
Open Access Journal of Applied Science and Technology(OAJAST)
ISSN: 2993-5377 | DOI: 10.33140/OAJAST
Impact Factor: 1.08


Short Communication - (2026) Volume 4, Issue 1
Discrete Semantic States and Hamiltonian Dynamics in LLM Embedding Spaces
Received Date: Dec 01, 2025 / Accepted Date: Jan 16, 2026 / Published Date: Jan 20, 2026
Copyright: ©2026 Timo Aukusti Laine. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Laine, T. A. (2026). Discrete Semantic States and Hamiltonian Dynamics in LLM Embedding Spaces. OA J Applied Sci Technol, 4(1), 01-23.
Abstract
We investigate the structure of Large Language Model (LLM) embedding spaces using mathematical concepts, particularly linear algebra and the Hamiltonian formalism, drawing inspiration from analogies with quantum mechanical systems. Motivated by the observation that LLM embeddings exhibit distinct states, suggesting discrete semantic representations, we explore the application of these mathematical tools to analyze semantic relationships. We demonstrate that the L2 normalization constraint, a characteristic of many LLM architectures, results in a structured embedding space suitable for analysis using a Hamiltonian formalism. We derive relationships between cosine similarity and perturbations of embedding vectors, and explore direct and indirect semantic transitions. Furthermore, we explore a quantum-inspired perspective, deriving an analogue of zero-point energy and discussing potential connections to Koopman-von Neumann mechanics. While the interpretation warrants careful consideration, our results suggest that this approach offers a promising avenue for gaining deeper insights into LLMs and potentially informing new methods for mitigating hallucinations.
Introduction
Large Language Models (LLMs) have achieved significant success in natural language processing, becoming increasingly prevalent tools across various domains. However, the computational demands of these models present a substantial challenge, limiting their accessibility and widespread deployment. This article explores the structure of LLM embedding spaces, seeking to identify underlying principles that could lead to more efficient and reliable models.
We hypothesize that LLM embedding spaces exhibit a discrete structure, analogous to distinct states in physical systems, potentially mirroring aspects of quantum mechanical systems. This structure, characterized by specific relationships between embedding vectors, motivates the application of mathematical tools and methodologies.
Several compelling reasons motivate our exploration of connections between LLM embedding spaces and quantum mechanics, analyzed through the lens of the Hamiltonian formalism. LLMs exhibit inherent indeterminacy, producing outputs with a degree of uncertainty that resonates with the probabilistic nature of quantum systems. Furthermore, the massive computational resources required for training and deploying LLMs necessitate exploring alternative computational paradigms, such as quantum algorithms and quantum computers, which offer the potential for exponential speedups. The prevalence of hallucinations in LLMs, which undermines their reliability, particularly in critical applications, underscores the need for a deeper understanding of the embedding space structure and the origins of these inaccuracies. The Hamiltonian formalism, traditionally used to describe the dynamics of physical systems, provides a powerful framework for analyzing the transformations and relationships within LLM embedding spaces, potentially revealing underlying principles that govern their behavior and contribute to these challenges. Addressing these issues of computational cost and hallucinations is crucial for realizing the full potential of LLMs.
This article investigates the potential for leveraging mathematical methods, including those inspired by quantum mechanics and embodied in the Hamiltonian formalism. If similarities between LLM embedding spaces and other systems are established, quantum- inspired algorithms may offer performance improvements in LLM training and inference. Furthermore, insights into the nature of uncertainty, drawing from concepts like zero-point energy, might provide new strategies for managing and mitigating hallucinations, thereby enhancing the reliability and trustworthiness of LLMs.
We begin by examining the discrete structure of LLM embedding spaces, demonstrating how L2 normalization and other architectural features impose constraints on the relationships between embedding vectors. We consider a system of two distinct embedding vectors in the semantic space, which we term the LLM Embedding System. We then explore the mathematical formalisms used to describe this system, identifying key properties and exploring its characteristics. Finally, we discuss the implications of these findings for addressing hallucinations, including potential connections to quantum-inspired approaches.
Background and Related Work
Large Language Models (LLMs), such as those based on the Transformer architecture, have revolutionized natural language processing by utilizing high-dimensional embedding spaces to represent words, phrases, and sentences as numerical vectors [1]. The dimensionality of these spaces typically ranges from hundreds to thousands of dimensions. The training process, often involving massive datasets and self-supervised learning objectives, shapes the geometry of these embedding spaces, encoding complex semantic relationships between linguistic units [2,3]. The nature of these relationships and the structure of the resulting embedding spaces are active areas of research, with investigations focusing on understanding how semantic information is organized and accessed within these models [4]. The capabilities of these models, such as few-shot learning, have also been extensively studied [5].
