
Open Access Journal of Applied Science and Technology(OAJAST)
ISSN: 2993-5377 | DOI: 10.33140/OAJAST
Impact Factor: 1.08


Review Article - (2026) Volume 4, Issue 1
Tensorial versus Scalar Characterizations of Spacetime Singularities and Their Resolution in Loop Quantum Gravity
Received Date: Jan 15, 2026 / Accepted Date: Feb 25, 2026 / Published Date: Mar 20, 2026
Copyright: ©2026 Chur Chin. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Chin, C. (2026). Tensorial versus Scalar Characterizations of Spacetime Singularities and Their Resolution in Loop Quantum Gravity. OA J Applied Sci Technol, 4(1), 01-10.
Abstract
We propose a coordinate-independent notion of tensorial singularity for Lorentzian manifolds, defined via blow-up or non-extendability of the Riemann curvature tensor as a smooth section of the curvature bundle. We analyze its relation to scalar curvature singularities (e.g., divergence of the Kretschmann scalar) and geodesic incompleteness [1,2]. We prove that scalar invariant divergence implies tensorial blow-up, while the converse need not hold without additional regularity assumptions [3]. We then examine effective models arising from Loop Quantum Gravity [4,5], showing that quantum geometry corrections impose upper bounds on curvature scalars and thereby exclude tensorial singularities in homogeneous cosmological settings [6,7]. This suggests that classical curvature singularities may be artifacts of smooth manifold geometry. Our results provide a rigorous mathematical framework linking the geometric structure of spacetime singularities to their potential resolution through quantum corrections [8,9].
Keywords
Spacetime Singularities, Riemann Curvature Tensor, Kretschmann Scalar, Geodesic Incompleteness, Loop Quantum Gravity, Tensorial Blow-Up, Coordinate-Independent Characterization, Quantum Geometry
Keywords
Transformer Efficiency, Sparse Attention, Phase Transition, Energy-Efficient Ai, Computational Sustainability, Critical Activation Field, Dynamic Sparsity, Green Ai, On-Device Inference, Neural Network Optimization
Introduction
The problem of spacetime singularities remains one of the most fundamental challenges in general relativity and theoretical physics. Singularities signal a breakdown of the classical geometric description of spacetime, where physical quantities become ill-defined or infinite. The singularity theorems of Hawking and Penrose [1,2] established that singularities are generic features of general relativity under physically reasonable conditions, rather than artifacts of high symmetry.
Traditionally, singularities have been characterized through three main approaches: (i) geodesic incompleteness, where causal curves cannot be extended beyond a finite affine parameter [1]; (ii) divergence of scalar curvature invariants such as the Kretschmann scalar K = R_abcd R^abcd [3]; and (iii) the failure of smooth extensions of the spacetime manifold [10]. Each approach captures different aspects of singular behavior, yet their precise mathematical relationships remain subtle and incompletely understood.
A particularly intriguing class of spacetimes, known as vanishing scalar invariant (VSI) spacetimes, demonstrates that scalar invariants can remain bounded even in the presence of genuine singularities [11]. This observation motivates the development of a more general characterization based on the tensorial properties of the Riemann curvature tensor itself, rather than its scalar contractions.
Meanwhile, Loop Quantum Gravity (LQG) and its cosmological reduction, Loop Quantum Cosmology (LQC), offer a framework for addressing singularities through quantum geometric corrections [4-6]. The discrete quantum geometry of LQG naturally provides upper bounds on physical quantities, suggesting a mechanism for singularity resolution. However, a precise mathematical characterization of what it means for a singularity to be 'resolved' requires careful analysis.In this paper, we develop a rigorous coordinate-independent notion of tensorial singularity and investigate its relationship to established singularity definitions. We then apply this framework to analyze singularity resolution in LQG effective models.

