
Open Access Journal of Applied Science and Technology(OAJAST)
ISSN: 2993-5377 | DOI: 10.33140/OAJAST
Impact Factor: 1.08


Research Article - (2026) Volume 4, Issue 1
Quantum Algorithms for Large Language Models on Noisy Intermediate-Scale Quantum Computers
Received Date: Mar 02, 2026 / Accepted Date: Apr 07, 2026 / Published Date: Apr 10, 2026
Copyright: ©2026 Timo Aukusti Laine. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Laine, T. A. (2026). Quantum Algorithms for Large Language Models on Noisy Intermediate-Scale Quantum Computers. OA J Applied Sci Technol, 4(1), 01-13
Abstract
We present a systematic methodology for developing and validating quantum algorithms for Large Language Models (LLMs). This methodology includes partition function-based transformations to map LLM embedding similarity values to a range suit- able for quantum computation, and the design of a shallow-circuit quantum algorithm for estimating this transformed similarity measure on nearterm quantum computers. We rigorously evaluate our approach through quantum simulations and experiments on real quantum hardware, demonstrating the feasibility of using quantum computing for LLM embedding analysis. Our results highlight the potential for quantum-inspired techniques in LLM tasks and demonstrate practical strategies for achieving reliable results on noisy quantum hardware.
Introduction
Large Language Models (LLMs) have revolutionized natural language processing, fundamentally changing how machines understand and interact with human language. A key component of these models is the representation of textual data as high-dimensional embedding vectors, which capture complex semantic relationships between words, sentences, and documents. Quantum computing, leveraging principles like superposition and entanglement, offers a promising path towards accelerating critical LLM operations and unlocking new capabilities. To realize this potential, new quantum algorithms must be developed that are specifically tailored to the unique characteristics of quantum hardware. This necessitates new approaches to representing and manipulating LLM embeddings within a quantum framework to achieve enhanced performance. However, realizing quantum algorithms for LLMs on current noisy intermediate-scale quantum (NISQ) computers has specific requirements. These requirements include managing the cost of accessing quantum computing resources, addressing the difficulty of characterizing and mitigating noise with limited runs, and developing effective methods to transform LLM data into a format suitable for quantum circuit design, especially when dealing with negative values.
This paper addresses these challenges by introducing a systematic methodology for developing and validating quantum algorithms for LLMs, designed to facilitate progress in the era of quantum computing. Our key contributions are:
• A generalizable, systematic approach applicable to a wide range of quantum simulations.
• An initial problem transformation technique, including linear scaling and partition function-based methods, to create a system more amenable to quantum circuit design.
• A cost-effective validation strategy that begins with a toy example implemented on a quantum simulator, allowing for code verification and algorithm validation without incurring costs.
• Implementation of the same toy example on real quantum hardware to verify code correctness and gain insights into noise levels.
• Application of the validated quantum approach to a realistic LLM embedding problem.
Our methodology provides a rigorous, step-by-step process, starting with the identification of LLM tasks suitable for quantum acceleration and culminating in experimental validation on real quantum hardware. We emphasize practical considerations, such as techniques for ensuring reliable results, at each stage. As a concrete example, we present a partition function-based approach to transform LLM embedding similarity values into a positive range, enabling efficient encoding into quantum states. We then design and implement a shallow-circuit quantum algorithm to estimate this modified similarity measure, rigorously evaluating its performance through quantum simulations and experiments on the ibm pittsburgh quantum computer.
Background and Related Work
Large Language Models (LLMs) are driving rapid advancements in natural language processing, enabling breakthroughs in areas such as text generation, machine translation, and question answering [1,2]. These models, often based on the Transformer architecture, represent textual data as high-dimensional embedding vectors, capturing intricate semantic relationships between words, sentences, and entire documents [1,3,4]. Different embedding techniques exist, including contextualized word embeddings from models like BERT and sentence embeddings [5,6].
Training these massive LLMs requires significant computational resources, consuming vast amounts of energy and time. This motivates the exploration of alternative computational paradigms, such as quantum computing, which offers the potential for significant speedups for certain types of computations [7]. Quantum computing harnesses the principles of quantum mechanics, such as superposition and entanglement, to perform computations in a fundamentally different manner than classical computers [7]. Quantum algorithms like Grover’s search and quantum annealing have garnered significant attention for their potential to outperform classical counterparts in specific domains [8,9].