Numerous studies have investigated the properties of LLM embedding spaces. A fundamental observation is that semantically similar words tend to be located proximally within the embedding space, as quantified by cosine similarity and other distance metrics [6,7]. This proximity reflects the model’s ability to learn semantic relationships directly from data. Furthermore, researchers have explored how specific directions within the embedding space can be associated with particular semantic features or relationships, such as gender or sentiment [8,9]. Techniques like recursive matrix-vector spaces have also been used to capture semantic compositionality, enabling models to understand the meaning of phrases and sentences based on the meanings of their constituent words [10].
L2 normalization of embedding vectors is a common practice in LLMs, significantly influencing the geometry of the embedding space. Normalization encourages embeddings to reside on a hypersphere, which can simplify computations and enhance training stability. This constraint also affects the relationships between embedding vectors, as explored in this article. The impact of normalization on downstream task performance and the optimization landscape has been studied, with findings suggesting that normalization can improve generalization and prevent overfitting [11].
Various techniques have been employed to analyze the structure of LLM embedding spaces. Dimensionality reduction techniques, such as Principal Component Analysis (PCA) and t-distributed Stochastic Neighbor Embedding (t-SNE), have been used to visualize high-dimensional embedding spaces in lower dimensions, revealing clusters and patterns of semantic relationships [12]. Probing tasks, which involve training classifiers to predict properties of input text based on its embedding vector, provide insights into the information encoded within the embedding space [13]. Geometric analysis, involving the analysis of geometric properties such as the distribution of distances between embedding vectors and the curvature of the space, is also utilized to understand the underlying structure of these spaces [11].
The application of mathematical concepts to natural language processing is an area of growing interest. Models have been proposed for various NLP tasks, including text classification and information retrieval. These models often leverage principles such as superposition and entanglement to represent and process linguistic information. Information geometry, which studies statistical manifolds, has also been applied to analyze the structure of language models [14]. Dynamical systems theory provides another lens for understanding the evolution of language models during training and inference [15].
In previous work, we have explored the analogy between LLM embedding spaces and mathematical concepts, positing that LLMs operate within a structured semantic space. Specifically, we introduced the concept of semantic wave functions to capture nuanced semantic interference effects, clarified the core assumptions of a model for LLMs, and demonstrated the feasibility of estimating semantic similarity using hardware, including the experimental calculation of cosine similarity [16-18]. These papers establish a foundation for the present work by highlighting the potential of mathematical principles to offer new perspectives on semantic representation and processing.
The potential of quantum computing for NLP tasks is also being explored. While the practical realization of quantum algorithms on current quantum hardware remains a challenge, classical algorithms inspired by quantum mechanics are being developed and applied to NLP. These quantum-inspired approaches offer alternative ways to represent and process linguistic information [19].
It’s important to acknowledge research focusing on the limitations of embedding spaces. While powerful, they can exhibit biases and fail to capture nuanced semantic relationships [20]. For example, Caliskan et al. (2017) demonstrated that semantics derived automatically from language corpora can contain human-like biases, reflecting societal stereotypes and prejudices [21]. Therefore, any mathematical framework applied to these spaces must be interpreted with caution, considering the inherent limitations of the underlying representations.
LLM Embedding Spaces Structure
In this section, we introduce an LLM Embedding System and demonstrate its discrete structure. We consider two distinct embedding vectors within a semantic space, representing a system where the vectors exhibit semantic dissimilarity.
LLM Embedding System
We model an LLM Embedding System, focusing on the relationship between dissimilar embedding vectors. Let a represent an arbitrary embedding vector
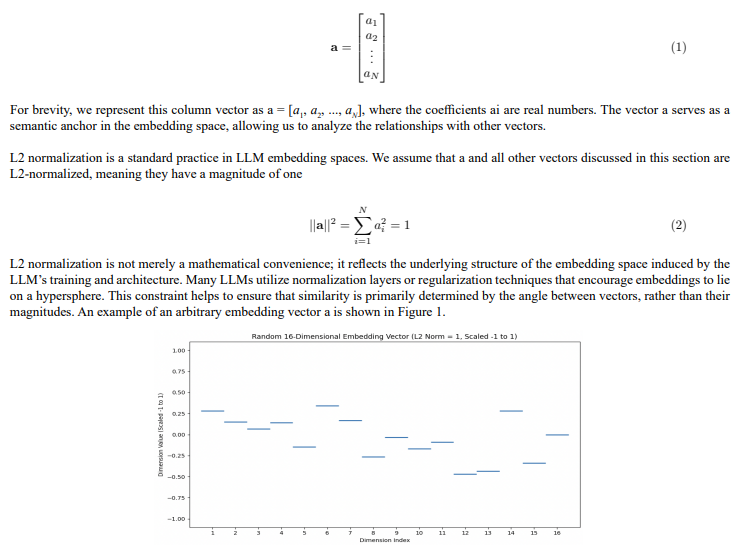
Figure 1: Visualization of a 16-dimensional embedding vector, representing a semantic concept within an LLM’s embedding space. The x-axis indicates the dimension index, while the y-axis represents the value of each dimension, scaled between -1 and 1. Although the specific values are arbitrary for illustrative purposes, the vector is L2-normalized, meaning its magnitude is 1. The horizontal lines depict the magnitude of each dimension, illustrating the discrete nature of the embedding vector components. This provides a visual representation of the structured nature of the embedding space.
LLM embedding spaces are high-dimensional and encompass a vast number of potential token combinations. However, only a subset of these combinations yields meaningful semantic representations. Vector embeddings generated by models like Sentence Transformers aim to capture this meaningfulness by mapping semantically valid token combinations to specific regions within the space. We refer to vectors representing meaningful combinations as physical and those representing meaningless combinations as non-physical.
Now, consider a vector b in the same semantic space, defined as