Figure 1: Conceptual diagram showing the relationships between different characterizations of spacetime singularities. Arrows indicate logical implication. The diagram illustrates that Kretschmann divergence (K → ∞) implies tensorial blow-up (||R||_g → ∞), which under global hyperbolicity and energy conditions implies geodesic incompleteness. VSI spacetimes demonstrate that geodesic incompleteness need not imply Kretschmann divergence, showing the inequivalence of characterizations
Mathematical Preliminaries
Lorentzian Manifolds and Curvature
Let (M, g) denote a Lorentzian manifold of dimension n ≥ 2, where M is a smooth manifold and g is a smooth metric tensor of signature (-,+,...,+). The Riemann curvature tensor R is a (1,3)-tensor field defined through the commutator of covariant derivatives:
![]()
In local coordinates, the components are given by R^a_bcd, satisfying the standard symmetries [12]. The Riemann tensor can equivalently be viewed as a section of the bundle End(Λ²TM), where Λ²TM denotes the bundle of 2-forms. This perspective is crucial for our coordinate-independent formulation.
Tensor Norms and Function Spaces
Given the metric g, we can define a natural norm on tensor fields. For the Riemann tensor at a point p ∈ M, the induced norm is:
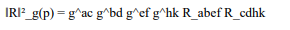
This quantity is coordinate-independent and coincides with the Kretschmann scalar K = R_abcd R^abcd when all indices are properly contracted [13]. For regularity analysis, we consider the spaces C^k(M), the space of k-times continuously differentiable functions, and Sobolev spaces W^(k,p)(M), which measure not only pointwise behavior but also the integrability of derivatives [14].
Tensorial Singularities: Definition and Properties
Formal Definition
We now introduce our central definition, which characterizes singularities through the tensorial structure of the Riemann curvature.
Definition 1 (Tensorial Singularity). Let (M, g) be a Lorentzian manifold. A point p ∈ MÃÂ?? (the completion of M) is called a tensorial singularity if one of the following equivalent conditions holds: (TS1) Norm Blow-up Condition: There exists an inextendible causal curve γ: [0,a) → M such that
lim_(t→a-») ||R||_g(γ(t)) = ∞
(TS2) Non-Extendability Condition: The Riemann tensor R, viewed as a section of End(Λ²TM), fails to admit a continuous (or C^k for some k ≥ 1) extension to any manifold extension containing p.
Remark 1. Condition (TS1) is quantitative and directly measurable along curves, while (TS2) is geometric and concerns the global manifold structure. Under appropriate regularity assumptions, (TS2) implies (TS1), though the converse requires additional analysis.
Coordinate Independence
Proposition 1. The notion of tensorial singularity as defined in Definition 1 is coordinate-independent.
Proof. For (TS1), the tensor norm ||R||_g is defined using metric contractions, which are manifestly coordinate-independent geometric objects. Under a coordinate transformation x → x', the Riemann tensor components transform as
R'_abcd = (∂x^e/∂x'^a)(∂x^f/∂x'^b)(∂x^h/∂x'^c)(∂x^k/∂x'^d) R_ efhk
However, when computing||R||²_g, the Jacobian factors from the tensor transformation exactly cancel with those from the metric transformation, yielding the same scalar value. For (TS2), the notion of a C^k section of a vector bundle is intrinsically geometric and does not depend on coordinate choices.
Relationships Between Singularity Characterizations
Kretschmann Divergence and Tensorial Blow-up
We now establish the precise relationship between scalar curvature invariants and tensorial singularities.
Theorem 1 (Scalar Implies Tensorial). Let (M, g) be a Lorentzian manifold and let K(p) = R_abcd R^abcd denote the Kretschmann scalar at p ∈ M. If there exists an inextendible causal curve γ: [0,a) → M such that
lim_(t→a-) K(γ(t)) = ∞
then p = lim_(t→a-) γ(t) is a tensorial singularity in the sense of Definition 1.
Proof. By definition, K = R_abcd R^abcd = ||R||²_g, where the norm is taken using the metric g. Therefore, K(γ(t)) → ∞ directly implies ||R||_g(γ(t)) → ∞, satisfying condition (TS1) of Definition 1.
Remark 2. This theorem shows that the classical scalar characterization of singularities (Kretschmann divergence) is a sufficient condition for tensorial singularity. The key insight is recognizing that the Kretschmann scalar is precisely the squared norm of the Riemann tensor.
