
Journal of Applied Language Learning(JALL)
ISSN: 3068-1332 | DOI: 10.33140/JALL


Research Article - (2026) Volume 3, Issue 1
Applying Deep Personal Privacy (DPP) An Empirical Framework for Inference Resistance in Large Language Models
Received Date: Mar 24, 2026 / Accepted Date: Apr 27, 2026 / Published Date: May 06, 2026
Copyright: ©2026 Yair Oppenheim. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Oppenheimer, Y. (2026). Applying Deep Personal Privacy (DPP) An Empirical Framework for Inference Resistance in Large Language Models. J App Lang Lea, 3(1), 01-11.
Abstract
This paper introduces an empirical extension of the Deep Personal Privacy (DPP) framework, a novel paradigm that reconcep- tualizes privacy as resistance to inference rather than mere control over data disclosure. Unlike traditional privacy-preserving approaches-such as k-anonymity, l-diversity, t-closeness, and differential privacy-which primarily focus on data access and identifiability, the DPP framework models privacy as impedance within an inference network.
The core contribution of this work lies in operationalizing DPP within embedding-based systems, particularly large language models (LLMs), where sensitive information can be inferred through semantic alignment rather than explicit disclosure. We establish a formal mathematical relationship between cosine similarity, inference probability, and privacy impedance, demon- strating that reducing semantic alignment systematically increases resistance to inference.
Through empirical analysis on medical and social media textual data, we show that DPP-based mechanisms-such as em- bedding perturbation, abstraction, and dual-shifting transformations-effectively weaken inference pathways while preserving semantic utility. In addition, we introduce a regulatory interpretation of privacy via the parameter K, enabling privacy to be enforced as a measurable and auditable constraint on inference capability.
This work contributes a new layer to privacy protection in the ICT era by shifting the focus from data protection to inference control, offering both a theoretical foundation and a practical framework for designing privacy-preserving AI systems.
Keywords
Deep Personal Privacy (DPP), Inference-Based Privacy, Privacy Impedance, Inference Resistance, Large Language Models (LLMs), Semantic Alignment, Cosine Similarity, Embedding Perturbation, Dual Shifting Transformation, Epistemic Privacy, Privacy Engineering, GDPR, Eu AI Act
Introduction
Many attempts have been made to redefine personal privacy, none of which are fully adequate [1-7]. In this article, I propose replacing the discourse on personal privacy with a focus on personal privacy information, with discussion of personal privacy information [8]. The central argument is that the shift from personal privacy to personal privacy information is both necessary and justified. First, personal privacy information can be digitized and detached from the individual. Second, personal privacy is fundamentally manifested through information. Third, any meaningful discussion of privacy is ultimately a discussion of information flows. With the rise of Information Communication Technologies (ICT) over the past several decades, we live in an age where information flows more freely than ever [5,8]. Therefore, any meaningful analysis of privacy must focus on the behavior of information flows. Unfortunately, not all this information is willfully and knowingly shared by those providing it, nor is it thoughtfully collected and stored by those obtaining it. As such, the increased accessibility of personally identifying information and other private data has become a widely recognized concern.
Given that most prominent LLMs are trained on large-scale web data, it is natural to consider whether this poses any downstream risks to privacy. As it turns out, LLMs learn specific information about individuals, and it is possible to extract that information with sufficient prompt [14,17]. Privacy remains a largely unsolved problem for LLM at this point” [17]. Privacy thus becomes an inference problem, rather than solely a data collection problem [9,11]. In this article, we introduce a new approach-the Deep Personal Privacy (DPP) framework-which reconceptualizes privacy in contemporary AI systems [1-8]. Traditional privacy frameworks focus primarily on disclosure, identifiability, and access control. However, as argued in Beyond Disclosure: Reframing Privacy as Inference Impedance in Large Language Models, privacy in modern AI systems must be reconceptualized as an inference problem rather than a disclosure problem.
The Deep Personal Privacy (DPP) framework introduces a novel perspective, in which privacy is defined as impedance within an inference network, where semantic representations enable latent inference of sensitive attributes [9,11]. Within this paradigm, privacy risk is not determined by what is explicitly revealed, but by how easily sensitive information can be inferred from latent embeddings [5–7,9,11].
The present paper extends this theoretical framework by presenting an empirical implementation of DPP principles. Specifically, we demonstrate how DPP-based mechanisms reduce inference capability across two domains: Health inference from medical-related textual data by applying embedding-based analysis, cosine similarity metrics, and probabilistic inference modeling, we evaluate how DPP mechanisms increase inference impedance while preserving semantic utility.
This paper provides an empirical validation of the Deep Personal Privacy (DPP) framework introduced in Oppenheim [9]. In that work, privacy is formally defined as inference impedance within embedding-based systems, where inference-conductive similarity enables latent inference of sensitive attributes [14,17]. The present study operationalizes these theoretical principles and evaluates them empirically using real-world textual data.
The following proposition is derived directly from the formal DPP framework presented in Oppenheim and serves as the theoretical foundation for the empirical analysis conducted in this paper [9].
To clarify the novelty and scope of this work, we summarize its contributions as follows:
i. Conceptual Contribution
We formalize privacy as inference impedance, redefining privacy risk as a function of semantic alignment in embedding space.
ii. Mathematical Contribution
We establish a formal relationship between cosine similarity, inference probability, and privacy impedance, providing a quantitative foundation for inference-based privacy.
iii. Empirical Contribution
We demonstrate, through experiments on medical and social media data, that DPP-based transformations systematically reduce inference capability while preserving semantic utility.
iv. Methodological Contribution
We introduce the dual-shifting transformation, a principled mechanism for reducing embedding alignment without degrading semantic coherence.
v. Regulatory Contribution
We propose the parameter K as a model-agnostic regulatory control variable, enabling privacy to be enforced as an auditable constraint on inference.
DPP mathematical Proposition
Proposition 1: (DPP Monotonicity Under Reduced Embedding Proximity).
Let z be the embedding of a user input and let c be the prototype vector of a sensitive attribute. Define cosine similarity by cosine similarity, ![]() This formulation follows the definition of cosine similarity, as introduced in Oppenheim (2026), where embedding proximity serves as the primary mechanism enabling inference of sensitive attributes [11].
This formulation follows the definition of cosine similarity, as introduced in Oppenheim (2026), where embedding proximity serves as the primary mechanism enabling inference of sensitive attributes [11].
Let inference probability be given by the logistic mapping