The application of quantum computing to LLMs is a nascent but promising field. Lots of work has been made to explore the connections between LLMs and quantum mechanics, drawing inspiration from quantum mechanical concepts to model semantic relationships and develop algorithms for natural language processing. Quantum Natural Language Processing (QNLP) provides a framework for representing language using quantum-inspired structures [10,11].
In previous work, we have explored the application of quantum formalisms to LLM semantic spaces [12-17]. Specifically, in Semantic Wave Functions: Exploring Meaning in Large Language Models Through Quantum Formalism, the analogy between LLM embedding spaces and quantum mechanics is explored, positing that LLMs operate within a quantized semantic space where words and phrases behave as quantum states [12]. The Quantum LLM: Modeling Semantic Spaces with Quantum Principles clarifies the core assumptions of a quantum-inspired framework for modeling semantic representation and processing in LLMs, providing a detailed exposition of key principles that govern semantic representation, interaction, and dynamics within LLMs [13]. Quantum LLMs Using Quantum Computing to Analyze and Process Semantic Information presents a quantum computing approach to analyzing LLM embeddings, leveraging complex-valued representations and modeling semantic relationships using quantum mechanical principles [14]. Discrete Semantic States and Hamiltonian Dynamics in LLM Embedding Spaces investigates the structure of LLM embedding spaces using mathematical concepts, particularly linear algebra and the Hamiltonian formalism, drawing inspiration from analogies with quantum mechanical systems [15]. Quantum Computation of Partition Function Similarity for Large Language Models introduces a framework for analyzing LLM embedding spaces using partition functions, drawing an analogy to statistical mechanics, and presents an experimental evaluation of its implementation on a quantum computer [16]. Quantum Hierarchy for Understanding LLM Representations by Modeling Linear Projections and Nonlinear Dynamics introduces a quantum framework to analyze LLM representations through a layered hierarchy of semantic spaces, modeling phenomena like semantic noise modulation and hallucination emergence using quantum mechanical analogues, and proposes a quantum circuit design for probing LLM embedding spaces [17].
This paper builds upon these foundations by introducing a systematic methodology for developing and validating quantum algorithms for LLMs, with a focus on addressing the challenges of noisy intermediate-scale quantum (NISQ) computers and ensuring the reliability of results through a comprehensive validation process [18]. We employ a partition function-based approach to transform similarity values, drawing inspiration from statistical mechanics, and design a shallow-circuit quantum algorithm for efficient implementation on near-term quantum hardware.
Structured Quantum Algorithm Design for Large Language Models
This section details a structured methodology for developing and validating quantum algorithms tailored for Large Language Models (LLMs). The process emphasizes a rigorous, step-by-step approach, designed to facilitate the effective translation of LLM challenges into quantum algorithms suitable for execution on current and near-term quantum computers. This systematic approach is crucial for maximizing the potential of quantum computing in the context of LLMs, while also addressing the realities of noisy intermediate-scale quantum (NISQ) hardware. The key is a process of careful problem selection, transformation, validation, and iterative refinement.
Problem Identification and Formulation
Identifying Quantum-Advantageous LLM Tasks
The initial step involves identifying specific LLM-related tasks where quantum computing’s unique capabilities, particularly its inherent parallelism and potential for algorithmic advances, can be effectively leveraged. The focus should be on problems where quantum algorithms offer a plausible path to improved performance compared to classical methods.
To demonstrate this process, we will use the task of triadic similarity analysis for semantic relationship discovery. This involves quantifying the relationships between LLM embeddings, a fundamental operation in many LLM applications. While this is just one example for illustrative purposes, it highlights the key considerations in selecting a suitable task. The goal is to identify core LLM operations that are computationally intensive and potentially amenable to quantum acceleration.