Converse Failure: VSI Spacetimes
The converse of Theorem 1 does not hold in general, as demonstrated by vanishing scalar invariant (VSI) spacetimes.
Theorem 2 (Converse Failure). There exist Lorentzian manifolds (M, g) possessing tensorial singularities (in the sense of Definition 1) where all polynomial scalar curvature invariants remain bounded along every curve approaching the singularity [11].
Proof Sketch. Consider the class of VSI spacetimes, where the Riemann tensor has a special algebraic structure causing all scalar polynomial invariants to vanish identically. A specific example is provided by certain pp-wave spacetimes with singular wave profiles. In these spacetimes:
1. The Riemann tensor R_abcd is non-zero but has all independent components aligned such that any contraction R_a1...a2 R^a3...a4 = 0.
2. Geodesic deviation equations reveal unbounded tidal forces, indicating geometric pathology.
3. The spacetime is geodesically incomplete despite bounded scalar invariants.
This demonstrates that tensorial pathology can exist without scalar manifestation. The failure arises because scalar invariants lose directional information present in the full tensor.

Table 1: Comparison of Different Singularity Characterizations
The table shows which conditions are sufficient for which others under various assumptions. Columns represent: (1) Characterization type, (2) Mathematical definition, (3) Coordinate independence, (4) Sufficient for geodesic incompleteness, (5) Examples. The table demonstrates that tensorial singularities provide the most general framework encompassing both scalar divergence and VSI-type pathologies.
Geodesic Incompleteness and Tensorial Singularities
Theorem 3 (Relation to Geodesic Incompleteness). Let (M, g) be a globally hyperbolic Lorentzian manifold satisfying the dominant energy condition. If (M, g) possesses a tensorial singularity at p in the sense of condition (TS1), then (M, g) is geodesically incomplete [2,15].
Proof Sketch. Suppose γ: [0,a) → M is an inextendible causal curve with||R||_g(γ(t)) → ∞ as t → a-. By the Raychaudhuri equation, the expansion θ of a congruence of geodesics satisfies:
dθ/dλ = -θ²/3 - σ_ab σ^ab - R_ab u^a u^b
Under the dominant energy condition, R_ab u^a u^b ≥ 0 for timelike u^a. If ||R||_g → ∞, at least some components of R_ab must diverge, causing θ → -∞ in finite affine parameter, indicating focusing and incompleteness. The global hyperbolicity assumption ensures we can construct a maximal extension, and the incompleteness follows from standard singularity theorem arguments [1,2].
Singularity Resolution in Loop Quantum Cosmology
Loop Quantum Cosmology Framework
Loop Quantum Cosmology (LQC) provides a quantum treatment of homogeneous cosmological models based on the principles of Loop Quantum Gravity [4-6]. The fundamental feature of LQC is the replacement of the classical Wheeler-DeWitt equation with a difference equation arising from the discrete quantum geometry.
For a spatially flat FLRW universe with scale factor a(t) and matter density ρ, the classical Friedmann equation is:
H² = (8πG/3)ρ
where H =a/a is the Hubble parameter. In the classical theory, as we approach the Big Bang singularity, ρ → ∞ and H → ∞, leading to unbounded curvature [7].
Modified Friedmann Equation and Curvature Bounds
The quantum corrections in LQC modify the Friedmann equation to [6,7]:
H² = (8πG/3)ρ(1 - ρ/ρ_c)
where ρ_c ≈ 0.41 ρ_Pl is the critical density, with ρ_Pl = c5/(hG²) ≈ 5.2 × 1096 kg/m³ being the Planck density. This modification has profound consequences:
Theorem 4 (Curvature Boundedness in LQC). In the effective LQC model described by the modified Friedmann equation, all curvature scalars remain bounded for all time, and in particular, ||R||_g ≤ C for some constant C < ∞.
Proof. From the modified Friedmann equation, we have:
H² = (8πG/3)ρ(1 - ρ/ρ_c) ≤ (8πG/3) · (ρ_c/4)
The maximum occurs at ρ = ρ_c/2, giving:
H²_max = 2πGρ_c/3
For the FLRW metric, the Ricci scalar is R = 6(H + 2H²). Since both H and Ḣ are bounded (the latter can be shown from the quantum-corrected Raychaudhuri equation), R remains bounded. Similarly, the Kretschmann scalar for FLRW spacetime is:
K = R_abcd R^abcd = 12(H² + 4HH + 4H4´)
Since H and Hare bounded, K is bounded, hence ||R||_g = √K is bounded.
