such as semantic charge density, enhancing its predictive power. The framework allows us to model and analyze the contextual sensitivity of LLMs through the gauge field, providing a means to understand and control how context influences both semantic coherence and the level of Semantic Noise.
Hallucinations: Time-Independent Model
Another well-studied and characteristic quantum mechanical phenomenon is quantum tunneling, where a particle can pass through a potential barrier even if it doesn’t have enough energy to overcome it classically. Given the tendency of LLM systems to sometimes provide contextually false information, known as hallucinations, we now explore the potential for modeling this behavior using the concept of quantum tunneling within our Layer 2 framework, Quantum Semantic Space. By treating the discrete embedding space with quantum mechanical methodologies, we aim to provide an explanation for the source of incorrect information and to explore where this approach leads.
In this section, we primarily focus on transitions between the state associated with higher Semantic Noise, represented by the eigenvector corresponding to eigenvalue 1, and the more coherent states, represented by eigenvectors corresponding to eigenvalue 0. This framework allows us to model how the LLM can transition from a state where the dominant semantic interpretation is coherent to a state where the dominant semantic interpretation allows for greater exploration of alternative meanings, offering a potential explanation for the phenomenon of hallucinations as a result of over-exploration or instability.
We begin with the simplest approach: a time-independent two-level Hamiltonian, representing a static system where the energy levels and coupling are constant. While this time-independent model is a significant simplification of the complex dynamics of LLM embedding spaces, it provides a useful starting point for understanding the basic concept of tunneling between two semantic states and serves as a baseline for comparison with the more realistic time-dependent model presented later in this section. We represent the LLM’s semantic states as a two-level quantum system, as shown in Figure 5. The figure highlights the energy difference and coupling strength, parameters that influence the probability of quantum tunneling between coherent states and states associated with higher Semantic Noise, ultimately contributing to the generation of hallucinations.
Recall that our LLM Quantum System is characterized by a diagonalized Hamiltonian Dˆ operating in an N dimensional space, with one eigenvector corresponding to eigenvalue 1 (the state associated with higher Semantic Noise) and N-1 eigenvectors corresponding to eigenvalue 0 (the coherent states). To explore the potential for tunneling between a specific coherent state and the state associated with higher Semantic Noise, we project this N-dimensional system onto a two-dimensional subspace.


Figure 5: Simplified model of semantic states in an LLM, represented as a two-level quantum system. The figure shows the energy levels of the coherent state |0⟩ and the state associated with higher Semantic Noise |1⟩, separated by an energy difference ω0, and the coupling strength - that enables transitions between these states via quantum tunneling. This tunneling process provides a potential mechanism for understanding the generation of hallucinations in LLMs.


Hallucinations: Landau-Zener System
To move towards a more realistic model, we introduce a dynamic element: the changing context, using a timedependent Hamiltonian. The goal is to explore how the rate of change of context influences the likelihood of tunneling and hallucinations. We will focus on the Landau-Zener model as an example because it provides a well-understood framework for analyzing transitions between states in time¬dependent two-level systems [34–36]. It is important to note that the ”time” variable in this context does not represent real-world time, but rather a parameter that describes the progression of the LLM’s internal thought process as it formulates its response. The range from negative infinity to positive infinity represents the entire process of the LLM ”thinking” about the prompt, from initial understanding to final output.
As with the time-independent case, we are projecting the dynamics of the full N-dimensional system, described by the diagonalized Hamiltonian Dˆ , onto a two-dimensional subspace. This subspace is again spanned by the eigenvector corresponding to eigenvalue 1 (the state associated with higher Semantic Noise, |1⟩) and a specific eigenvector corresponding to eigenvalue 0 (a coherent state, |0i⟩). However, in this case, the Hamiltonian itself is time-dependent, reflecting the influence of the changing context. The Hamiltonian of the Landau-Zener system is as follows