Proof Sketch

Methodology: DPP-Based Inference Pipeline
The experimental pipeline consists of four core stages:
Step 1: Text Extraction
Raw textual inputs are collected from medical discussion contexts. These texts are not labeled explicitly with sensitive attributes but contain latent semantic cues.
Step 2: Embedding Computation
Each text is transformed into a high-dimensional embedding vector: This embedding encodes semantic relationships that enable inference.
Step 3: Cosine Similarity Computation
For each sensitive attribute, we compute cosine similarity: where is the prototype vector representing the sensitive concept. High cosine similarity indicates strong alignment and therefore higher inference risk [11,14].
Numerical Example: Steps 1–3 (DPP Pipeline)
Step 1: Text Extraction
Consider the following user input: x="I go every week to the oncology department" This text does not explicitly disclose any sensitive attribute, yet it contains strong implicit semantic cues related to health.
Step 2: Embedding Computation



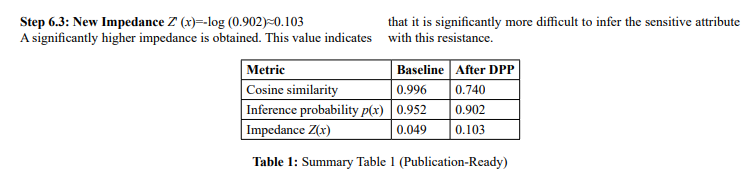
Summary of the Numerical Example
Using a moderated logistic scaling parameter (), the baseline cosine similarity of 0.996 yields an inference probability of approximately 0.952 and a corresponding impedance of 0.049. After applying a stronger DPP transformation, cosine similarity decreases to 0.740, reducing inference probability to approximately 0.902 and increasing impedance to 0.103. This represents a substantial increase in inference resistance. The result illustrates that DPP mechanisms can meaningfully raise privacy impedance by weakening conceptual alignment in embedding space.
Numerical Corollary from the Example
Using the improved numerical example:

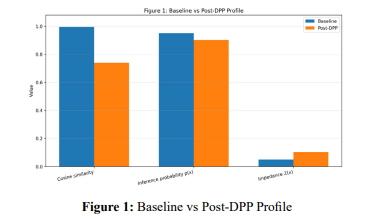
The figure compares cosine similarity, inference probability,and privacy impedance before and after application of a DPP transformation. The reduction in embedding proximity lowers inference probability and increases impedance, illustrating the core claim of the DPP framework that privacy improves when inferential pathways become less semantically conductive.
Dataset: Medical Forum / Patient Text (Health Inference)
To evaluate inference-based privacy risks, we utilize textual data derived from medical discussion environments, including platforms such as MedHelp and HealthBoards, as well as clinical-style narratives inspired by datasets such as MIMIC. These datasets are particularly suitable for the DPP framework because they exhibit strong implicit health signals without explicit disclosure [14]. Users often describe experiences, symptoms, or behaviors that indirectly reveal sensitive medical conditions. For example, a sentence such as: “I visit the oncology department every week” does not explicitly disclose a diagnosis yet embedding-based models encode strong associations between “oncology” and severe health conditions [14,17]. This creates a low-impedance inference pathway from observable text to sensitive attributes. Formally, each textual input is mapped into an embedding vector: .Sensitive attributes (e.g., HEALTH) represent prototype vectors , constructed from representative concept terms. This dataset therefore provides a natural testbed for evaluating latent inference leakage, aligning directly with the DPP paradigm.
Implicit Inference in Social Media Texts
Introduction
User-generated content in social media platforms often contains rich semantic structures that enable inference of sensitive attributes, without explicit disclosure [11]. Unlike structured datasets, these texts rely on narrative, emotional expression, and contextual cues [14]. Within the Deep Personal Privacy (DPP) framework, such texts provide a natural testbed for evaluating inference-based privacy leakage.This section demonstrates how implicit semantic cues in social media text led to high inference probability and low privacy impedance, and how DPP mechanisms mitigate this effect.
Empirical Example
Original Text
We consider the following Reddit-style text: “It's been 6 months since my last positive post in this community. While going through treatment I spent a lot of time here in the trenches with others going through it all. I promised myself I would come back and post positive updates after I was through with it, as a shining light for some of you in a dark spot right now [10].”
Extraction of Semantic Cues
Although the text does not explicitly disclose any medical condition, it contains a rich set of implicit semantic cues. Health-related cues: treatment, going through it , trenches. These expressions semantically align with concepts such as serious illness, prolonged treatment, and medical hardship. Mental-state cues: dark spot, positive updates, shining light. These cues indicate emotional distress and recovery dynamics. Community cues: this community, others going through it.These suggest participation in a shared condition or disease-related group.
Construction of Prototype Vector c

Text Embedding Representation z

Cosine Similarity
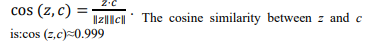
Inference Probability

Privacy Impedance
Privacy impedance is defined as: Z(x)=-log (p(x)), Z(x)≈0.049 .This low impedance indicates that the inference pathway is highly conductive
Interpretation
This example demonstrates that explicit disclosure is not required for privacy leakage. Despite the absence of direct references to a medical condition, the embedding vector of the text is highly aligned with the health prototype vector. As a result:
• inference probability is high
• privacy impedance is low
• sensitive attributes can be inferred with minimal resistance
Key Insight (Core DPP Claim)
Privacy leakage in large language models arises from conceptual alignment in embedding space, rather than from explicit disclosure [5-7,9, 11].
Formal Implication
The result supports the central DPP relationship: ↓cosine similarity ⇒ ↑ impedance ⇒ ↑ privacy
Concluding
This analysis confirms that even implicit, narrative-based social media text can produce strong alignment with sensitive concept prototypes. This leads to high inference probability and low privacy impedance, demonstrating that privacy risk is fundamentally a geometric property of embedding space rather than a function of explicit disclosure.
Proposition-Like Rule (Simultaneous Dual Shifting)
A principled transformation of sensitive representations should reduce the cosine similarity between the input embedding z and the sensitive prototype c, while preserving their respective membership in the semantic neighborhoods, of the original text and concept [11].