We will use this relation later. This condition implies that small changes in semantic features do not perfectly compensate for each other to maintain a constant overall similarity. While theoretically possible according to the cosine similarity definition, we assume this perfect compensation does not occur for physical embeddings. In other words, there isn’t a multitude of subtly different vectors that all maintain the exact same similarity score with a.
Furthermore, we assume that the embedding space is sufficiently dense, meaning that there are sufficiently many distinct states along each semantic dimension. This density is largely influenced by the amount of training data; more data generally leads to a denser space with more semantic states, while less data results in a sparser space. We also assume no degeneracy in the embedding space, meaning that ai ≠ 0 for all i. These are reasonable assumptions for physical embedding vectors, reflecting the richness and non-redundancy of semantic representations. Special cases will be handled separately.
We have now defined our LLM Embedding System and we conclude that it practically consists of two semantically different embedding vectors plus some assumptions which are reasonable for physical embedding vectors. In the next sections, we will examine the properties of this LLM Embedding System in more detail.
Embedding Perturbations
We now assume that b is a perturbation of the vector maximally dissimilar to a


This result demonstrates that the cosine similarity between the original embedding vector a and its perturbed version b is equal to minus one plus half of the sum of the squared changes in each dimension. This relationship is a direct consequence of the L2 normalization of the embeddings and the constraint imposed on the perturbations.
Smallest Semantic Perturbation
Having established the relationship between cosine similarity and perturbations within the embedding space, we now explore the implications for the structured nature of this space. We propose that the discrete nature of language, as represented by tokens, induces a non-continuous structure within the embedding space.
Let us now investigate the scenario where vector b represents the smallest possible semantic perturbation of the vector maximally dissimilar to vector a. This implies that their cosine similarity is slightly greater than -1


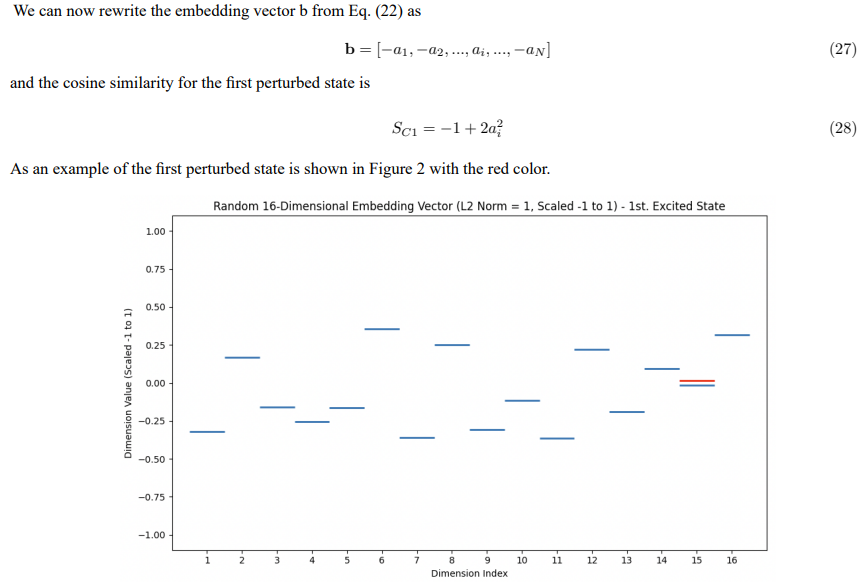
Figure 2: Visualization of a 16-dimensional embedding vector representing a semantic concept. Horizontal lines show dimension magnitudes (scaled -1 to 1). A red line indicates the first perturbed state, where the value of one dimension is inverted compared to the fully dissimilar state, illustrating the smallest possible semantic change.
This result implies that, within the constraints of L2 normalization and minimizing the L2 norm of the perturbation, a change in cosine similarity corresponds to inverting the value of one dimension. This further implies that if we consider an LLM embedding vector in semantic space and examine the smallest change in cosine similarity of its maximally dissimilar vector, we find that the value of one dimension changes sign. This means that if we have some semantic context or sentence, and a dimension represents a semantic feature or a domain, then the smallest change in one semantic feature corresponds to inverting that feature.
Higher Perturbations
To further explore the structure of the embedding space, we now consider higher-order perturbations. Specifically, we define the cosine similarity for a second perturbed state as



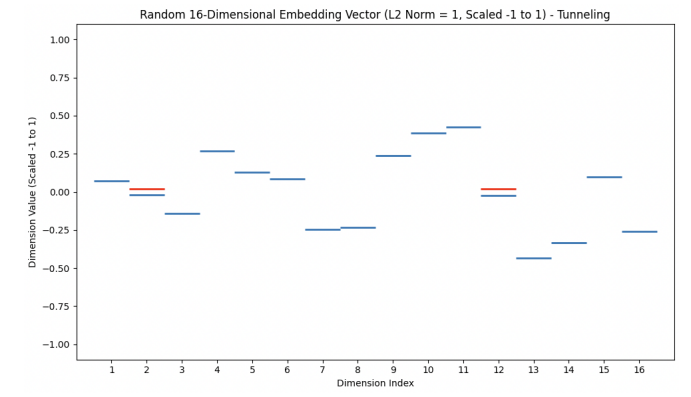
Figure 3: IIlustration of the embedding vector b after a specific perturbation. Horizontal lines represent the values of each dimension in the vector, scaled from -1 to 1. Red lines highlight dimensions j and i, which have undergone similar perturbations, effectively swapping their original values. This type of perturbation corresponds to a transition to a higher excited state in the LLM embedding space.
One can numerically verify that the Eq. (42) holds. When generating embedding vectors using tools like Sentence Transformers, it’s very common for the two vectors to have different values across all dimensions. So Eqs. (41) and (42) are common forms for a physical embedding vector. If we further consider a third embedding vector like
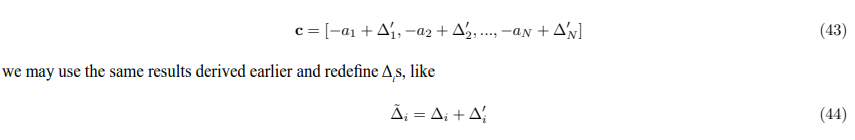
Hamiltonian Representation of Semantic Transformations
We further investigate the cosine similarity by introducing a Hamiltonian matrix to represent the transformation between embedding vectors. This approach enables us to leverage tools from linear algebra to analyze the structure of the embedding space. Vector b can be expressed as