Beyond embedding similarity analysis, other LLM-related tasks can potentially benefit from quantum-accelerated similarity calculations. These include document similarity analysis, where similarity scores between document embeddings can reveal thematic relationships; quantum-enhanced recommendation systems, which can identify users with similar tastes by comparing their preference vectors; and quantum anomaly detection, which can flag outlier vectors, indicating anomalous data points, through low similarity scores. The systematic approach outlined here can also be applied to tasks such as optimization of model parameters, generation of text formats, and complex pattern recognition within large text corpora.
Transformation Approaches
A key challenge in applying quantum computing to LLM tasks involving similarity measures is representing these measures, which are often defined over a range of real numbers (including negative values), within the probabilistic framework of quantum computation. Quantum measurements inherently yield positive probabilities, derived from squared amplitudes. Therefore, transforming similarity measures to a positive range suitable for encoding into quantum states is often advantageous for efficient quantum implementation. This step focuses on exploring and applying such transformations.
To illustrate this, we start from the standard definition of cosine similarity

Vector b is L2 normalized and represents a normalized quantum state, while the squared norm of b′ is equal to SC′ , which lies between 0 and 1.
Transformation 2: Partition Function-Based Similarity
As an alternative, we assume that the components of the embedding vectors, ai and bi, can be interpreted as eigenvalues representing the energy levels of a system. This eigenvalue interpretation naturally

The key idea is that minimizing SZ corresponds to finding the most similar vectors in this transformed space. This stems from the exponential transformation exp(−βx), which assigns smaller values to larger x. Consequently, vectors sharing aligned positive components (e.g., ai = 1,bi = 1) will yield a smaller SZ, reflecting a notion of similarity based on shared ”low-energy” states. Conversely, aligned negative components (e.g., ai = −1,bi = −1) result in a larger SZ, as the partition function framework interprets shared absence or opposition as contributing to dissimilarity.
However, SZ differs from cosine similarity in a crucial way: it is sensitive not only to the relative alignment of vectors but also to their absolute position in the embedding space. For instance, identical vectors with components equal to +0.9 will yield a much smaller SZ than identical vectors with components equal to −0.9, even though both have a cosine similarity of 1. This is because SZ is rooted in a physical interpretation where embedding components represent energy levels, not just directional relationships.
The question is: what does a negative value in an embedding dimension mean? Cosine similarity implicitly assumes a directional relationship, where negative values represent opposing directions. However, if a negative value signifies the absence of a feature or an opposite characteristic, then the partition function approach offers a more nuanced perspective. In this case, two negative values indicate a shared absence or opposition, which decreases similarity, consistent with maximizing SZ. The partition function transformation provides a physical interpretation, mapping embedding vector components to energy levels in a statistical mechanical system. Therefore, cosine similarity and partition function-based similarity offer distinct perspectives on similarity, and their suitability depends on the specific context and the desired interpretation of the embedding vector components.
Experimentally determining which measure is “better” is challenging. For example, in Retrieval-Augmented Generation (RAG) systems, both methods typically return the top k results, but there is no definitive ground truth to assess which results are truly the most relevant. The choice of similarity measure ultimately depends on the specific application and the desired semantic properties.
Transformation 3: Linear Shift + Partition Function
To combine the benefits of both approaches and improve the numerical stability and performance of the quantum circuit, we can apply a linear shift before the partition function transformation. This ensures that the input to the exponential function is always positive.
We define a shifted vector a˜ such that a˜i = ai + C, where C is a constant chosen to make all components positive. A simple choice is C = 1, assuming that the components of a are greater than -1. We can then define the partition function using the shifted vector
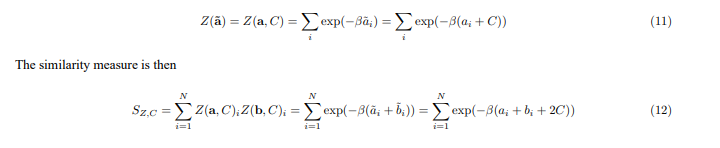
If we choose C = 1 and β is appropriately scaled, SZ,C can be constrained to be between 0 and 1. This combined approach leverages the physical interpretation of the partition function while ensuring that the values are suitable for quantum computation. This linear shift effectively translates the range of the input vector components. While it alters the absolute magnitude of the partition function values, it crucially preserves the relative order of similarity between different vector combinations. This means that if one set of vectors is more similar than another before the shift, their relative similarity ranking remains consistent after the shift. This preservation of relative order is often the primary concern in tasks like similarity search or clustering. For example, in the next section, when we discuss triadic similarity, this property ensures that the ranking of clustered similarities remains meaningful. Therefore, the practical advantages for quantum circuit implementation, such as ensuring positive amplitudes for encoding, often outweigh the consideration of altering the absolute values of the underlying system components in this context.