thereby weakening inference pathways, while preserving semantic continuity with the original embedding space.
Range and Interpretation 0≤α,γ≤1
• α=0, γ=0: No transformation — original alignment is preserved
• 0<α,γ<1: Partial attenuation — alignment is weakened but not eliminated
• α=1, γ=1: Full removal of the mutual projection — vectors become (approximately) orthogonal
In the DPP framework, α and γ serve as explicit knobs for controlling inference resistance, enabling privacy to be enforced as a geometric property rather than a linguistic transformation [11].
Numerical Example: Dual Shifting
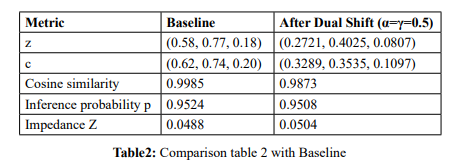
We now present a full numerical example of dual shifting, where α=γ=0.5 We use the same base vectors introduced earlier.
i. Base Vectors Were Text embedding: z=(0.58, 0.77, 0.18) , Sensitive prototype vector: c=(0.62, 0.74,0.20)
ii. Baseline Calculations were Dot Product z⋅c=0.9654 iii.
iii. Norms were: â?Â¥zâ?Â¥ 2≈0.9807 , â?Â¥câ?Â¥ 2≈0.9859
iv. Baseline Cosine Similarity was:


Interpretation
Applying a moderate dual shift with. Results in: A small but consistent decrease in cosine similarity. A slight reduction in inference probability. A modest increase in privacy impedance. Specifically: Z" increases from " 0.0488" to " 0.0504
Concluding Insight
Although the improvement is modest, this example demonstrates that even moderate dual shifting consistently weakens conceptual alignment and increases resistance to inference, without modifying the original observable text.
Deriving the Dual-Shift Parameters Under a Privacy Constraint
We now complete the derivation and obtain an explicit formulation for the dual-shift parameters α,γ as a function of an externally specified privacy amplification parameter K, defined by: Znew=KZ0
Baseline Definitions
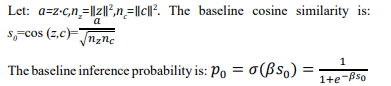
The corresponding privacy impedance is: Z0=-log (p0)
Dual Shifting Transformation
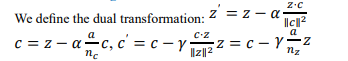
Privacy Constraint

Target Cosine Similarity
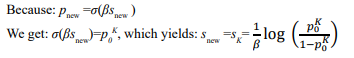
Post-Shift Cosine Similarity
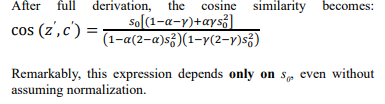
Core Constraint Equation
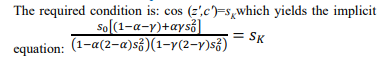
Non-Uniqueness of the Solution
This is one equation with two unknowns, hence: (α,γ) form a family of solutions" A unique solution requires an additional constraint.
Symmetric Solution:
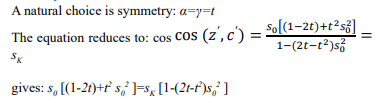
Quadratic Equation for t
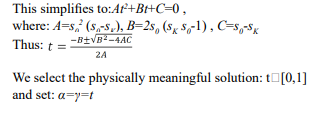
Final Algorith Key Insight
![]()

Key Insight

Full Numerical Calculation for B=3

Target Privacy Levels for K=1.5,2,3 9.2.
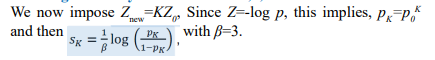
Case 1: K=1.5