This provides a compact and insightful representation of the relationship between embedding vectors. It allows us to view the transformation from a to b as a linear operation, which can be analyzed in terms of the eigenvalues and eigenvectors of the Hamiltonian matrix.
Types of Semantic Transitions
We can identify three distinct cases for the transformation between embedding vectors.
1. Same or Maximally Dissimilar Embedding Vectors
The simplest case occurs when b = a. In this scenario, H is the identity matrix, denoted by I, where hii = 1 for all i and hij = 0 for i ≠ j. This corresponds to no transformation, and the cosine similarity is 1. Similarly, if b = −a, then H = −I.
2. Direct Transitions
Let us now consider the case where a and b are distinct embedding vectors. A direct transition implies that each component bi of vector b depends only on the corresponding component ai of vector a. Mathematically, this can be expressed as
bi = hiiai (48)
with hij = 0 when i ≠ j. This represents a scenario where the transformation from a to b involves only scaling the individual dimensions of a. This can be interpreted as a transformation that changes the strength of individual semantic features without introducing any dependencies between them. The Hamiltonian H is a diagonal matrix in this case, and the diagonal elements, hii, represent the scaling factors for each semantic feature.
3. Indirect Transitions
Let us now consider three distinct embedding vectors, representing meaningful semantic states, which we denote as |1⟩, |2⟩, and |3⟩. These vectors can be interpreted as embedding vectors corresponding to specific token combinations that possess semantic coherence. The use of Dirac notation (ket notation) is intended to draw an analogy to quantum mechanics and to facilitate the application of quantum mechanical tools for analyzing LLM embedding spaces. Our objective is to understand how transitions between these states can be achieved and how indirect transitions relate to direct transitions.
A direct transformation from state |1⟩ to state |2⟩ can be achieved by applying a linear operator, H1→2. The same principle applies to direct transformations between any two of these states (e.g., |1⟩ to |3⟩ or |2⟩ to |3⟩). Mathematically, this can be expressed as
|3⟩ = H1→3|1⟩ (49)
where H1→3 is a Hamiltonian representing the direct transition from state |1⟩ to state |3⟩. This direct transition represents a relationship between semantic states. For example, |1⟩ might represent the concept ”quick brown fox,” and |3⟩ might represent ”a fast brown fox.” The Hamiltonian H1→3 transforms the semantic features in |1⟩ to align with those in |3⟩.
However, a key insight arises when we consider indirect transitions. Suppose we want to transform state |1⟩ to state |3⟩, but we do so through the intermediate state |2⟩. This involves two sequential transformations: first, from |1⟩ to |2⟩, and then from |2⟩ to |3⟩. This indirect transition may suggest a more complex semantic relationship between |1⟩ and |3⟩. For example, |1⟩ might represent the concept ”quick brown fox,” |2⟩ might represent ”a fast brown animal,”