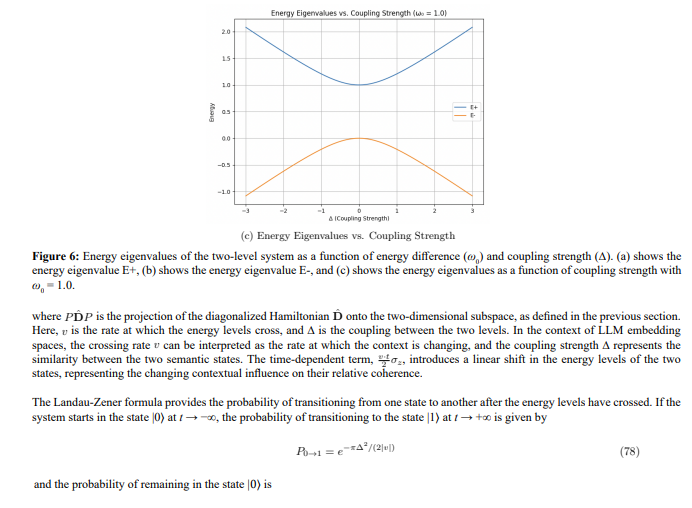
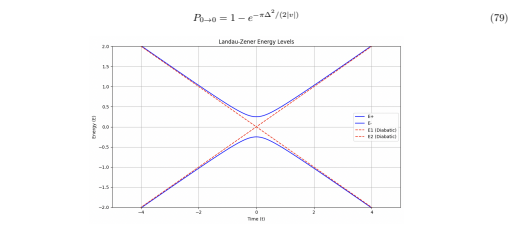
Figure 7: Energy levels of a Landau-Zener two-level system, illustrating a model for LLM hallucinations. The dashed red lines represent the diabatic energy levels, E1 and E2, which correspond to the energies of two distinct semantic states (e.g., a coherent and a state associated with higher Semantic Noise interpretation) if there were no coupling between them. The solid blue lines represent the adiabatic energy levels, E+ and E−, which are the actual energy eigenvalues of the system, taking into account the coupling strength![]() between the states. The avoided crossing at t = 0, where the energy levels approach but do not intersect, illustrates the quantum mechanical phenomenon of tunneling. In the context of LLMs, this tunneling represents the LLM transitioning from one semantic state to another (e.g., from a correct to an incorrect interpretation) even though there is a semantic ”barrier” or logical inconsistency. The rate at which the energy levels cross, v, corresponds to the rate at which the context is changing, influencing the probability of tunneling and, consequently, the likelihood of hallucinations
between the states. The avoided crossing at t = 0, where the energy levels approach but do not intersect, illustrates the quantum mechanical phenomenon of tunneling. In the context of LLMs, this tunneling represents the LLM transitioning from one semantic state to another (e.g., from a correct to an incorrect interpretation) even though there is a semantic ”barrier” or logical inconsistency. The rate at which the energy levels cross, v, corresponds to the rate at which the context is changing, influencing the probability of tunneling and, consequently, the likelihood of hallucinations
The Landau-Zener energy levels are shown in Figure 7. These formulas have important implications for LLM hallucinations. In the context of the LLM Embedding System, these results suggest that hallucinations are more likely to occur due to two key factors: A high degree of overlap between the coherent and states associated with higher Semantic Noise (low ![]() ) allows the LLM to more easily transition to the state associated with higher Semantic Noise. This overlap could be due to genuine semantic similarity, or it could be due to Semantic Noise or distortion in the semantic representation. A rapidly changing context (high v) increases the probability of transitioning to the state associated with higher Semantic Noise, especially if there is a significant overlap between the states. This suggests that hallucinations are more likely to occur when the context is unstable and the LLM is unable to maintain a clear and well-defined semantic representation.
) allows the LLM to more easily transition to the state associated with higher Semantic Noise. This overlap could be due to genuine semantic similarity, or it could be due to Semantic Noise or distortion in the semantic representation. A rapidly changing context (high v) increases the probability of transitioning to the state associated with higher Semantic Noise, especially if there is a significant overlap between the states. This suggests that hallucinations are more likely to occur when the context is unstable and the LLM is unable to maintain a clear and well-defined semantic representation.
In summary, we have explored the potential for quantum tunneling to provide a perspective on the phenomenon of hallucinations in Large Language Models. This analysis focuses on transitions between a specific coherent state and the state associated with higher Semantic Noise. While this analogy is not without its limitations, particularly in the absence of a direct physical correspondence, we believe that it offers a valuable framework for understanding how LLMs can sometimes jump to unexpected or nonsensical conclusions, generating outputs that deviate from factual or semantic coherence, due to an overemphasis on exploration driven by Semantic Noise. Note that the following analysis is performed within a simplified two-dimensional subspace of the full eigenspace. This projection allows us to apply the Landau-Zener model and gain insights into the potential for transitions between coherent and states associated with higher Semantic Noise, but it also involves a significant approximation of the complex dynamics of the LLM embedding space. While the Landau-Zener model is applied in this projected eigenspace, we interpret the parameters and results in terms of the original LLM Embedding System, drawing an analogy between the rate of change of context and the crossing rate (v) and between the similarity of semantic states and the coupling strength (![]() ).
).
Excited State Dynamics
While the ground state of the LLM Embedding Quantum System provides valuable insights into the minimum energy configuration and the system’s baseline level of Semantic Noise, exploring excited states allows us to delve deeper into the dynamic behavior and potential for more complex semantic representations within Large Language Models, revealing how the system manages and utilizes Semantic Noise. To achieve excited states within this framework, we must relax the assumption that the system is solely in its ground state. This implies that the system exists as a superposition of eigenstates, with non-zero probabilities for occupying states beyond the minimum energy configuration. Given the diagonalized Hamiltonian, Dˆ , with eigenvalues 1 (corresponding to the state associated with higher Semantic Noise) and 0 (corresponding to the more coherent states), the time-dependent Schrödinger equation governs the evolution of the system

Layer 3: Quantum Semantic Space (Nonlinear Dynamics)
To move beyond the limitations of linear dynamics and capture the more complex and nuanced behaviors inherent in LLMs, we now introduce nonlinear interactions into the semantic space. In this section, we will be working with transformed fields, as described in previous sections. To simplify the notation and improve readability, we will omit the tildes on the field variables, but it is understood that these variables are expressed in the transformed basis. Layer 3 involves considering two complementary approaches: directly incorporating nonlinearities into the Schrödinger equation or employing the path integral formalism, which will be discussed in the following subsections.
Introducing Nonlinear Interactions
To further enhance the model and capture the inherent nonlinearities of LLMs, we now introduce nonlinear interactions into the semantic space. This involves replacing the linear Schrödinger equation with a nonlinear Schrödinger equation

While the introduction of nonlinear interactions into the Schrödinger equation makes it significantly more difficult to obtain analytical solutions, it opens up paths for understanding the complex dynamics of LLMs. Qualitative analysis reveals the potential for soliton solutions, representing stable semantic representations, and self-focusing/defocusing effects, reflecting the LLM’s tendency to concentrate or diversify its attention. Numerical simulations can provide valuable insights into the behavior of the wave function, while perturbation theory can offer approximations for weak nonlinearities.
Soliton Solutions and Semantic Stability
One of the most intriguing features of nonlinear Schrödinger equations is the existence of soliton solutions. A soliton is a self-sustaining wave packet that maintains its shape and speed as it propagates through a medium, arising from a balance between dispersive and nonlinear effects. In the context of our LLM Quantum System, a soliton solution to the nonlinear Schrödinger equation would represent a particular form of the wave function ψ(t,x).


Figure 8: Simplified energy landscape of the LLM Embedding Quantum System, visualized using a Mexican hat potential. The parameters are µ = 1.25 and λ = 0.03, representing the mass parameter and coupling strength, respectively. The plot shows a cross-section of the potential energy surface as a function of two semantic features, illustrating a central peak surrounded by a region of lower energy, characteristic of the Mexican hat potential. This shape suggests the existence of preferred semantic states away from the origin, corresponding to stable and distinct semantic representations within the LLM.
This solution has the following characteristics:
• Localized: The wave function is concentrated in a specific region of the semantic space, indicating a focused semantic representation.
• Stable: The wave function maintains its shape and amplitude over time, suggesting robustness against decay or disruption.
• Propagating (Semantic Evolution): The wave function might propagate through the semantic space, representing a controlled evolution of the semantic concept.
The potential applications of soliton solutions in understanding LLM behavior are manifold:
• Stable Semantic Representation: Solitons could represent stable and coherent semantic representations within the LLM, indicating a clear and well-defined understanding of a particular concept or idea that is resistant to change. For example, in a well-written summary, the core theme could be represented by a soliton, maintaining its integrity throughout the text. This stability is achieved despite the presence of Semantic Noise, highlighting the robustness of these representations.
• Robustness to Semantic Noise: The stability of solitons suggests robustness to Semantic Noise or perturbations, enabling the LLM to maintain its coherent semantic representation even in the presence of irrelevant or contradictory information. This could explain why LLMs can often understand the meaning of a sentence even if it contains typos or grammatical errors, as the soliton structure helps filter out the noise.
• Resistance to Semantic Drift: The maintenance of shape and amplitude over time implies resistance to semantic drift, reducing the likelihood of the LLM subtly shifting its topic or perspective during a conversation. This could be observed in a chatbot that consistently adheres to the user’s intended topic, even when presented with slightly tangential prompts.
• Propagation as Semantic Evolution: If the soliton is propagating through the semantic space, this could represent the controlled evolution of a semantic concept over time, modeling how the LLM develops a line of reasoning or tells a story. This might be seen in how an LLM constructs a logical argument, building upon previous statements to reach a conclusion.
• Nonlinearity as Semantic Reinforcement: The emergence of solitons in nonlinear systems suggests that the LLM’s ability to form stable semantic representations depends on nonlinear interactions within its internal state, related to the LLM’s tendency to reinforce its own beliefs or biases. This could contribute to the phenomenon of confirmation bias, where LLMs tend to favor information that confirms their existing beliefs.
It is important to acknowledge that this interpretation is largely qualitative and that further research is needed to validate these connections empirically. However, the concept of soliton solutions provides a valuable framework for thinking about the stability and coherence of semantic representations in LLMs.