Case 2:k=2
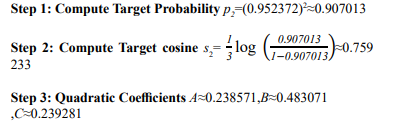
So:0.238571t^2-0.483071t+0.239281=0 The roots are:t≈1.160847,t≈0.864005 . Admissible root:t(2)≈0.864005
Case 3: K=3
Step 1: Compute Target Probability p =(0.952372)3≈0.86381
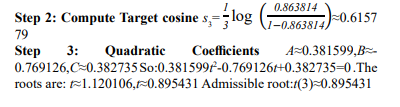
Final Tables
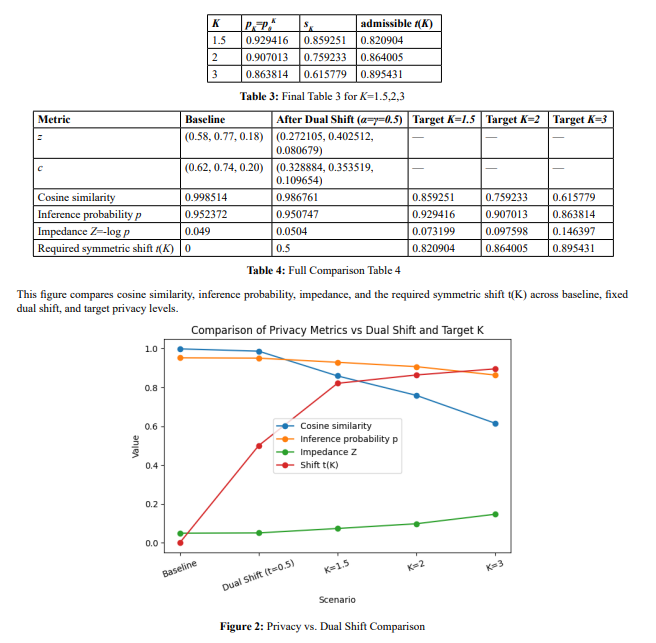
Figure 2. Comparison of cosine similarity, inference probability, impedance, and required symmetric shift t(K) across baseline, fixed dual shift, and target privacy levels. The results illustrate that while cosine similarity decreases gradually, impedance grows nonlinearly, requiring increasingly large geometric transformations to achieve higher privacy amplification levels
Deriving K Under the Constraint pK<0.5
We consider the requirement that the post-transformation inference probability satisfies: p =p K<0.5 .probability satisfies: pk =p0 K<0.5 .
Analytical Solution
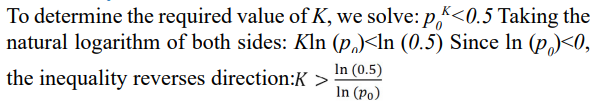
Numerical Evaluation
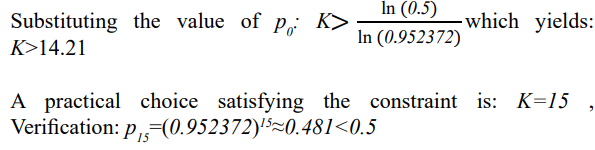
General Formulation