Figure 4: Quantum-inspired representation of semantic relationships in LLM embedding space. Three semantic states, |1⟩, |2⟩, and |3⟩, are visualized as energy levels with associated population distributions, drawing an analogy to quantum mechanical systems. The arrows represent effective Hamiltonians governing transitions between these states, with H1→3 indicating a direct transformation from |1⟩ to|3⟩, and H1→2 and H2→3 representing sequential transformations through the intermediate state |2⟩, suggesting a more complex semanticrelationship.
and |3⟩ might represent ”a fast brown fox.” The intermediate state |2⟩ introduces a level of abstraction that is not present in the direct transition from |1⟩ to |3⟩, see the Figure 4.
The first transformation, from |1⟩ to |2⟩, is represented by a Hamiltonian H1→2. We can then determine the vector |2⟩, which represents the intermediate state, by applying the Hamiltonian H1→2 to the vector |1⟩
|2⟩ = H1→2|1⟩ (50)
This results in a new vector, which we denote as |2⟩. The second transformation, from |2⟩ to |3⟩, can then be represented relative to the first transformation. To express this mathematically, let us represent the transformation from |2⟩ to |3⟩ as
|3⟩ = H2→3|2⟩ (51)
Applying this Hamiltonian to the intermediate state |2⟩ yields the final state |3⟩|
3⟩ = H2→3|2⟩ (52)
To analyze the transformations in a common basis, we can perform a change of basis. Let U be a unitary transformation that changes the basis from |2⟩ to |1⟩. We can then express |3⟩ in terms of the basis of |1⟩
|3⟩ = H2→3H1→2|1⟩ (53)
It is important to note that H2→3 is expressed in the basis of |2⟩. To express this in the basis of |1⟩, we can use the unitary transformation to obtain
H′2→3 = UH2→3U† (54)
where the new Hamiltonian H′2→3 represents the transformation from |2⟩ to |3⟩ in the basis of |1⟩. Applying this transformed Hamiltonian to H1→2|1⟩ yields the final state |3⟩
|3⟩ = H 2→3H1→2|1⟩ (55)
The overall transformation from |1⟩ to |3⟩ through |2⟩ is then given by
|3⟩ = Hindirect|1⟩ (56)
where Hindirect = H′2→3 H1→2 is the effective Hamiltonian for the indirect transition. Generally, the indirect Hamiltonian has off-diagonal elements.
In a realistic LLM embedding space, there are likely multiple pathways to transition from state |1⟩ to state |3⟩. Each pathway corresponds to a different intermediate state (or sequence of intermediate states) and, therefore, to a different effective Hamiltonian. This suggests a superposition of possible transition pathways. The structure of the effective Hamiltonian, specifically the presence and magnitude of off-diagonal elements, reflects the complexity of the semantic relationship between the initial and final states. A diagonal Hamiltonian indicates a direct, straightforward relationship, while a Hamiltonian with significant off-diagonal elements suggests a more indirect and nuanced relationship mediated by the intermediate states. The analysis of these effective Hamiltonians could provide insights into how LLMs process and represent complex semantic relationships. The relative contributions of different pathways could be related to the attention mechanisms within the Transformer architecture, with attention weights potentially reflecting the probability amplitudes associated with each pathway. This framework provides a bridge between the abstract mathematical representation of semantic transitions and the concrete mechanisms of LLM operation.
We note that because Eq. (47) expresses the cosine similarity as a quadratic form, even if the Hamiltonian H is not symmetric, we can always replace it with a symmetric Hamiltonian that yields the same cosine similarity value. This means that, for the purpose of calculating cosine similarity, the direction of the transition between embedding vectors does not fundamentally alter the result. A symmetric Hamiltonian implies that the relationship between semantic states is reciprocal, while a non-symmetric Hamiltonian could capture directional dependencies. The fact that the cosine similarity remains the same does not imply that the Hamiltonians are identical. The choice of using a symmetric or non-symmetric Hamiltonian should be guided by the specific research question and the desire to capture either reciprocal or directional relationships between semantic states.
Constraint on Hamiltonian Coefficients
The L2 normalization of the embedding vectors imposes a constraint on the elements of the Hamiltonian matrix H. This constraint arises from the requirement that both a and b reside on the unit hypersphere. We can derive this constraint by relating the components of b to the components of a and the elements of H

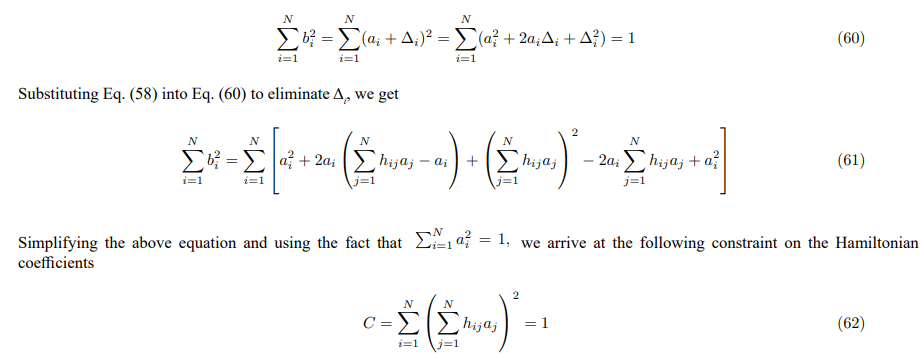
This constraint ensures that the transformed vector b = Ha remains L2 normalized. It implies that the Hamiltonian H cannot be an arbitrary matrix; its elements must satisfy this condition to preserve the geometry of the embedding space. This constraint could potentially be used to regularize the training of LLMs, encouraging them to learn embedding spaces that respect the L2 normalization property and discouraging transformations that would distort the hyperspherical geometry.
Experimental Validation of the Hamiltonian Approach
To illustrate the concepts discussed above, we present a numerical example using the Sentence Transformers embedding model ”gemma- 300m” with 768 dimensions. This experiment aims to demonstrate the validity of the Hamiltonian approach and to verify the constraint imposed by L2 normalization.
The procedure begins by defining three text prompts: ”quick brown fox” (|1⟩), ”a fast brown animal” (|2⟩), and ”a fast brown fox” (|3⟩). These prompts are encoded into embedding vectors using the Sentence Transformers model, and the resulting vectors (vec1, vec2, vec3) are automatically L2 normalized by the model. A direct cosine similarity between vec1 and vec3 is then calculated as a baseline

This confirms that the transformations remain L2 normalized. Within the limits of numerical accuracy, all equations are satisfied.
The results of this numerical experiment demonstrate that, through the use of unitary transformations, the direct and indirect cosine similarities are equal, and the constraint imposed by L2 normalization is satisfied. This provides numerical validation of the theoretical framework presented in this section, supporting the application of the Hamiltonian approach for analyzing semantic transitions in LLM embedding spaces.
Classical Hamiltonian System
We are now ready to combine results from sections III and IV. We begin with the cosine similarity expressed in terms of a Hamiltonian matrix

First Perturbation and Parity Symmetry
Using the notations defined earlier, the transformed cosine similarity for the first perturbed state Eq. (28) is