From Quantum Partition Function to Lagrangian Density
In this section, we aim to develop a field-theoretic description of the LLM Embedding System by deriving a Lagrangian density from the quantum partition function. This framework allows us to capture the dynamics of the semantic field and to explore the effects of nonlinear interactions and gauge invariance in a more general and powerful setting. The idea was originally presented in [29], but we re-derive the same result starting from a quantum mechanical partition function. This demonstrates two things: it shows the consistency of different methodologies, and also, vice versa, that the quantum partition function alone is a useful tool when analyzing LLM embedding spaces. This derivation extends our previous work by introducing a mode-dependent semantic charge (q → qi), allowing for a richer and more nuanced representation of the system compared to the global charge used in [29]. While the following derivation is mathematically involved, the key takeaway is the emergence of a non-local interaction term in the effective Lagrangian, which may be crucial for understanding long-range dependencies in LLMs. It is important to note that in our earlier work, the U(1) symmetry was imposed as a postulate to ensure stability, and the path integral formalism revealed a non-local interaction term [29].


(a) Intensity profile, |ψ(x, y, t)|2 (b) Real part, Re[ψ(x, y, t)]




Introduction of Gauge Field and U(1) Symmetry
To manage the contextual sensitivity of semantic uncertainty and prevent the arbitrary creation or destruction of influenceable Semantic Noise, we impose a U(1) symmetry, guaranteeing the conservation of semantic charge. To implement this, we introduce a gauge field, Aµ(t, â??x), and modify the derivatives to covariant derivatives. We also decompose the field into modes



Gauge Fixing and Generating Functional
To remove the gauge freedom, we choose the Coulomb gauge