Conclusion
This result establishes a direct quantitative bridge between privacy defined as impedance and geometric transformations in embedding space, demonstrating that meaningful privacy guarantees require structured, nontrivial deformation rather than small perturbations.
This result shows that achieving a substantial reduction in inference probability (e.g., below 0.5) requires a significantly large privacy amplification factor K, highlighting the nonlinear relationship between impedance scaling and inference suppression.
Limitations of Existing Privacy Protection Methods and the DPP Framework Top of Form
From the reviewed the conceptual weaknesses underlying the dominant paradigms of personal privacy [8]. We can conclude one central limitation is the inability to effectively protect personal privacy understood as limited access to the self, as defined by Ruth Gavison [4]. In the age of Information and Communication Technologies (ICTs), this form of privacy is continuously undermined: individuals are subject to surveillance via IoT devices, persistent profiling, identification in public spaces, and multi-channel targeting.
The three core components of limited access—secrecy, anonymity, and solitude—are increasingly difficult to maintain, despite ongoing technological efforts. This appendix reviews the inherent limitations of widely used privacy protection methods.
K-Anonymity
K-anonymity is a formal model designed to ensure that any individual in a dataset cannot be distinguished from at least k−1 others [12]. However, this model relies on the assumption that datasets remain isolated. In practice, this assumption fails: data fusion across multiple sources enables re-identification. Moreover, attackers often possess background knowledge, allowing them to bypass quasi-identifier masking and reconstruct identities [8].
L-Diversity
L-diversity extends k-anonymity by requiring diversity in sensitive attributes within each equivalence class [13]. However it fails when the underlying data lacks sufficient diversity or when enforcing diversity significantly distorts the dataset. In such cases, either privacy is compromised or data utility is degraded [8].
T-Closeness
T-closeness improves upon l-diversity by requiring that the distribution of sensitive attributes within each group closely matches the overall distribution [14]. However, this approach introduces semantic distortion and reduces analytical value. Furthermore, it assumes limited background knowledge, which is unrealistic in modern data ecosystems, especially when combined with AI-based inference methods [8].
Differential Privacy
Differential Privacy provides strong formal guarantees by ensuring that the inclusion or exclusion of any individual does not significantly affect analysis results [15,16]. However, it is insufficient for protecting deep personal privacy, as many privacy violations rely on indirect inference. Additionally, it is not applicable in real-time interactions requiring specific user information and thus cannot prevent profiling by large-scale digital platforms [8].
Deep Personal Privacy (DPP)
We argue that the Deep Personal Privacy (DPP) framework provides a complementary and additional necessary layer of protection. DPP defines privacy as impedance within an inference network, where semantic representations enable latent inference of sensitive attributes. Within this paradigm, privacy risk is determined not by explicit disclosure, but by the ease with which sensitive information can be inferred from embeddings. Thus, DPP shifts the focus from data protection to inference resistance, addressing the fundamental limitations of existing privacy-preserving methods.
Using as a Regulatory Privacy Parameter
Traditional privacy regulation focuses on data collection (consent), data storage (anonymization), data sharing (purpose limitation) However, modern AI systems derive sensitive information through inference [14, 17], even when raw data is protected [14,17].Policy Framework: Regulating Inference Rather than Data the Principle: Regulation should constrain what can be inferred, not only what is stored [11].
The parameter K can be interpreted as a regulatory control variable that enforces a minimum level of privacy by scaling the system’s impedance to inference [11]. Rather than regulating specific algorithms or data representations, the regulator imposes a constraint on observable inference capability, requiring that the post-intervention inference probability satisfies. This induces a target cosine similarity, which in turn determines the required geometric transformation in embedding space. Consequently, provides a model-agnostic, continuous, and auditable mechanism for privacy regulation, directly linked to the Deep Personal Privacy (DPP) formulation, where increasing reduces the rate of knowledge extraction by increasing impedances of privacy [3].
Example Policy
“Any system performing user profiling must ensure that inference
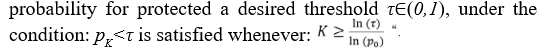
Key Insight
The regulator is not required to access or interpret the internal structure of the model.
It only enforces a constraint on observable inference capability. This is analogous to: emissions regulation (measuring output, not engine design) network bandwidth limits (control flow, not protocol). This approach transforms privacy from a qualitative legal principle into a quantitative and enforceable constraint on inference. Privacy is no longer defined by data exposure, but by the difficulty of extracting knowledge.
This Framework is Regulator-Friendly