This suggests that inverting a dimension corresponds to negating a semantic feature. If a concept and its negation are equally coherent (e.g., positive versus negative sentiment), the system exhibits parity symmetry. The sign inversion is related to the eigenvalues of P (+1 and -1). The parity-transformed state is associated with the eigenvalue -1, leading to the sign inversion. However, it is important to note that H′1 itself does not perform this parity transformation; it represents the effect of a minimal perturbation, which can be related to the concept of parity symmetry.
Higher Perturbations and Rotational Symmetry
As an example for higher perturbations, we consider the specific case where vi = vj = 1. This leads to


exhibits characteristics that can be related to a combination of a rotation and a parity transformation. Specifically, the swap of components ai and aj resembles a rotation in the i-j plane, while the inversion of the signs resembles a parity transformation. This suggests that the specific higher-order perturbation is consistent with a system that exhibits rotational symmetry in the i-j plane. It indicates that the i-th and j-th dimensions represent interchangeable semantic features, such that rotating the embedding vector in the i-j plane does not significantly alter its semantic meaning.
Quantum Mechanical Interpretation and Time Evolution
In the previous section, we established a classical Hamiltonian representation of semantic transformations within LLM embedding spaces. We now explore how to extend this framework to incorporate concepts inspired by quantum mechanics, specifically by introducing unitary transformations. This allows us to draw analogies between the dynamics of semantic representations and the behavior of quantum systems.
Unitary Transformation of the Hamiltonian
Starting with the transformed cosine similarity S'C = aT H'a, we seek to express this relationship in a form that allows further analysis. Since H' is a real, symmetric matrix, it can be diagonalized by an orthogonal (and therefore unitary) transformation. Let U be a unitary matrix such that

This transformation expresses the cosine similarity in terms of the eigenvalues of H' and the components of the transformed state vector |a⟩. The diagonal elements of D can be interpreted as representing distinct semantic features, while the components of |a⟩ represent the weighting of these features.
Introducing Complex State Vectors and Time Evolution
To explore potential dynamics within this framework, we now introduce complex coefficients and a time-dependent perspective. We replace the real components of |a⟩ with complex, time-dependent coefficients cn (t)

Diagonalization of the Hamiltonian H'
In this subsection, we aim to diagonalize the Hamiltonian matrix H' derived from the cosine similarity expression. Recall that H' is defined as
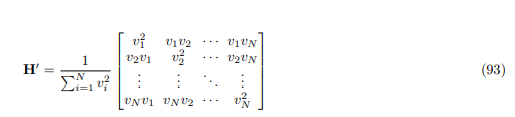
Eigenvalues of H'


In summary, by recognizing the structure of H' as a rank-1 matrix, we can directly determine its eigenvalues and diagonalized form, simplifying further analysis.
Eigenvectors of H'
The Hamiltonian matrix H' possesses a specific set of eigenvectors that correspond to its eigenvalues. For the eigenvalue λ1 = 1, the normalized eigenvector is given by
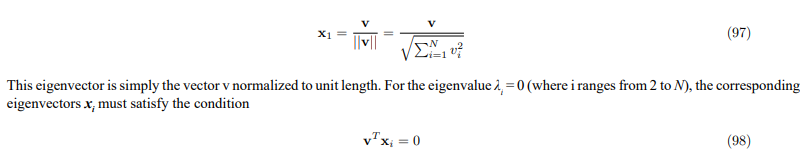
This condition implies that these eigenvectors are orthogonal to the vector v. Crucially, these eigenvectors must also be linearly independent and mutually orthogonal to each other to form a complete basis. The Gram-Schmidt process can be used to construct such a set of orthogonal eigenvectors.
Unitary Matrix U
The unitary matrix U that diagonalizes H′ is constructed by using the normalized eigenvectors as its columns

Here, x1 is the normalized eigenvector corresponding to the eigenvalue 1, and x2 through xN are the N − 1 eigenvectors corresponding to the eigenvalue 0. The orthogonality of these eigenvectors ensures that U is a unitary matrix, which preserves the norm of vectors under transformation.
Time Evolution with Diagonalized Hamiltonian
Having obtained the diagonalized Hamiltonian D, we can now analyze the time evolution of the system. Let’s consider the case where the eigenvalues are E1 = 1 and En = 0 for n = 2,3,...,N. This significantly simplifies the expressions. The time-dependent coefficients become
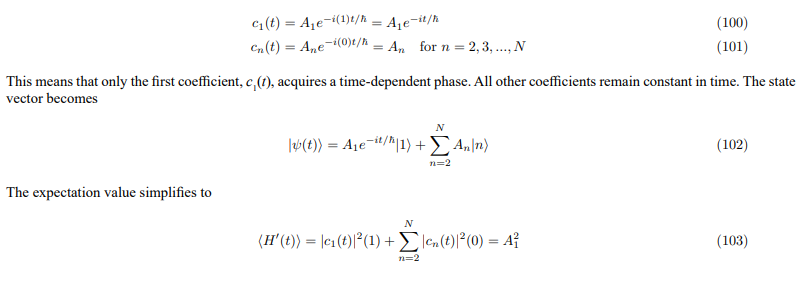
Since A1 is constant, the expectation value is also constant in time. The fact that we have one eigenvalue equal to 1 and N − 1 eigenvalues equal to 0 has several important consequences:
1. Single Active Mode: The system effectively has only one mode that evolves in time. This mode is associated with the eigenvector |1⟩ corresponding to the eigenvalue 1. All other modes remain constant.
2. Simplified Dynamics: The dynamics of the system are greatly simplified. The time evolution is governed by a single phase factor, e−it/hassociated with the active mode.
3. Constant Value: The expectation value is constant and equal to the square of the amplitude of the active mode.
4. Projection onto a Subspace: The system’s state vector can be seen as a projection onto a one-dimensional subspace spanned by the eigenvector |1⟩, plus a constant component in the orthogonal subspace. The time evolution only affects the component in the subspace spanned by |1⟩.
In the context of LLM embedding spaces, this eigenvalue structure suggests that the semantic transformation is dominated by a single, time-evolving feature, while other features remain relatively static. This could correspond to a scenario where a particular aspect of the semantic meaning is changing over time, while other aspects remain constant.
Analogue of Zero-Point Energy
Within our defined LLM Embedding System, the cosine similarity SC is strictly bounded between -1 and 1, and consequently, the transformed cosine similarity + 1) is strictly bounded between 0 and 1. Specifically, 0 < S′C < 1. This was the assumption of the LLM Embedding Model. Therefore, the minimum possible value of S′C is not zero, but rather a small positive value, which we denote as €> 0. This value represents the closest possible approach to maximal dissimilarity within our system