Applying Transformations to Triadic Similarity
In this step, we apply the transformations discussed earlier to the specific task of calculating triadic similarity, which is relevant to applications like clustered embedding analysis. We aim to obtain a similarity measure that is both meaningful and easily implementable in a quantum circuit. We start with the standard definition of cosine similarity for three vectors, known as triadic cosine similarity

Quantum Circuit Design
Quantum Circuit Design for Similarity Estimation
Having chosen the partition function-based similarity measure and the triadic similarity example, we now design a quantum circuit to estimate this measure. To estimate the similarity between N-dimensional embedding vectors a, b, and c using our partition function-based approach, we employ a quantum circuit consisting of three sets of N qubits, as illustrated in Figure 1. Each set of N qubits represents one of the vectors. While this circuit is designed for three vectors, the same principle can be extended to other similarity measures and to varying numbers of vectors. We denote ˜a = a + 1, b˜ = b + 1, and ˜c = c + 1. This circuit design demonstrates the encoding and measurement of individual terms on a quantum computer, but the summation across all N dimensions is still performed classically.

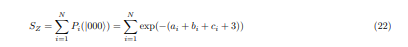
This circuit provides a simple and straightforward approach to estimating the similarity between LLM embeddings using quantum computation. This design, while relatively basic, serves as a foundation for exploring more complex quantum algorithms for LLM analysis.
Experimental Validation
Quantum Simulator Validation with a Toy Example
Before deploying our quantum circuit on real quantum hardware, a crucial step is to validate its theoretical correctness and implementation accuracy using a quantum simulator. While publicly available quantum computers boast an increasing number of qubits (up to 156 or more), their results can be significantly affected by noise and decoherence. Furthermore, the high cost of using these resources limits the ability to perform extensive troubleshooting and repeated trials. Therefore, we employ a quantum simulator to test our circuit in an idealized, noise-free environment. This allows us to verify the correctness of the quantum algorithm’s implementation in a fast and cost-efficient manner. Subsequent experiments on real quantum hardware then address a different research question: namely, how much noise affects the computation and whether the fidelity of current quantum hardware is sufficient to reproduce the results obtained with the simulator.
Our testing strategy involves creating a ”toy example” with low-dimensional embedding vectors. This toy example is designed to be simple enough to verify by hand, allowing for a direct comparison between theoretical calculations and simulation results. Specifically, in this case we consider three vectors with dimension N = 3. This results in a quantum circuit with only 9 qubits, a size easily handled by most quantum simulators. By using a quantum simulator, we can verify the correctness of our quantum circuit design, the accuracy of our code implementation, and the proper initialization of the quantum state.
We select the following arbitrary three vectors:

The relative error, calculated as |Stheoretical −Ssimulated|/Stheoretical, is approximately 3%. We can also study the effect of changing the number of shots. For example, in our example, if lowering the number of shots to 4096, the relative error is greater than 3%, and when it is, for example, 16384, the relative error is closer to 2%. This step allows us to isolate and eliminate potential errors in our theoretical understanding or code before proceeding to more expensive and complex experiments on real quantum hardware.
Real Quantum Hardware Validation with the Toy Example
Having validated our quantum circuit and code implementation using a quantum simulator, we now transition to testing on real quantum hardware. This step is crucial for assessing the impact of noise and decoherence on the accuracy of our results and for verifying the code on a real quantum platform. Due to the high cost of using real quantum computing resources, we recommend a two-part workflow: first, execute the quantum computation and save the raw results to a file; second, perform the result analysis in a separate script. This modular approach ensures that the quantum computation needs to be executed only once, optimizing the utilization of these comparatively expensive services.