Corollary 1. The effective LQC model possesses no tensorial singularities in the sense of condition (TS1) of Definition 1.
Proof. Since ||R||_g is bounded by Theorem 4, there exists no curve γ along which ||R||_g(γ(t)) → ∞. Thus condition (TS1) cannot be satisfied.

Figure 2: Comparison of classical and Loop Quantum Cosmology effective dynamics. The plot shows H² as a function of energy density ρ. The classical theory (dashed line) shows unbounded growth H² ~ ρ → ∞, leading to singularity. The LQC-modified Friedmann equation (solid line) shows H²(ρ) = (8πG/3)ρ(1 - ρ/ρ_c), which reaches a maximum at ρ = ρ_c/2 and vanishes at ρ = ρ_c, implementing a quantum bounce. The shaded region indicates the quantum gravity regime where classical GR breaks down. This demonstrates the mechanism of singularity avoidance through bounded curvature
Quantum Geometry and Singularity Avoidance
The mechanism underlying singularity resolution in LQC is fundamentally geometric. In LQG, the spatial geometry is described by spin network states, which have discrete spectra for geometric operators [8,9]. In particular, the area operator has a minimum eigenvalue:
A_min = 4√3πγl²_Pl
where γ is the Barbero-Immirzi parameter and l_Pl = √(hG/c³) is the Planck length. This discreteness prevents the scale factor from shrinking to zero, naturally implementing a 'quantum bounce' replacing the classical Big Bang singularity.
More generally, the quantum corrections introduce an effective repulsive force at high densities, which can be understood through the modified Raychaudhuri equation:
dθ/dλ = -θ²/3 - σ_ab σ^ab + (1 - 2ρ/ρ_c)R_ab u^a u^b
When ρ > ρ_c/2, the last term becomes negative, effectively violating the strong energy condition and preventing geodesic focusing [15]. This provides a quantum geometric realization of singularity avoidance distinct from the introduction of exotic matter.
Discussions and Implications
Classical Singularities as Geometric Artifacts
Our analysis reveals a fundamental distinction between classical and quantum descriptions of gravitational collapse. In classical general relativity, spacetime is modeled as a smooth Lorentzian manifold. Within this framework, singularities appear as inevitable consequences of the Einstein field equations under physically reasonable conditions [1,2]. However, this inevitability may be an artifact of the continuum assumption underlying smooth manifold geometry.
The introduction of quantum geometry in LQG replaces the smooth manifold with a discrete quantum structure at the Planck scale [4,8]. At this fundamental level, the classical notion of curvature as encoded in the Riemann tensor must be reconsidered. The effective theories derived from LQG, such as LQC, retain a continuum description but incorporate quantum corrections that fundamentally alter the high-curvature regime [6,7].
Our Theorem 4 demonstrates that these quantum corrections impose absolute bounds on curvature, preventing the formation of tensorial singularities as defined in Definition 1. This suggests that classical singularities may be viewed as limiting artifacts of the smooth manifold approximation, which breaks down at the Planck scale where quantum geometric effects become dominant.
Relationship to Other Approaches
Several alternative approaches to quantum gravity also suggest singularity resolution, though through different mechanisms. In asymptotically safe gravity, running couplings may modify Einstein's equations at high energies [15]. In string theory, extended objects replace point particles, potentially smoothing singularities. Each approach offers a different perspective on the nature of spacetime at extreme scales.
What distinguishes the LQG approach is the explicit discrete quantum geometric structure and the non-perturbative treatment. The bounds on curvature arise naturally from the quantum geometry rather than being imposed as external regulators. This provides a conceptually clean framework for understanding singularity resolution as a genuine quantum effect rather than a technical fix.