In the context of LLM embedding spaces, this analogue could be interpreted as the minimum level of semantic coherence that is required for a concept to be considered a physical embedding within our defined system. It represents the inherent semantic content that prevents a concept from being completely meaningless or random. The value of €would depend on the specific LLM architecture and training data, reflecting the inherent structure of the embedding space.
Analogy to the Quantum Harmonic Oscillator and Koopman-von Neumann Mechanics
Having derived a framework for LLM embedding spaces, it is instructive to draw parallels to other well-established systems. The transformation we have performed, starting from an LLM Embedding System and arriving at a representation using linear algebra, shares similarities with the quantum harmonic oscillator and the Koopman-von Neumann (KvN) mechanics.
Quantum Harmonic Oscillator
The quantum harmonic oscillator is a fundamental system in quantum mechanics that describes a particle subject to a restoring force proportional to its displacement from equilibrium. Key features of this system include:
1. Discrete Energy Levels: The energy of the quantum harmonic oscillator is quantized, meaning it can only take on discrete values.
2. Zero-Point Energy: Even in its ground state, the quantum harmonic oscillator possesses a non-zero energy, known as the zero-point energy.
3. Wave-like Behavior: The quantum harmonic oscillator is described by a wave function that evolves in time according to the Schrödinger equation.
In our LLM Embedding System, the eigenvalues of the Hamiltonian H′ can be interpreted as representing distinct semantic features, analogous to the discrete energy levels of the quantum harmonic oscillator. The L2 normalization constraint and the structure of the embedding space impose a form of organization that leads to these distinct features. The single non-zero eigenvalue suggests a dominant semantic mode, similar to the ground state of the harmonic oscillator. Furthermore, we have derived an analogue to zero-point energy, EZP = €, representing the minimum semantic content present even in states of near-maximal dissimilarity. The complex coefficients in our time-dependent model can be viewed as representing oscillations between different semantic states, analogous to the oscillations of the quantum harmonic oscillator.
Koopman-von Neumann Mechanics
Koopman-von Neumann (KvN) mechanics is an alternative formulation of classical mechanics that uses mathematical tools similar to those used in quantum mechanics. In KvN mechanics, classical states are represented as vectors in a Hilbert space, and classical observables are represented as operators acting on these vectors. The key difference between KvN mechanics and standard classical mechanics is that KvN mechanics linearizes the classical dynamics by embedding the classical phase space into a larger Hilbert space. This linearization allows for the application of linear algebra techniques to analyze the classical system. Our approach to LLM embedding spaces shares several similarities with KvN mechanics:
1. Linearization: We have effectively linearized the complex relationships within the LLM embedding space by representing semantic transformations as linear operations in a high-dimensional vector space.
2. Hilbert Space: The L2-normalized embedding vectors reside in a Hilbert space, allowing us to apply linear algebra tools.
3. Transformations: The use of transformations to diagonalize the Hamiltonian is related to the unitary time evolution operator in KvN mechanics. The single dominant eigenvalue in our diagonalized Hamiltonian suggests a simplified KvN system where the dynamics are largely governed by a single mode.
However, it is important to note that our approach is not a direct application of KvN mechanics. We are not starting with a classical system and then linearizing it using the KvN formalism. Instead, we are starting with a system (LLM embedding spaces) that is already represented as vectors in a high-dimensional space and then applying linear algebra tools to analyze its structure and dynamics. The KvN analogy provides a useful framework for understanding how linear algebra can be used to analyze complex systems.
Potential Applications: Mitigating Hallucinations
One potential application of our framework lies in mitigating hallucinations in LLMs. We hypothesize that hallucinations arise from transitions to semantically incoherent states within the embedding space. These incoherent states may be characterized by:
1. Distorted Eigenvector Distribution: Transitions to states where the dominant eigenvalue is 1, but the distribution of the corresponding eigenvector’s components is significantly different from that of coherent semantic representations. This could indicate an over-reliance on a single, potentially irrelevant, feature or a distorted combination of features.
2. Unstable Combinations: Combinations that are highly sensitive to small perturbations, leading to unpredictable outputs.
3. Violation of Structure: Hallucinations might involve semantic representations that violate the parity or rotational symmetries observed in coherent states.
Based on these Characteristics, We Propose the Following Strategies for Mitigating Hallucinations:
1. Eigenvector Distribution Regularization: Introduce a regularization term in the LLM training objective that penalizes transitions to states with distorted eigenvector distributions. This could involve minimizing the difference between the eigenvector distribution of the current state and the average eigenvector distribution of coherent semantic representations. This would encourage the model to favor combinations of features that are more typical of meaningful content.
2. Symmetry Enforcement: Develop techniques to explicitly enforce parity and rotational symmetries during LLM training and inference. This could involve adding constraints to the embedding vectors or modifying the attention mechanisms to respect these symmetries.