We implement the same ”toy example” circuit with N = 3 (resulting in 9 qubits) on a publicly available quantum computer using the IBM Quantum cloud service. Our script selects the least busy backend, which in this case was ibm pittsburgh due to its availability and sufficient number of qubits. The code for running the quantum circuit and saving the results is provided in Appendix A3. The code for analyzing the saved results and calculating the triadic similarity is provided in Appendix A4. Note that the method for accessing the results from the quantum computer differs from the method used for the quantum simulator, as the real quantum computer requires accessing the results from the saved file.
We now use the same initial vectors Eqs. (23)-(25). When making the triadic similarity calculation with 8192 shots, and analyzing the results using the script in Appendix A4, we obtain the result

The relative error is approximately 7%. While further reruns could quantify the fluctuation of this relative error, this was not performed due to the high cost associated with service usage. The results indicate that the script functions correctly, with additional error attributable to hardware noise and decoherence effects.
Scaling to Realistic LLM Embeddings on Quantum Hardware
Having validated our approach with a toy example and characterized the performance of our quantum circuit on real hardware, we now scale up to a more realistic scenario using LLM embedding vectors. We consider three embedding vectors, a, b, and c, each with a dimension of N = 32. This requires a quantum circuit with a total of 96 qubits. The code used to generate these embeddings is detailed in Appendix A5.
Scaling quantum algorithms to larger problem sizes presents several challenges, including increased qubit requirements and the accumulation of noise. To address these challenges, we employ strategies such as circuit optimization, hardware-aware compilation, and the potential for error mitigation techniques.
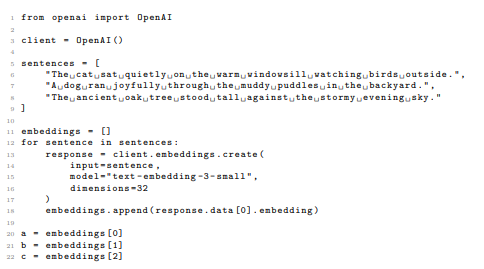
For this experiment, we use the OpenAI LLM model and 32-dimensional embeddings. OpenAI allows for the creation of 32-dimensional embeddings using their third-generation models through a feature called Matryoshka Representation Learning. Matryoshka Representation Learning allows for generating embeddings of varying dimensionality from a single model, which is useful for adapting to the limited number of qubits available on current quantum hardware. We select three sentences for this experiment:
1. Sentence: ”The cat sat quietly on the warm windowsill watching birds outside.”
2. Sentence: ”A dog ran joyfully through the muddy puddles in the backyard.”
3. Sentence: ”The ancient oak tree stood tall against the stormy evening sky.”
The sentences are chosen such that the first two (cat and dog) are semantically closer, both describing domestic animals engaged in everyday activities. The third sentence (oak tree) is semantically more distant, focusing on nature and weather. This selection provides a meaningful test where the calculated triadic similarity is expected to reflect the underlying semantic relationships between the sentences.
We execute the quantum script using the backend ibm pittsburgh with 8192 shots. The theoretical result is
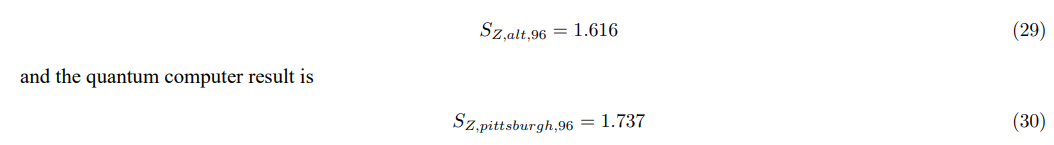
The relative error is 7.5%. Interestingly, the error in this 96-qubit calculation was not significantly larger than in the 9-qubit case. This suggests that, for this specific circuit design and on the ibm pittsburgh backend, the effects of noise do not increase dramatically with the number of qubits. This could be due to factors such as the relatively shallow circuit depth and the specific noise characteristics of the hardware. These results demonstrate the feasibility of scaling our approach to more realistic LLM embedding sizes on current quantum hardware.