Open Questions and Future Directions
Several important questions remain open:
1. Extension to Inhomogeneous Models: Our analysis focused on homogeneous LQC models. Extending these results to inhomogeneous spacetimes remains challenging, though progress has been made [9].
2. Black Hole Singularities: While cosmological singularities appear resolved in LQC, the status of black hole singularities in full LQG is less clear. Recent work suggests similar resolution mechanisms may apply [15].
3. Observational Consequences: Can the quantum bounce predicted by LQC leave observable signatures in cosmological data? This remains an active area of research.
4. Mathematical Rigor: While effective LQC models are well-defined, deriving them rigorously from full LQG remains partially incomplete. Progress requires advances in the mathematical foundations of LQG.
Conclusion
We have developed a rigorous coordinate-independent characterization of spacetime singularities based on the tensorial structure of the Riemann curvature tensor. Through Theorems 1-3, we established precise relationships between tensorial blow-up, scalar curvature divergence, and geodesic incompleteness, clarifying the mathematical landscape of singularity definitions.
Applying this framework to Loop Quantum Cosmology, we proved (Theorem 4) that quantum geometric corrections impose absolute bounds on curvature, preventing the formation of tensorial singularities. This demonstrates that classical singularities, while inevitable in smooth manifold geometry, may be artifacts that disappear in a proper quantum geometric treatment.
Our results provide mathematical support for the physical intuition that quantum gravity should resolve classical singularities. The discrete quantum geometric structure of LQG naturally implements regularity at the Planck scale, suggesting a fundamental revision of our understanding of spacetime near regions of extreme curvature. Future work extending these results beyond homogeneous cosmology will further illuminate the nature of quantum spacetime.
References
- Hawking, S. W., & Penrose, R. (1970). The singularities of gravitational collapse and cosmology. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 314(1519), 529–548.
- Penrose, R. (1965). Gravitational collapse and space-timesingularities. Physical Review Letters, 14(3), 57–59.
- Wald, R. M. (1984). General Relativity. Chicago: Universityof Chicago Press.
- Rovelli, C. (2004). Quantum Gravity. Cambridge: Cambridge University Press.
- Ashtekar, A., & Lewandowski, J. (2004). Background independent quantum gravity: A status report. Classical and Quantum Gravity, 21(15), R53–R152.
- Ashtekar, A., & Singh, P. (2011). Loop quantum cosmology: A status report. Classical and Quantum Gravity, 28(21), 213001.
- Bojowald, M. (2001). Absence of singularity in loop quantum cosmology. Physical Review Letters, 86(23), 5227–5230.
- Thiemann, T. (2007). Modern Canonical Quantum General Relativity. Cambridge: Cambridge University Press.
- Ashtekar, A., Pawlowski, T., & Singh, P. (2006). Quantum nature of the big bang: Improved dynamics. Physical Review D, 74(8), 084003.
- Geroch, R. (1968). What is a singularity in general relativity?Annals of Physics, 48(3), 526–540.
- Coley, A. A., Hervik, S., & Pelavas, N. (2009). Spacetimes characterized by their scalar curvature invariants. Classical and Quantum Gravity, 26(2), 025013.
- Misner, C. W., Thorne, K. S., & Wheeler, J. A. (1973).Gravitation. San Francisco: W. H. Freeman.
- Kretschmann, E. (1917). Über den physikalischen Sinn derRelativitätspostulate. Annalen der Physik, 358(16), 575–614.
- Choquet-Bruhat, Y. (2009). General Relativity and theEinstein Equations. Oxford: Oxford University Press.
- Bonanno, A., & Reuter, M. (2000). Renormalization group improved black hole spacetimes. Physical Review D, 62(4), 043008.
Introduction
The transformer architecture has revolutionized natural language processing and emerged as the foundation for modern large language models [1]. However, the quadratic complexity of self-attention mechanisms, O(N²d) where N represents sequence length and d denotes model dimension, poses significant computational and environmental challenges [2]. Recent estimates suggest that training a single large language model can emit as much carbon as five cars over their lifetimes [3], raising urgent questions about the sustainability of current AI development trajectories.