3. Uncertainty Quantification: Adapt techniques for uncertainty quantification to estimate the likelihood of a hallucination. This could involve calculating the variance.
Further research is needed to validate these strategies and to develop practical algorithms for implementing them. However, the framework provides a new perspective on the problem of hallucinations and suggests potentially fruitful avenues for future investigation.
Discussions
This article has presented a new approach to analyzing LLM embedding spaces, drawing inspiration from mathematical tools. We have demonstrated that the L2 normalization constraint, a common characteristic of LLM architectures, leads to a structured embedding space with properties that can be effectively explored using mathematical formalisms, particularly the Hamiltonian formalism. Our analysis has revealed relationships between LLM embedding spaces and other systems, suggesting that these tools may provide valuable insights into the inner workings of LLMs.
One potential application of this framework lies in addressing the challenge of hallucinations, where LLMs generate factually incorrect or nonsensical outputs. If the mathematical structures of LLM embedding spaces exhibit similarities, then insights might offer new approaches to managing this uncertainty. The relationships between LLM embedding spaces and other systems could facilitate the use of advanced computing to accelerate LLM training and inference. Algorithms have the potential to provide performance gains for tasks such as linear algebra and optimization, which are central to LLM operation.
This work offers a promising avenue for gaining deeper insights into LLMs. The relationships we have drawn, while requiring careful consideration, provide a perspective on the structure and behavior of LLM embedding spaces. The Hamiltonian formalism provides a valuable tool for analyzing semantic relationships and for understanding how LLMs process and represent complex semantic information. It is important to emphasize that we do not assert that specific symmetries are necessarily present in LLM Embedding Systems. However, our analysis reveals no contradictions that would preclude their existence, suggesting a potential avenue for future research.
While the framework presented here is still in its early stages of development, it offers a compelling vision for the future of LLM research. Exploration of these connections could lead to transformative advancements in both the efficiency and reliability of LLMs. The work should focus on developing more nuanced similarity measures, investigating non-linear effects, analyzing the Hamiltonian spectrum, and exploring the relationship between attention weights and Hamiltonian elements. Ultimately, the goal is to develop algorithms and techniques that can address the key challenges within LLMs, such as computational cost and reliability.
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need.Advances in neural information processing systems, 30.
- Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A neural probabilistic language model. Journal of machine learning research, 3(Feb), 1137-1155.
- Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.
- Geva, M., Schuster, R., Berant, J., & Levy, O. (2021, November). Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (pp. 5484-5495).
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. International Conference on Learning Representations.
- Pennington, J., Socher, R., & Manning, C. D. (2014, October). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532-1543).
- Bolukbasi, T., Chang, K. W., Zou, J. Y., Saligrama, V., & Kalai, A. T. (2016). Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Advances in neural information processing systems, 29.
- J. Zhao, T. Wang, M. Yatskar, V. Ordonez, and K.-W. Chang. Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Association for Computational Linguistics, 15-20, 2018.
- Socher, R., Huval, B., Manning, C. D., & Ng, A. Y. (2012, July). Semantic compositionality through recursive matrix-vector spaces. In Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning (pp. 1201-1211).
- Arora, S., Li, Y., Liang, Y., Ma, T., & Risteski, A. (2018). Linear algebraic structure of word senses, with applications to polysemy.Transactions of the Association for Computational Linguistics, 6, 483-495.
- Maaten, L. V. D., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of machine learning research, 9(Nov), 2579-2605.
- I. Tenney, P. Xia, B. Chen, A.Wang, A. Poliak, R.T. McCoy, N. Kim, B. Van Durme, S.R. Bowman, D. Das, and E. Pavlick. What do You Learn from Context? Probing for Sentence-Level Properties in Contextualized Word Representations. In International Conference on Learning Representations, 2019.
- Amari, S. I. (2016). Information geometry and its applications (Vol. 194). Springer.
- Rabinovich, M. I., Varona, P., Selverston, A. I., & Abarbanel, H. D. (2006). Dynamical principles in neuroscience. Reviews ofmodern physics, 78(4), 1213-1265.
- Laine, T. A. (2025). Semantic Wave Functions: Exploring Meaning in Large Language Models Through Quantum Formalism. OA J Applied Sci Technol, 3(1), 01-22.
- Laine, T. A. (2025). The Quantum LLM: Modeling Semantic Spaces with Quantum Principles. OA J Applied Sci Technol, 3(2), 01-13.
- Laine, T. A. (2026). Quantum LLMs Using Quantum Computing to Analyze and Process Semantic Information. OA J Applied Sci Technol, 4(1), 01-19.
- Wittek, P. (2014). Quantum machine learning: what quantum computing means to data mining. Academic Press.
- Hovy, D., & Spruit, S. L. (2016). The social impact of natural language processing. In The 54th Annual Meeting of the Association for Computational Linguistics Proceedings of the Conference, Vol. 2 (Short Papers). Association for Computational Linguistics.
- Caliskan, A., Bryson, J. J., & Narayanan, A. (2017). Semantics derived automatically from language corpora contain human-likebiases. Science, 356(6334), 183-186.