Error Mitigation
Error Mitigation Strategies
The execution of quantum algorithms on noisy intermediate-scale quantum (NISQ) hardware inevitably introduces errors that can degrade the accuracy of results. To obtain reliable results from quantum computations, particularly as circuit depth and qubit count increase, error mitigation techniques offer the potential to significantly improve accuracy. Unlike full quantum error correction, which requires a large overhead of physical qubits, error mitigation aims to reduce the impact of noise on expectation values using classical post-processing or minor modifications to the quantum circuit, without requiring fault-tolerant hardware.
Several programmatic approaches exist for mitigating errors. Readout error mitigation addresses errors that occur during the measurement process by characterizing measurement errors and statistically correcting for them. Zero-Noise extrapolation (ZNE) involves running the quantum circuit at several artificially increased noise levels and then extrapolating to the theoretical zero-noise limit. Other techniques, such as dynamical decoupling, can also be used to suppress decoherence.
While these error mitigation techniques offer the potential to extract meaningful signals from NISQ devices, their application often incurs additional computational cost, either in terms of increased quantum circuit executions or classical post-processing. Due to the high cost associated with extensive quantum hardware usage, the present work focuses on demonstrating the feasibility of the proposed quantum algorithm and characterizing its performance without explicit error mitigation.
Conclusions
This work has presented a systematic methodology that streamlines the development and validation of quantum algorithms tailored for Large Language Models (LLMs), providing a practical roadmap for navigating the complexities of current quantum hardware and accelerating the exploration of quantum-enhanced LLM applications. Our approach is structured into distinct steps, beginning with the identification of LLM tasks where quantum computing can offer a potential advantage. This is followed by the crucial phase of transforming the problem into a format suitable for quantum computation, prioritizing circuit simplicity for efficient deployment on noisy intermediate-scale quantum (NISQ) devices. We introduced a new initial problem transformation technique, including linear scaling and partition function-based methods, to create a system more amenable to quantum circuit design.
A key aspect of our methodology involves a phased validation process. We first employ a toy model, rigorously tested on quantum simulators, to verify the theoretical correctness of the quantum circuit design and the accuracy of the code implementation. This allows us to gain an initial understanding of the expected error levels in an idealized environment. Subsequently, the same toy model is deployed on real quantum hardware. This step is vital for code verification on specific quantum platforms and for characterizing the impact of real-world noise and decoherence on the results. Once validated, the methodology guides the scaling of the quantum algorithm to address realistic LLM embedding problems.
A practical finding from our hardware experiments highlights the importance of a two-step computational strategy. To optimize the utilization of currently expensive quantum computing resources, we recommend separating the workflow: first, execute the quantum initialization and computation, saving the raw results; second, perform all subsequent analysis classically from the saved data. This minimizes the quantum processing unit (QPU) time, allowing for more extensive classical analysis without incurring repeated QPU costs.
Our results, demonstrating a consistent relative error of approximately 7% between quantum simulations and hardware executions for both small (9-qubit) and larger-scale (96-qubit) problems on the ibm pittsburgh backend, confirm the feasibility and effectiveness of this systematic approach. Importantly, we emphasize that the initial quantum simulator runs provide a fast and cost-effective way to verify the correctness of the algorithm’s implementation, while the subsequent hardware experiments serve to investigate the impact of noise and assess the fidelity of current quantum devices. This consistency suggests that, for the shallow-circuit design employed, the effects of noise do not significantly increase with qubit count on the tested hardware. Depending on the achieved accuracy and the specific application requirements, further enhancements can be pursued through the application of various error mitigation techniques, such as readout error mitigation or zero-noise extrapolation. This systematic framework provides a generalizable blueprint for tackling a wide array of LLM-related problems at the intersection of quantum computing and artificial intelligence, enabling the development of more powerful and efficient quantum-enhanced LLMs. Beyond the technical advancements, this work contributes to the broader effort of developing more efficient and sustainable AI technologies. Exploring quantum-enhanced LLMs allows us to aim to reduce the computational resources required for natural language processing, potentially leading to lower energy consumption and a reduced environmental footprint for AI applications.
Appendix A: Code Listings
1. Exact Cluster Similarity Calculation Code
Listing 1: Python code for calculating the exact cluster similarity.

