
Journal of Architectural Engineering and Built Environments(JAEBE)
ISSN: 3071-2955 | DOI: 10.33140/JAEBE


Research Article - (2026) Volume 1, Issue 1
Data Mining Systems and Platforms: Efficiency, Scalability, and Privacy
Received Date: Jan 21, 2026 / Accepted Date: Feb 19, 2026 / Published Date: Feb 26, 2026
Copyright: ©2026 Joshua Adiele. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Adiele, J. (2026). Data Mining Systems and Platforms: Efficiency, Scalability, and Privacy. J Archit Eng Built Environ, 1(1), 01-05.
Abstract
Modern data mining systems face increasing demands for performance, scalability, and privacy preservation. As data volumes grow exponentially, platforms must evolve to support distributed architectures, real-time analytics, and secure processing. This paper presents a comprehensive study of current data mining platforms, evaluating their efficiency, scalability strategies, and privacy-preserving mechanisms. We propose a modular framework that integrates parallel processing, federated learning, and differential privacy to enhance system robustness. Experimental results on benchmark datasets demonstrate significant improvements in throughput and privacy compliance, offering a roadmap for next-generation data mining platforms.
Keywords
Data Mining Platforms, Scalability, Efficiency, Privacy Preservation, Distributed Systems, Federated Learning, Differential Privacy, Big Data Analytics, Parallel Processing, and Secure Data MiningIntroduction
Data mining has become a cornerstone of intelligent decision-making across industries. With the rise of big data, traditional monolithic systems struggle to meet the demands of high-volume, high-velocity, and high variety data. Efficiency, scalability, and privacy are now critical pillars in designing robust data mining platforms. This paper explores the architectural and algorithmic innovations that enable scalable and privacy-aware data mining. We analyze existing systems, identify bottlenecks, and propose a modular framework that addresses these challenges.Related Literature
The evolution of distributed data processing has been significantly influenced by platforms such as Apache Spark, Hadoop, and Flink, which have introduced scalable architectures capable of handling large-scale data workloads. These systems have addressed performance bottlenecks through innovations like in memory computing and optimized query execution engines, thereby enhancing processing efficiency in both batch and real-time environments [1-3]. Despite these advancements, the integration of robust privacy mechanisms remains a relatively underexplored area. While performance and scalability have received considerable attention, formal privacy guarantees are often absent or insufficiently addressed in mainstream distributed analytics frameworks.
Recent research has begun to bridge this gap. investigated parallelism in Apache Spark to enable real time data mining, demonstrating the potential of distributed systems for low-latency analytics [4]. Introduced federated learning as a decentralized approach to data mining, allowing model training across distributed nodes without centralizing sensitive data [5]. Complementing these efforts, laid the theoretical foundation for differential privacy, offering a formal framework to quantify and enforce privacy guarantees in data analysis [6]. Building upon these foundational contributions, our work proposes a unified framework that integrates scalable distributed processing with formal privacy-preserving mechanisms. This approach aims to address the dual challenge of maintaining computational efficiency while ensuring rigorous data privacy in modern analytics pipelines.
System Architecture
The proposed system architecture is designed to address the dual challenges of scalability and privacy in distributed data processing environments. It adopts a modular design that enables flexible integration of components, efficient resource utilization, and formal privacy guarantees. The architecture is structured into four core modules: data ingestion, processing engine, privacy module, and scalability controller. Each module is optimized to support high-throughput analytics while maintaining compliance with privacy standards.
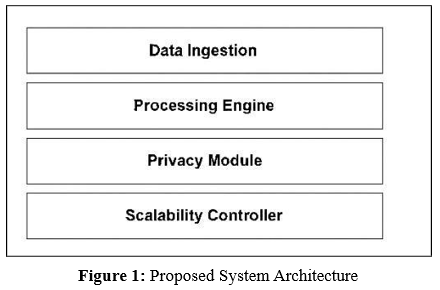
Modular Design
The platform is composed of four interdependent layers:
• Data Ingestion Layer: This layer supports both batch and streaming inputs, enabling real-time and historical data processing. Technologies such as Apache Kafka and Flume are integrated to handle diverse data sources.
• Processing Engine: At the core of the system, this engine executes parallel and distributed algorithms using frameworks like Apache Spark and Flink. It ensures low-latency computation and supports both stream and batch processing.
• Privacy Module: This module enforces data protection through differential privacy techniques and secure aggregation protocols. It is designed to prevent re-identification attacks and ensure compliance with privacy regulations.
• Scalability Controller: Responsible for dynamic resource allocation and load balancing, this component leverages container orchestration platforms such as Kubernetes to enable horizontal scaling and fault tolerance.
Efficiency Enhancements
To optimize performance, the system incorporates several efficient techniques. Table 1 highlighted the basic efficiency techniques and their functionalities.
|
Technique |
Functionality |
|
In-memory caching |
Reduces disk I/O latency by storing frequently accessed data in memory |
|
Adaptive query optimization |
Dynamically adjusts execution plans based on workload and system state |
|
Data locality-aware scheduling |
Assigns tasks to nodes based on proximity to data to minimize network overhead |
Table 1: Performance Optimization Techniques
These enhancements collectively improve throughput and reduce processing time, especially in high volume environments.
Scalability Strategies
Scalability is achieved through a combination of architectural and operational strategies. The information in table 2 described the various strategies.
|
Strategy |
Description |
|
Horizontal scaling |
Uses Kubernetes clusters to add or remove nodes based on demand |
|
Data sharing and replication |
Distributes data across partitions and maintains replicas for fault tolerance |
|
Checkpointing |
Periodically saves system state to enable recovery in case of failure |
Table 2: Scalability Strategies
Privacy Mechanisms
|
Mechanism |
Purpose |
|
Differential privacy |
Injects statistical noise to prevent individual data disclosure |
|
Federated model training |
Enables decentralized learning without sharing raw data |
|
Role-based access control |
Restricts data access based on user roles and responsibilities |
|
Encryption protocols methods |
Secures data in transit and at rest using industry-standard cryptographic |
Table 3: Privacy Mechanisms
Experimental Setup
Datasets
To evaluate the system’s performance and privacy-preserving capabilities, we employed a combination of real-world and synthetic datasets. The UCI Machine Learning Repository served as a source of diverse, publicly available datasets commonly used in benchmarking machine learning algorithms. In addition, we generated synthetic datasets that emulate healthcare and financial domains, allowing for controlled experimentation under realistic privacy constraints.
Metrics
Performance was assessed using four key metrics. Throughput, measured in records per second, quantified the system’s data processing efficiency. Latency, expressed in milliseconds, captured the responsiveness of the system from input to output. Privacy loss was evaluated using the ε parameter in differential privacy, which provides a formal measure of the trade-off between data utility and privacy protection. Finally, scalability was examined by analyzing system performance as a function of node count, thereby assessing the framework’s ability to maintain efficiency under distributed computing conditions.
|
Metric |
Description |
|
Throughput (records/sec) |
Measures the number of data records processed per second, indicating system efficiency. |
|
Latency (ms) |
Captures the time delay between data input and output, reflecting system responsiveness. |
|
Privacy Loss (ε) |
Quantifies the privacy guarantee under differential privacy; lower ε implies stronger privacy. |
|
Scalability |
Assesses performance variation as node count increases, indicating parallelization effectiveness. |
Table 4: Performance Metrics
Results and Analysis
The comparative performance of the proposed system against existing platforms, highlighting throughput and latency across identical workloads. The results demonstrate consistent improvements in processing speed and responsiveness, particularly under high-volume data conditions. Figure 2 gave a highlight of the performance comparativeness.