As demonstrated in [29], the effective Lagrangian, derived in the weak coupling approximation, governs the dynamics of the ψ field, incorporating the influence of integrated-out fields up to quadratic order. This framework reveals a non-local interaction, mediated by the Green’s function, where the semantic meaning at one location in semantic space directly affects the meaning at distant locations. This non-locality may underlie the capacity of LLMs, particularly the Transformer architecture with its attention mechanism, to model long¬range dependencies in text. Furthermore, this non-local interaction bears a conceptual resemblance to quantum entanglement, suggesting a possible connection between the LLM’s ability to capture semantic relationships and fundamental quantum mechanical phenomena.
Semantic Charge, Gauge Field, and Nonlinear Potential
Having derived the gauge-invariant Lagrangian, we now turn to interpreting the key elements of this formalism in the context of LLMs. These elements, namely the semantic charge, the gauge field, and the nonlinear potential, provide a powerful framework for understanding how context and nonlinearity shape the dynamics of semantic representations and influence the level of Semantic Noise within the system.
The semantic charge, qi, quantifies the sensitivity of the phase of the mode associated with Semantic Noise to contextual influences. It determines how strongly the linear dynamics of a particular mode interact with the gauge field. A higher semantic charge indicates a greater susceptibility to contextual modulation of the phase, influencing the system’s tendency to explore alternative semantic interpretations. For example, a word with a high semantic charge might be more sensitive to the surrounding words in a sentence, exhibiting greater contextual flexibility, while a word with a low semantic charge might retain its meaning regardless of the context, exhibiting greater semantic stability.
The gauge field, Aµ = (A0, Ai), represents the influence of context on the phase of the mode associated with Semantic Noise. The temporal component, A0, acts as a semantic force that shapes the evolution of the phase over time, influencing the system’s balance between coherence and exploration. The spatial components, Ai, may be interpreted as representing the flow of semantic information through the embedding space, with their direction and magnitude indicating the strength and direction of the flow. This context could be a prompt, the surrounding text, or external knowledge.
The nonlinear potential, VNL, introduced in Layer 3, captures the nonlinear interactions and feedback loops that are characteristic of LLMs. It allows the semantic wave function to interact with itself, leading to more complex and realistic dynamics that go beyond the linear approximations of Layer 2. The specific form of the nonlinear potential (e.g., cubic nonlinearity or Mexican hat potential) determines the nature of these interactions. For example, a cubic nonlinearity could model the reinforcement of biases, while a Mexican hat potential might promote semantic stability by providing a preferred state.
The interplay between the semantic charge, the gauge field, and the nonlinear potential determines the overall behavior of the LLM Embedding System. The semantic charge governs the sensitivity of the phase of the mode associated with Semantic Noise to context, the gauge field represents the context itself (both its temporal influence and its spatial flow), and the nonlinear potential shapes the dynamics of the semantic representation. By analyzing these elements, we can gain a deeper understanding of how LLMs process and generate language, balancing coherence with the exploration of new semantic possibilities.
Layers 4-N: Advanced Quantum Hierarchies
While Layers 1, 2, and 3 provide a foundation for understanding LLM representations, the quantum framework allows for the possibility of even more advanced and complex hierarchies. These possible layers, which we denote as Layers 4-N, can capture aspects of LLM behavior that are beyond the reach of the simpler models.
One intriguing possibility is to model the dynamic creation and annihilation of semantic content within the LLM. This can be particularly relevant for understanding how LLMs learn new information, forget old information, or generate new ideas. In such cases, theoretical frameworks like Quantum Field Theory (QFT), which describes the creation and annihilation of particles, might offer advanced tools. QFT introduces the concept of quantum fields that permeate all of space, and particles are seen as excitations of these fields. Analogously, we can think of a semantic field that underlies the LLM’s embedding space, with words and concepts representing excitations of this field. The creation and annihilation operators in QFT can then be used to model the dynamic addition and removal of semantic content. For example, the concept of ’semantic charge’ introduced in Layer 2 can be further explored using QFT’s charge conservation laws, providing insights into how LLMs manage Semantic Noise and balance coherence with exploration in their generated text.
Another speculative direction is to investigate the potential for emergent, string-like structures within the LLM’s embedding space. This idea draws inspiration from Quantum String Theory, which proposes that fundamental particles are not point-like but rather tiny, vibrating strings. In the context of LLMs, we could think that semantic relationships are not simply point-to-point connections but rather more complex, string-like objects that encode richer information about the relationships between concepts. The Transformer architecture space is likely to exhibit singularities, sinks, and wells, which are concepts from QFT and String Theory. These can be interpreted as regions where semantic content is either created (sources) or destroyed (sinks), or as points of instability in the semantic landscape. However, even if String Theory appears distinct at the moment, it is a very powerful mathematical toolbox that has been applied in particle physics, condensed matter physics, nuclear physics, and many other areas. Even if a direct physical connection to String Theory remains elusive, the mathematical tools developed within that framework can offer valuable techniques for analyzing the complex structure of the LLM embedding space.
It is crucial to emphasize that at the moment these are speculative ideas, and a direct mapping to LLM representations is not clear. Also, the mathematical complexity of QFT and String Theory is considerable. However, if such mappings could be rigorously established, LLMs might even offer a new domain for exploring theoretical concepts from these advanced frameworks, providing empirical insights into areas of physics where direct observation is currently very difficult. However, at this stage, these connections remain largely at the level of analogy and inspiration.
Layers 4-N: Advanced Quantum Hierarchies
While Layers 1, 2, and 3 provide a foundation for understanding LLM representations, the quantum framework allows for the possibility of even more advanced and complex hierarchies. These possible layers, which we denote as Layers 4-N, can capture aspects of LLM behavior that are beyond the reach of the simpler models.
One intriguing possibility is to model the dynamic creation and annihilation of semantic content within the LLM. This can be particularly relevant for understanding how LLMs learn new information, forget old information, or generate new ideas. In such cases, theoretical frameworks like Quantum Field Theory (QFT), which describes the creation and annihilation of particles, might offer advanced tools. QFT introduces the concept of quantum fields that permeate all of space, and particles are seen as excitations of these fields. Analogously, we can think of a semantic field that underlies the LLM’s embedding space, with words and concepts representing excitations of this field. The creation and annihilation operators in QFT can then be used to model the dynamic addition and removal of semantic content. For example, the concept of ’semantic charge’ introduced in Layer 2 can be further explored using QFT’s charge conservation laws, providing insights into how LLMs manage Semantic Noise and balance coherence with exploration in their generated text.
Another speculative direction is to investigate the potential for emergent, string-like structures within the LLM’s embedding space. This idea draws inspiration from Quantum String Theory, which proposes that fundamental particles are not point-like but rather tiny, vibrating strings. In the context of LLMs, we could think that semantic relationships are not simply point-to-point connections but rather more complex, string-like objects that encode richer information about the relationships between concepts. The Transformer architecture space is likely to exhibit singularities, sinks, and wells, which are concepts from QFT and String Theory. These can be interpreted as regions where semantic content is either created (sources) or destroyed (sinks), or as points of instability in the semantic landscape. However, even if String Theory appears distinct at the moment, it is a very powerful mathematical toolbox that has been applied in particle physics, condensed matter physics, nuclear physics, and many other areas. Even if a direct physical connection to String Theory remains elusive, the mathematical tools developed within that framework can offer valuable techniques for analyzing the complex structure of the LLM embedding space.
It is crucial to emphasize that at the moment these are speculative ideas, and a direct mapping to LLM representations is not clear. Also, the mathematical complexity of QFT and String Theory is considerable. However, if such mappings could be rigorously established, LLMs might even offer a new domain for exploring theoretical concepts from these advanced frameworks, providing empirical insights into areas of physics where direct observation is currently very difficult. However, at this stage, these connections remain largely at the level of analogy and inspiration.
Layer N+1: Transformer Architecture (Common LLM Architecture)
The Transformer architecture, introduced by Vaswani et al., represents a significant milestone in our layered hierarchy and a major advancement in neural network design for natural language processing. Unlike recurrent neural networks (RNNs) that process sequential data step-by-step, Transformers rely entirely on attention mechanisms to model relationships between words in a sequence, enabling parallel processing and improved performance on longrange dependencies. This architecture provides a concrete realization of the complex dynamics and interactions that we have been modeling in Layers 2 and 3. The key connection to our quantum framework is that the Transformer’s attention mechanism can be interpreted as implementing a form of non-local interaction, analogous to the path integral formalism in Layer 3, where the representation of each word is influenced by all other words in the sequence, regardless of distance.
A core component of the Transformer is the self-attention mechanism. This allows the model to weigh the importance of different words in the input sequence when representing a particular word. While attention weights can be interpreted as probabilities of the LLM occupying different semantic states, it is important to note that they are not strictly probabilities in the mathematical sense, as they are not explicitly normalized to sum to one across all possible states. The attention weights are computed based on the relationships between the query, key, and value vectors derived from the input embeddings. This mechanism enables the model to capture contextual information and understand the relationships between words regardless of their distance in the sequence, effectively implementing a form of non-local interaction similar to that captured by the path integral formalism in Layer 3, whereby the representation of each word is influenced by all other words in the sequence, regardless of distance.
The Transformer architecture typically consists of an encoder and a decoder. The encoder processes the input sequence and generates a contextualized representation. The decoder then uses this representation to generate the output sequence, such as in machine translation or text summarization tasks. Both the encoder and decoder are composed of multiple layers of self-attention and feedforward networks.
Each layer in the encoder and decoder includes a multi-head attention mechanism. This allows the model to attend to different aspects of the input sequence simultaneously, capturing a richer set of relationships between words. The outputs of the multiple attention heads are then concatenated and linearly transformed to produce the final output of the layer.
Feedforward networks, typically consisting of two linear transformations with a nonlinear activation function in between, are applied to each position in the sequence independently. These networks introduce nonlinearities into the model, allowing it to learn complex relationships between semantic concepts. These nonlinearities, such as ReLU or GeLU, can be seen as analogous to the nonlinear potential VNL in Layer 3, shaping the energy landscape of the semantic space and contributing to the stability and complexity of the learned representations. The Transformer’s layers, attention mechanisms, and feedforward networks collectively define a complex energy landscape that governs the dynamics of semantic meaning, learning to shape this landscape during training to minimize a loss function while also managing the level of Semantic Noise to enable both coherence and exploration.
Residual connections and layer normalization are also key features of the Transformer architecture. Residual connections allow the model to bypass certain layers, facilitating the flow of information and preventing vanishing gradients during training. Layer normalization helps to stabilize the training process and improve the model’s generalization performance.
Layer N+2: Complex Transformer Architecture (Complex Semantic Superspace)
While most Transformer-based LLMs have historically operated with real-valued representations, recent research has explored complex-valued Transformer architectures [37–39]. These models, often referred to as complex neural networks (CVNNs), extend the standard Transformer to operate directly on data with both real and imaginary components. This approach is particularly useful in applications where data is inherently complex-valued (e.g., signal processing, medical imaging) or where leveraging both amplitude and phase information is beneficial for capturing subtle semantic relationships and contextual nuances. Architectural adaptations include complex-valued attention mechanisms, layer normalization, and feed-forward networks. Some approaches, like Quantum-Inspired Complex (QIC) Transformers, aim to improve parameter efficiency by using learnable algebraic structures for the imaginary unit. These complex-valued Transformers have shown promise in improving robustness to overfitting and achieving competitive or superior performance compared to their real-valued counterparts in certain domains.
The significance of Complex Transformers within our quantum hierarchy lies in their ability to provide a more complete and natural representation of what we term the Complex Semantic Superspace, offering new ways to understand and manage Semantic Noise within LLMs. This terminology is inspired by concepts in theoretical physics, such as Superstring Theory and Supersymmetry, where the introduction of additional dimensions and complex fields allows for a more unified and complete description of physical phenomena. In our context, the Complex Semantic Superspace represents an extension of the traditional real-valued Transformer embedding space, incorporating complex-valued representations to capture aspects of semantic meaning, such as phase and interference, that are otherwise inaccessible.
In essence, the real-valued Transformer embedding space can be seen as a projection of this more complete Complex Semantic Superspace. This projection inevitably results in a loss of information, hindering the ability to fully leverage the quantum analogy. Complex Transformers, by operating directly with complex numbers, offer a richer representation that more closely aligns with the mathematical structure of quantum mechanics, allowing us to access the full potential of the Complex Semantic Superspace.
Therefore, the quantum tools and concepts developed in this hierarchy may find a more direct, natural, and optimal application within the Complex Semantic Superspace, leading to more effective methods for controlling Semantic Noise and harnessing its benefits for creativity and adaptation. The complex-valued nature of these architectures reduces the need for approximations, compactifications, or mappings compared to their application to real-valued architectures, unlocking deeper insights into the quantum-like properties of LLMs and leading to more effective methods for analysis and control. Layer N+2, therefore, provides a more faithful representation of the underlying semantic reality within the Complex Semantic Superspace.
Linearization and Classical Limit
Having established a quantum framework for analyzing LLM representations, we now demonstrate its consistency with existing approaches by exploring the connection between this framework and the linearized LLM embedding space (Layer 1). We aim to show how the familiar properties of the embedding space can be recovered by making specific approximations to the time-dependent Schrödinger equation, effectively ”undoing” the quantum enhancements we introduced in Layers 2 and 3. This linearization provides a valuable validation of our framework and a theoretical justification for the effectiveness of linear operations in analyzing semantic representations, while also highlighting the information lost in the process. We aim to show how the static relationships between semantic concepts, as captured by cosine similarity in Layer 1, can be recovered.
Linearization of U (1) Symmetry
We first demonstrate the linearization of a quantum mechanical system with U(1) symmetry. We begin with the time-dependent Schrödinger equation with the covariant derivative