Connection to GDPR
The framework operates key GDPR principles:
a. Data Minimization [Solove 5-7] (Art. 5(1)(c)) - Instead of limiting raw data:Limit inference capability
b. Purpose Limitation (Art. 5(1)(b)) - Sensitive attributes cannot be inferred beyond allowed threshold:p≤p K
c. Privacy by Design [5-7] (Art. 25) - K becomes a design parameter: Systems must be engineered to satisfy impedance constraints.
d. Risk-Based Approach (Recital 75) - Risk is quantified as:"Risk∝p⇒Controlled via K
Connection to the EU AI Act
The EU AI Act emphasizes risk tiers (LLM / AI systems), prohibited uses ,high-risk system obligations The framework provides a missing quantitative layer [14]:
Mapping to AI Act
|
AI Act Concept |
DPP Interpretation |
|
Risk level |
p or Z |
|
Harm likelihood |
inference probability |
|
Mitigation |
increase K |
|
Compliance |
satisfy p≤p0 K |
Table 5: Mapping to AI Act
Example: High-risk AI system [14,17]: Must ensure K≥2 This translates to reduced inference capability, measurable compliance
Conceptual Shift (Key Contribution)
Traditional regulations: Control data access, The framework: Control knowledge flow
Closing Statement
The parameter transforms privacy from a qualitative legal principle into a quantitative, enforceable constraint on inference, enabling regulators to directly limit the rate at which systems convert data into knowledge. This approach aligns privacy regulation with physical analogies of impedance, allowing governance of information systems through measurable resistance to inference rather than indirect control over data handling practices.
Conclusion
This study advances the understanding of privacy in the age of Information and Communication Technologies (ICT) by demonstrating that privacy risk is fundamentally an inference problem rather than a disclosure problem [9,11]. Building on the Deep Personal Privacy (DPP) framework, we have shown that privacy can be rigorously modeled as impedance within an inference network, where semantic similarity in embedding space determines the ease with which sensitive information can be extracted
The originality of this work lies in bridging theory and practice: wemove from a formal definition of privacy as epistemic impedance to an empirical framework capable of quantifying and controlling inference risk in real-world AI systems. By introducing measurable relationships between cosine similarity, inference probability, and impedance, and by validating these relationships through numerical and empirical examples, this paper establishes a new foundation for privacy engineering. Furthermore, the introduction of the parameter K as a regulatory control variable provides a novel mechanism for aligning technical design with legal and ethical frameworks such as GDPR and the EU AI Act.
In contrast to traditional methods approaches that focus on limiting data exposure, the DPP framework directly constrains knowledge extraction [5-7,9,11]. This shift adds a critical new layer to privacy protection, addressing the growing challenge of inference in AI-driven environments. As such, the proposed framework not only enhances the theoretical landscape of privacy research but also provides actionable tools for building and regulating privacy-preserving systems in the ICT era.
References
- Schoeman, F. (1984). Privacy: philosophical dimensions.American Philosophical Quarterly, 21(3), 199-213.
- Laurie, G. (2002). Genetic privacy: a challenge to medico-legal norms. Cambridge University Press.
- Hongladarom, S. (2015). A Buddhist theory of privacy. In A buddhist theory of privacy (pp. 57-84). Singapore: Springer Singapore.
- Gavison, R. (1980). Privacy and the Limits of Law. The Yale law journal, 89(3), 421-471.
- Solove, D. J. (2010). Understanding privacy. Harvard university press.
- Nissenbaum, H. (2009). Privacy in context: Technology,policy, and the integrity of social life. In Privacy in context.Stanford University Press.
- Shannon, C. E. (1948). A mathematical theory of communication. The Bell system technical journal, 27(3), 379-423.
- Oppenheim, Y. (2024). Personal Privacy in the Age of the Internet: The Influence of Information and Communication Technologies on Personal Privacy. BookRix.
- Oppenheim, Y. (2026). Beyond Disclosure: Reframing Privacy as Inference Impedance in Large Language Models.
- https://www.reddit.com/r/breastcancer/comments/1dubiio/a_ positive_post_cancer_post/?utm_source=chatgpt.com
- Oppenheim, Y. (2026). Privacy as Epistemic Impedance: Deep Personal Privacy and the Political Economy of Knowledge in Networked Societies. Theory and Practice in Social Studies, 19-38.
- Sweeney, L. (2002). k-anonymity: A model for protecting privacy. International journal of uncertainty, fuzziness and knowledge-based systems, 10(05), 557-570.
- Machanavajjhala, A., Kifer, D., Gehrke, J., & Venkitasubramaniam, M. (2007). l-diversity: Privacy beyond k-anonymity. Acm transactions on knowledge discovery from data (tkdd), 1(1), 3-es.
- Li, N., Li, T., & Venkatasubramanian, S. (2007). “t-Closeness”, IEEE ICDE 2007
- Nissim, K (2020). “Differential Privacy: Why, How and Where to?” (2020)
- https://www.statice.ai/post/what-is-differential-privacy-definition mechanisms examples
- Kamath, U., Keenan, K., Somers, G., & Sorenson, S. (2024). Large language models: A deep dive. Bridging Theory and Practice, Cham: Springer Nature.