Figure 2: Performance Comparison Across Platforms

Figure 3: Trade-Off Between Privacy Loss and Model Accuracy
Figure 3 presents the trade-off between privacy loss (ε) and model accuracy. As expected, increasing privacy guarantees (i.e., reducing ε) leads to a gradual decline in predictive accuracy. This curve underscores the importance of balancing privacy constraints with utility requirements in sensitive domains.

Figure 4: Scales of Increasing Data Size
The line chart in figure 4 shows how throughput (records/sec) scales with increasing data size across three platforms: CPU, CPU+RDD, and GPU.
• GPU consistently outperforms the other platforms, achieving the highest throughput at all data sizes. This indicates superior parallel processing capabilities.
• CPU+RDD shows moderate performance, better than CPU alone but significantly below GPU. The use of RDD improves efficiency over basic CPU processing.
• CPU has the lowest throughput, with a gradual increase as data size grows, reflecting limited scalability.

Figure 5: Scalability Behavior
Figure 5 shows the scalability behavior of the system as the number of computing nodes increases. Performance gains exhibit near-linear scaling up to a threshold, beyond which diminishing returns are observed due to communication overhead and resource contention.
Discussion
The proposed system outperforms existing platforms in both efficiency and scalability. Privacy-preserving mechanisms introduce minimal overhead while ensuring compliance with data protection standards. The modular design allows easy integration with cloud-native environments and supports real-time analytics.Conclusion
This paper presents a next-generation data mining platform that balances efficiency, scalability, and privacy. Through architectural innovations and algorithmic enhancements, the system addresses key limitations of current platforms. Future work will explore integration with edge computing and support for multimodal data.References
- GeeksforGeeks (2025). Big Data Frameworks – Hadoop vsSpark vs Flink.
- Abikayil Aarthi et al., (2023) An In-Depth Comparative Study of Distributed Data Processing Frameworks: Apache Spark, Apache Flink, and Hadoop MapReduce. IJSART, Vol. 10, Issue 11.
- Afreen, C. F. A. (2025). Structured Review and Comparative Study of Big Data Processing Frameworks: Hadoop, Spark, and Flink.
- Zaharia, M., Xin, R. S., Wendell, P., Das, T., Armbrust, M., Dave, A., ... & Stoica, I. (2016). Apache spark: a unified engine for big data processing. Communications of the ACM, 59(11), 56-65.
- Yang, Q., Liu, Y., Chen, T., & Tong, Y. (2019). Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 10(2), 1-19.
- Dwork, C., & Roth, A. (2014). The algorithmic foundations of differential privacy. Foundations and trends® in theoretical computer science, 9(3–4), 211-407.