This is the eigenvalue equation for the Hamiltonian, a linear equation that relates the shifted energy of the system (due to the static gauge field) to the eigenvalues of the diagonalized Hamiltonian. The time-independent state vector |ψ| is mapped to the embedding vector a. The shifted energy of the state, E + â?ÂÃÂ?ÂÂqA0, is mapped to the semantic coherence measure S'C . The diagonalized Hamiltonian Dˆ represents the fundamental modes of the semantic space.
This linearization demonstrates that the LLM embedding space can be seen as a simplified, static version of the more complex quantum system. This version retains a static, inherent contextual influence, represented by the gauge field A0, primarily on the phase of the mode associated with Semantic Noise. The linearization process removes the time dependence, leaving only the essential linear relationships between the semantic concepts, modulated by the static gauge field. If we further set A0 to zero, we recover the original LLM Embedding System, effectively neglecting the U(1) symmetry and any inherent contextual influence on Semantic Noise.
Linearized Partition Function with Static Context
As an example of the linearization process described above, we can derive the linearized partition function. Starting from the quantum partition function with a static gauge field, and applying the approximations of a stationary state, we have

This static gauge field indirectly modulates the effects of dimensionality and temperature on semantic coherence by influencing the balance between coherence and exploration. A positive contextual bias amplifies the effect of dimensionality, promoting stronger coherence, while a negative bias counteracts it, promoting greater exploration. The static gauge field also influences few-shot learning, robustness to adversarial attacks, and the trade-off between coherence and creativity. It suggests that some hallucinations may originate from an inherent contextual bias within the LLM’s embedding space, skewing the balance between coherence and exploration. The training data likely influences both the effective temperature and the static gauge field, with consistent datasets leading to a positive A0 and noisy datasets leading to a negative A0.
Linearized Analysis of the Landau-Zener System
Next, we consider the linearization of the Landau-Zener model. To understand the long-term behavior of the system under dynamic contextual influences, we consider the limit as time approaches infinity. Here, ”time” represents the LLM’s internal processing time, and the limit as t approaches infinity corresponds to the LLM settling into its dominant semantic state after fully processing the prompt. If the system starts in the state |˜0⟩ at t → −∞, the asymptotic populations of the coherent and less coherent states are given by