2. Quantum Simulator Code
Listing 2: Qiskit code for quantum triadic similarity calculation using a quantum simulator

3. Real Hardware Code (Part 1): Quantum Computation and Result Saving
Listing 3: Qiskit code for quantum triadic similarity calculation on real quantum hardware - quantum computation and result saving.
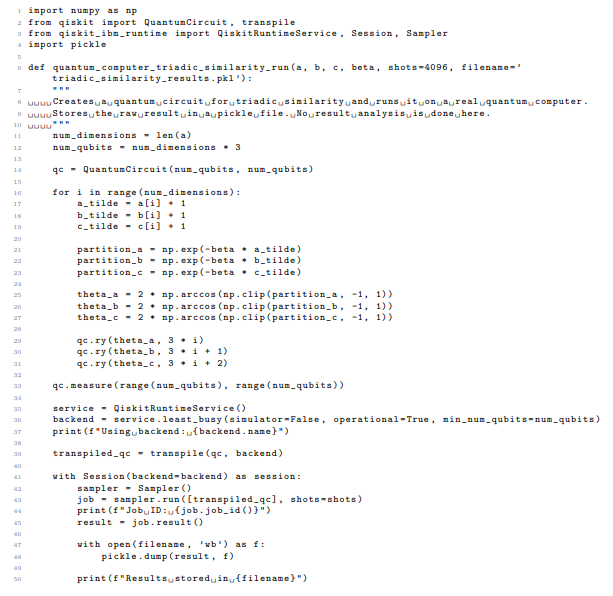
4. Real Hardware Code (Part 2): Result Analysis
Listing 4: Qiskit code for quantum triadic similarity calculation on real quantum hardware - result analysis.


5. OpenAI Embedding Generation Code
Listing 5: Python code for generating LLM embeddings using the OpenAI API.
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D.,Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013).Efficient Estimation of Word Representations in Vector Space.International Conference on Learning Representations.
- Pennington, J., Socher, R., & Manning, C. D. (2014, October). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532-1543).
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019, June). Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) (pp. 4171-4186).
- Reimers, N., & Gurevych, I. (2019, November). Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) (pp. 3982-3992).
- Nielsen, M. A., & Chuang, I. L. (2010). Quantum computation and quantum information. Cambridge university press.
- Grover, L. K. (1996, July). A fast quantum mechanical algorithm for database search. In Proceedings of the twenty-eighth annual ACM symposium on Theory of computing (pp. 212-219).
- Kadowaki, T., & Nishimori, H. (1998). Quantum annealing inthe transverse Ising model. Physical Review E, 58(5), 5355.
- Coecke, B., Sadrzadeh, M., & Clark, S. (2010). Mathematical foundations for a compositional distributional model of meaning. Lambek Festschirft, Special Issue of Linguistic Analysis, abs/1003.4394.
- Widdows, D., & Widdows, D. (2004). Geometry and meaning(Vol. 773). Stanford: CSLI publications.
- Laine, T. A. (2025). Semantic Wave Functions: Exploring Meaning in Large Language Models Through Quantum Formalism. OA J Applied Sci Technol, 3(1), 01-22.
- Laine, T. A. (2025). The Quantum LLM: Modeling Semantic Spaces with Quantum Principles. OA J Applied Sci Technol, 3(2), 01-13.
- Laine, T. A. (2026). Quantum LLMs Using Quantum Computing to Analyze and Process Semantic Information. OA J Applied Sci Technol, 4(1), 01-19.
- Laine, T. A. (2026). Discrete Semantic States and Hamiltonian Dynamics in LLM Embedding Spaces. OA J Applied Sci Technol, 4(1), 01-23.
- Laine, T. A. (2026). Quantum Computation of Partition Function Similarity for Large Language Models. OA J Applied Sci Technol, 4(1), 01-23.
- Laine, T. A. (2026). Quantum Hierarchy for Understanding LLM Representations by Modeling Linear Projections and Nonlinear Dynamics. OA J Applied Sci Technol, 4(1), 01-43.
- Preskill, J. (2018). Quantum computing in the NISQ era and beyond. Quantum, 2, 79.