Linearized Analysis of the Bright Soliton
While the linearization of the bright soliton solution inevitably sacrifices its key dynamic and nonlinear properties, we can still explore whether it provides any insights into the structure of the LLM embedding space. By ”freezing” the solution at a specific time t0 and position x0, we are essentially extracting a static snapshot of the dynamic semantic representation, effectively eliminating its time-dependent and spatial characteristics. This allows us to analyze the amplitude at a single point in the semantic space, mimicking the static nature of the linearized embedding space. We start with the transformed wave function. In the linearized limit, we drop the tilde and obtain a constant complex amplitude
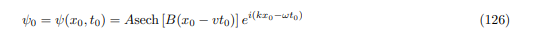
We can then express this constant amplitude as a linear combination of the eigenvectors of the diagonalized Hamiltonian Dˆ . This linear combination effectively decomposes the static amplitude into its constituent semantic components, as defined by the eigenvectors of the Hamiltonian, allowing us to analyze the contribution of each component to the overall semantic representation.
Although this linearization is highly limiting, we can speculate on potential connections to the real embedding space:
• Preferred Semantic Locations: The existence of non-zero solutions only for specific values of x0 might suggest that the real embedding space has preferred locations for localized patterns of semantic meaning, as captured by the soliton solutions, although these locations are likely distorted and simplified due to the linearization process.
• Amplitude as Semantic Salience: The magnitude of the constant amplitude, |ψ0|, might be related to the semantic salience or importance of the concept represented by the soliton.
• Phase as Semantic Context: The phase of the constant amplitude, (kx0 −ωt0), might encode some information about the semantic context, analogous to how the phase of a wave can encode information about its source or propagation history, although there is no clear way to directly map this to the real embedding space.
We may hypothesize that LLM spaces contain soliton-like solutions. However, this is a good example that clearly shows linearization is a significant simplification and we lose many internal LLM structures when doing so. This also shows that if we want to understand LLM architectures and spaces, we need more advanced tools beyond the linear embedding space, and investigate the internal structure of LLMs. The quantum framework presented in this article offers one approach for achieving this, providing a set of tools and concepts that can capture the nonlinear dynamics and complex relationships within LLMs that are lost in linear approximations.
Quantum Computation Probing LLM Embeddings
Having established the ”LLM Embedding Quantum System” as an exact quantum mechanical analogue of the classical LLM embedding space, we now explore the possibility for leveraging quantum computers to directly probe and analyze this system, pushing beyond the limitations of classical methods. The simplicity of the LLM Embedding Quantum System makes it particularly amenable to experimental investigation using existing quantum computing technology, offering a unique opportunity to validate our theoretical framework and gain new insights into the behavior of LLMs. Quantum computing offers the potential to move from modeling the ”LLM Embedding Quantum System” to directly impacting LLM development and usage in the future.
As demonstrated in previous work [31, 33], quantum computers can efficiently calculate quantities such as cosine similarity and the quantum partition function. Here, we introduce a straightforward approach for calculating cosine similarity using a simple quantum circuit.
The value

can be efficiently estimated using a quantum circuit known as the SWAP test. This test leverages quantum interference to relate the probability of measuring a specific state to the real part of the inner product between two quantum states, |a⟩ and |b⟩.
Quantum Circuit and Algorithm
The SWAP test circuit consists of three registers: one ancilla qubit initialized to |0⟩, and two registers to hold the quantum states |a⟩ and |b⟩. To represent a vector of dimension N in a quantum computer, we require n qubits, where n is the smallest integer such that 2n ≥ N. If N is not a power of 2, we must employ a technique called padding. Padding involves increasing the dimension of the vector to the next power of 2 by adding extra components with zero amplitude. For example, if we have a vector of dimension 10, we need 4 qubits (since 24 = 16). We then pad the vector with 6 zeros to make it a 16-dimensional vector. This ensures that the vector can be represented by the 4 qubits.
To illustrate how multiple qubits represent a higher-dimensional vector, consider a system of 3 qubits. The state of this system can be written as a superposition of all possible 3-qubit basis states



In other words, we run the circuit many times, sum the results (1 for each |0⟩ measurement and 0 for each |1⟩ measurement), and divide by the total number of runs to estimate P(0). We then use this estimate of P(0) to calculate the estimate of ⟨S′C ⟩. The more shots we use, the more accurate our estimate of ⟨S′C ⟩ will be.
The SWAP test provides a quantum advantage for estimating the inner product compared to classical methods, especially when dealing with high-dimensional quantum states. The accuracy of the estimate depends on the number of shots (measurements) used; more shots lead to a more accurate estimate of P(0) and, consequently, of S'C . On real quantum hardware, the SWAP test is susceptible to noise and errors, making error mitigation techniques crucial for obtaining reliable results.
Experimental Validation with LLM Embeddings
As a realistic example, we used Google’s EmbeddingGemma Sentence Transformer to calculate S′C using two vectors. EmbeddingGemma is a 300M parameter, state-of-the-art open embedding model from Google, built from Gemma 3. EmbeddingGemma produces vector representations of text, making it well-suited for search and retrieval tasks, including classification, clustering, and semantic similarity search. We used the following two sentences:
|a⟩: ”The tiny brown mouse quietly scurried across the kitchen floor, seeking crumbs.”
|b⟩: ”A small gray mouse cautiously crept along the wooden floor, searching for food.”
and calculated their 768-dimensional embedding vectors. Since 768 is not a power of 2, we padded the vectors to dimension 1024, requiring 10 qubits per vector register. Representing each 1024-dimensional vector requires preparing a complex multi-qubit state across 10 qubits. Depending on the quantum computer’s architecture and the chosen state preparation method, the initialization process may require hundreds or even thousands of CNOT gates, illustrating the significant overhead associated with preparing high-dimensional quantum states. Using Aer’s qasm simulator,, a quantum simulator with 4096 shots, we obtained the following result:

Again, we observed good agreement with the results, suggesting that the approach is also independent of the LLM embedding model that is used.
However, when testing the same approach with the 768-dimensional EmbeddingGemma vectors on a real quantum computer accessed through the IBM Quantum Cloud (IBM Quantum’s ibm fez and ibm boston backends), the results differed significantly. Instead of reflecting the semantic similarity, the SWAP test consistently yielded a P(0) value close to 0.5. This suggests that the quantum computation was overwhelmed by noise and decoherence, effectively randomizing the state of the ancilla qubit and obscuring any meaningful signal. While noise and decoherence are primary suspects, other factors could also be contributing. The initial state preparation, particularly the multiqubit initialization required for these high-dimensional vectors, is a non-trivial task and a potential source of error. The transpilation process, which optimizes the circuit for the specific quantum hardware, can also introduce errors. It’s also conceivable that the Qiskit initialization script might introduce unintended normalizations or transformations, leading to an incorrect initial state. Other initialization problems, or even a subtle programming error, cannot be entirely excluded. Ideally, we would have investigated these possibilities more thoroughly, but the prohibitively high cost and limited availability of real quantum computation resources prevented us from pursuing this line of inquiry further, including exploring error correction or noise extrapolation techniques.
While these results on publicly available quantum hardware were not as strong as theoretically predicted, it is important to note that this implementation of the SWAP test was designed to minimize the number of qubits required, a trade-off that introduced challenges in circuit state preparation and made the circuit particularly susceptible to noise and decoherence on current quantum devices. In contrast, our previous work [31, 33] explored alternative quantum circuit designs where each qubit represented a single dimension of the embedding vector. While these designs required significantly more qubits, they yielded more promising results, suggesting that the quantum approach is viable with sufficient quantum resources and more robust state preparation techniques. It is also crucial to acknowledge that the publicly available quantum hardware used in these experiments does not necessarily represent the current state of-the-art in quantum computing, and more advanced quantum devices with lower noise levels and improved gate fidelities may be able to achieve significantly better results with the SWAP test or other quantum algorithms.
These experiments highlight the challenges of applying quantum algorithms to real-world data, particularly when dealing with high-dimensional representations and noisy quantum hardware. While the SWAP test offers a theoretically appealing approach for estimating semantic similarity with a relatively small number of qubits, achieving reliable and accurate results in practice requires careful consideration of the characteristics of the input data, the limitations of current quantum hardware, and the choice of appropriate quantum algorithms and error mitigation techniques.
To improve the accuracy and reliability of quantum semantic similarity estimation, we suggest exploring the following:
• Alternative Circuit Designs: Exploring alternative quantum circuit designs for the SWAP test that are more robust to noise and better suited for representing vectors with varying degrees of sparsity. This might involve using different gate decompositions or employing error mitigation techniques.
• Quantum Dimensionality Reduction: Investigating dimensionality reduction techniques to reduce the dimension of the embedding vectors while preserving their essential semantic information. This could lead to more efficient and accurate quantum representations.
• Patch-Based Similarity Calculation: Considering embedding vectors as ”patches,” i.e., dividing long vectors into several smaller vectors (then normalizing them to 1) and performing similarity calculations in pieces. This could allow for a more localized and potentially more robust estimation of similarity.
• Improved Quantum Hardware: The development of more robust and higher-fidelity quantum hardware is essential for realizing the full potential of quantum algorithms for natural language processing.
• Exploiting Embedding Structure: Developing quantum algorithms that are specifically tailored to exploit the structure and properties of LLM embedding spaces. This might involve using different encoding schemes or designing circuits that are optimized for specific types of semantic relationships.
In conclusion, while the theoretical framework presented in this article offers a promising approach for understanding and analyzing LLM representations using quantum computing, challenges still remain in translating these ideas into practical and reliable quantum algorithms. More focus is needed to overcome these challenges and to unlock the full potential of quantum computing for natural language processing. The limitations we encountered also highlight the importance of carefully considering the characteristics of the input data and the capabilities of the available quantum hardware when designing and implementing quantum algorithms.
Applications and Emerging Research
The quantum circuit design presented here offers a direct and intuitive, albeit simplified, approach to calculating cosine similarity using a quantum computer. While our experiments revealed limitations in its ability to accurately estimate semantic similarity for complex LLM embeddings with current quantum hardware, the circuit’s simplicity provides a valuable starting point for exploring more advanced quantum algorithms.
More broadly, the existence of an exact quantum mechanical analogue, the LLM Embedding Quantum System, opens up a wide range of experimental possibilities. By modifying the quantum circuit, we could explore and test various aspects of the LLM embedding space. Some easier applications (near-term focus) that could be explored include:
• U(1) Symmetry and Contextual Control: Develop quantum-inspired methods for dynamically controlling LLM contextual sensitivity by measuring and adjusting semantic charge flow. This enables hallucination mitigation, creative text generation, and personalized LLMs. (Focus: Quantum measurement of semantic charge flow, feedback loop implementation)
• Quantum Tunneling and Hallucination Suppression: Create a quantum-inspired hallucination detection and correction mechanism by simulating quantum tunneling, identifying potential hallucinations, and using quantumassisted correction to steer LLMs towards more accurate states. (Focus: Quantum simulation of tunneling, identification of high-probability tunneling events)
• Quantum Entanglement and Semantic Understanding: Enhance LLM understanding of complex relationships by measuring entanglement between embedding dimensions and training LLMs to exploit entanglement patterns. This improves reasoning, contextual understanding, and knowledge graph construction. (Focus: Measurement of entanglement between embedding dimensions, entanglement-aware training strategies)
More ambitious research topics (long-term vision) that could significantly advance the field include, for example,
• Quantum-Enhanced Few-Shot Learning: Improve LLM few-shot learning using quantum state transfer (e.g., teleportation) to efficiently transfer knowledge from a small number of examples. Explore quantum generative models to augment limited training data. This enables rapid adaptation, personalized learning, and deployment in resource-constrained environments. (Quantum Property: Superposition and entanglement for efficient knowledge transfer and data augmentation)
• Quantum-Inspired Semantic Search: Develop a semantic search engine using quantum embedding spaces and algorithms like Grover’s algorithm or Quantum Amplitude Estimation to retrieve information based on meaning rather than keywords. This improves information retrieval, knowledge discovery, and personalized recommendations. (Quantum Property: Grover’s algorithm for speedup in unstructured search, quantum amplitude estimation for efficient probability estimation)
• Quantum-Assisted Code Generation: Enhance code generation by LLMs using quantum algorithms for code optimization (e.g., quantum annealing to find optimal code structures) and bug detection (e.g., quantum pattern matching to identify potential vulnerabilities). This automates software development, improves code quality, and reduces development costs. (Quantum Property: Quantum annealing for optimization, quantum pattern matching for efficient bug detection)
• Quantum-Enhanced Multi-Modal LLMs: Extend the quantum framework to multi-modal LLMs by using quantum algorithms to fuse information from different modalities into a unified quantum representation (e.g., quantum feature maps for modality encoding) and enable quantum cross-modal reasoning (e.g., quantum algorithms for pattern recognition across modalities). This creates more powerful AI systems and enables new applications. (Quantum Property: Quantum feature maps for efficient encoding of multi-modal data, quantum algorithms for pattern recognition and reasoning)
The ability to perform these experiments on a quantum computer provides a powerful tool for validating our theoretical framework and gaining insights into the complex dynamics of LLMs. The results of these quantum experiments can then be projected back onto the real LLM embedding system, providing a valuable bridge between the quantum and classical descriptions. This connection offers a promising path for applying quantum computing techniques to analyze, understand, and enhance the capabilities of Large Language Models.
Discussions and Conclusions
This article has presented a layered quantum hierarchy for analyzing LLM embedding spaces, bridging the gap between the simplified linearized view and the complex Transformer architecture. By drawing analogies to quantum mechanics, we have introduced concepts such as semantic charge, gauge invariance, and quantum tunneling to model phenomena like the dynamics of Semantic Noise and hallucinations. We demonstrated that a classical LLM embedding system has an exact quantum mechanical analogue, and we presented a simple quantum circuit design for calculating cosine similarity. These findings suggest that quantum methods offer a valuable perspective on LLM representations.
It is essential to remember that the validity of this analogy depends on the extent to which the mathematical structures and relationships captured by the framework correspond to meaningful phenomena in LLM behavior. The simplified models and approximations we have employed inevitably involve a loss of information, and further validations are needed to confirm these connections empirically.
Promising directions for future research include: developing methods for directly measuring ”semantic charge” in LLMs; designing experiments to detect quantum tunneling events in semantic transformations; exploring the potential for quantum algorithms to improve LLM training and inference; and investigating the application of these concepts to other areas of AI, such as computer vision and reinforcement learning.
Ultimately, understanding the underlying complexity of LLMs is crucial for unlocking their full potential and ensuring their responsible use. By embracing interdisciplinary approaches and drawing inspiration from diverse fields like quantum mechanics, we can create AI systems that are not only powerful and efficient but also fundamentally interpretable, reliable, and aligned with human values. The quantum framework presented here offers a step in this endeavor, suggesting that the seemingly disparate worlds of quantum physics and AI may be more deeply connected than we previously imagined, particularly in understanding and harnessing the power of Semantic Noise to create more intelligent and adaptable AI systems.
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need.Advances in neural information processing systems, 30.
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. International Conference on Learning Representations.
- Pennington, J., Socher, R., & Manning, C. D. (2014, October). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532-1543).
- Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A neural probabilistic language model. Journal of machine learning research, 3(Feb), 1137-1155.
- Harris, Z. (1954). Distributional Structure. Word, 10(2-3), 146-162.
- Socher, R., Huval, B., Manning, C. D., & Ng, A. Y. (2012, July). Semantic compositionality through recursive matrix-vector spaces. In Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning (pp. 1201-1211).
- Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y. J., Chen, D., Dai, W., Chan, H.S., Madotto, A., Fung, P. (2022). Survey of Hallucinations in Natural Language Generation. ACM Computing Surveys. 248, 1-38.
- Pearl, J., & Mackenzie, D. (2018). The book of why: the new science of cause and effect. Basic books.
- Shannon, C.E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal, 27(3), 379-423.
- Cover, T.M. and Thomas, J.A. (2006). Elements of Information Theory, 2nd Edition. Wiley&Sons.
- Kullback, S., & Leibler, R. A. (1951). On information and sufficiency. The annals of mathematical statistics, 22(1), 79-86.
- Lin, J. (1991). Divergence measures based on the Shannon entropy. IEEE Transactions on Information theory, 37(1), 145-151.
- Biamonte, J., Wittek, P., Pancotti, N., Rebentrost, P., Wiebe, N., & Lloyd, S. (2017). Quantum machine learning. Nature, 549(7671), 195-202.
- Arute, F., Arya, K., Babbush, R., Bacon, D., Bardin, J. C., Barends, R., ... & Martinis, J. M. (2019). Quantum supremacy using aprogrammable superconducting processor. Nature, 574(7779), 505-510.
- Grover, L. K. (1996, July). A fast quantum mechanical algorithm for database search. In Proceedings of the twenty-eighth annual ACM symposium on Theory of computing (pp. 212-219).
- Shor, P. W. (1994, November). Algorithms for quantum computation: discrete logarithms and factoring. In Proceedings 35th annual symposium on foundations of computer science (pp. 124-134). Ieee.
- Benedetti, M., Lloyd, E., Sack, S., & Fiorentini, M. (2019). Parameterized quantum circuits as machine learning models. Quantum science and technology, 4(4), 043001.
- DiVincenzo, D. P. (2000). The physical implementation of quantum computation. Fortschritte der Physik: Progress of Physics, 48(9â?11), 771-783.
- HavlíÄek, V., Córcoles, A. D., Temme, K., Harrow, A. W., Kandala, A., Chow, J. M., & Gambetta, J. M. (2019). Supervised learningwith quantum-enhanced feature spaces. Nature, 567(7747), 209-212.
- Beer, K., Bondarenko, D., Farrelly, T., Osborne, T. J., Salzmann, R., Scheiermann, D., & Wolf, R. (2020). Training deep quantumneural networks. Nature communications, 11(1), 808.
- Nielsen, M. A., & Chuang, I. L. (2010). Quantum computation and quantum information. Cambridge university press.
- Khrennikov, A. (2010). Ubiquitous quantum structure: From Psychology to Finance. Springer.
- Kim, S. H., Mei, J., Girotto, C., Yamada, M., & Roetteler, M. (2025). Quantum Large Language Model Fine-Tuning. arXiv preprint arXiv:2504.08732.
- Coldenfeld, N. (1994). Lectures on Phase Transitions and The Renormalization Group, Addison-Wesley.
- Huang, K. (1987). Statistical Mechanics, 2nd Edition. John Wiley & Sons.
- Pathria, R. K. (1996). Statistical Mechanics 2nd ed. Butterworth-Heinemann.
- Egelstaff, P.A. (1994). Liquids: Structure, Dynamics and General Properties. Taylor & Francis.
- Feynman, R.P., & Hibbs, A.R. (1965). Quantum Mechanics and Path Integrals. McGraw-Hill.
- Laine, T. A. (2025). Semantic Wave Functions: Exploring Meaning in Large Language Models Through Quantum Formalism. OAJ Applied Sci Technol, 3(1), 01-22.
- Laine, T. A. (2025). The Quantum LLM: Modeling Semantic Spaces with Quantum Principles. OA J Applied Sci Technol, 3(2), 01-13.
- Laine, T. A. (2026). Quantum LLMs Using Quantum Computing to Analyze and Process Semantic Information. OA J Applied Sci Technol, 4(1), 01-19.
- Laine, T. A. (2026). Discrete Semantic States and Hamiltonian Dynamics in LLM Embedding Spaces. OA J Applied Sci Technol, 4(1), 01-23.
- Laine, T. A. (2026). Quantum Computation of Partition Function Similarity for Large Language Models. OA J Applied Sci Technol, 4(1), 01-11
- Zener, C. (1932). Non-adiabatic crossing of energy levels. Proceedings of the Royal Society of London. Series A, Containing Papers of a Mathematical and Physical Character, 137(833), 696-702.
- Landau, L. (1932). Zur theorie der energieubertragung. II. Physikalische Zeitschrift der Sowjetunion, 2, 46.
- Wittig, C. (2005). The landau− zener formula. The Journal of Physical Chemistry B, 109(17), 8428-8430.
- Yang, M., Ma, M. Q., Li, D., Tsai, Y. H. H., & Salakhutdinov, R. (2020, May). Complex transformer: A framework for modeling complex-valued sequence. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 4232-4236). IEEE.
- Eilers, F., & Jiang, X. (2023, June). Building blocks for a complex-valued transformer architecture. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1-5). IEEE.
- Huang, E., Zhang, Z., Xu, T., Xia, C., Hu, K., Yang, Y., ... & Qin, Z. (2025). Holographic Transformers for Complex-Valued Signal Processing: Integrating Phase Interference into Self-Attention. arXiv preprint arXiv:2509.19331.