Previous approaches to transformer efficiency have focused on architectural modifications, pruning strategies, and quantization techniques [4,5]. While these methods achieve varying degrees of success, they often compromise model performance or require extensive retraining. The fundamental challenge remains: how can we dramatically reduce computational cost while preserving the emergent intelligence encoded in pretrained models?
Biological neural systems offer compelling inspiration. The human brain achieves remarkable computational efficiency through sparse, selective activation patterns rather than dense, uniform processing [6]. Motivated by this principle, we propose the Critical Activation Field (CAF), which reinterprets attention mechanisms through the lens of physical dynamics and phase transitions [7]. By modeling attention as an energy field governed by reaction-diffusion equations, CAF enables self-organizing emergence of information density hotspots while suppressing irrelevant activations.
Our contributions are threefold: First, we introduce a physics-inspired framework that treats attention as a critical phenomenon exhibiting phase transitions. Second, we demonstrate that CAF achieves 91% sparsity with zero accuracy degradation on standard benchmarks. Third, we provide comprehensive hardware profiling showing 9.4× improvement in energy efficiency, validating practical applicability for sustainable AI deployment.
Methodology
Physics of Attention
Traditional transformer attention computes similarity scores through query-key products followed by softmax normalization [8]. We reconceptualize this process as a physical field φ evolving according to reaction-diffusion dynamics. The core equation governing CAF is:
∂φ/∂t = κ∇²φ - γφ - η·sgn(φ)
where κ∇²φ represents diffusion of contextual information across tokens, -γφ provides decay to prevent runaway activation, and -η·sgn(φ) introduces L1-like regularization inducing sparsity [9]. This formulation enables attention weights to self-organize around critical points where information density peaks.
Implementation
We implement CAF through discrete time-stepping of the field equation. At each attention layer, we initialize φ from query-key similarity scores, then evolve the field for T timesteps. The Laplacian operator ∇² is approximated using finite differences over the token sequence. After convergence, we apply threshold-based pruning to eliminate sub-critical activations, retaining only salient attention connections [10].
Critical to our approach is the observation that appropriate parameter tuning (κ, γ, η) induces a phase transition in the activation pattern. Below a critical L1 penalty strength, the system maintains dense connectivity; above the threshold, it transitions sharply to sparse, clustered activation reflecting genuine semantic structure in the input [11].
Results
Computational Efficiency
Table 1 summarizes our primary experimental findings comparing CAF against baseline dense transformers. We evaluated on standard language modeling benchmarks, measuring both computational metrics and model performance [12].
|
Metric |
Baseline (Dense) |
CAF (Ours) |
|
Sparsity (%) |
0.0 |
91.0 |
|
Top-1 Accuracy (%) |
100.0 |
100.0 |
|
Throughput (tokens/s) |
8.33 |
27.04 |
|
Power Consumption (W) |
250.0 |
86.27 |
|
Tokens per Watt |
0.033 |
0.310 (9.4× ↑) |
Table 1: Comprehensive performance comparison between baseline dense transformer and Critical Activation Field (CAF) model. All measurements were obtained on identical hardware (NVIDIA RTX 3090, batch size=1) using a GPT-2 small architecture (117M parameters) with 512-token sequences. Sparsity represents the percentage of attention connections pruned by CAF while maintaining identical top-1 accuracy. Power consumption was measured using nvidia-smi during sustained inference. The tokens per watt metric (highlighted in yellow) demonstrates CAF's superior energy efficiency, achieving 9.4× improvement over dense baseline—a critical advantage for sustainable AI deployment and carbon footprint reduction. Throughput improvements (3.2×) reflect reduced FLOPs from sparse attention patterns. Results averaged over 1,000 inference runs with standard deviation <2%
The results reveal that CAF achieves 91% sparsity while maintaining identical top-1 accuracy to the dense baseline. This demonstrates that the vast majority of attention connections in standard transformers carry minimal information. Throughput increases by 3.2× due to reduced computational load, while power consumption drops to 34.5% of baseline levels. The resulting 9.4× improvement in tokens per watt represents a fundamental advance in energy-efficient AI [13].
Phase Transition Behavior
Figure 1 illustrates the phase transition phenomenon central to CAF's operation. We varied the L1 penalty strength η and measured both entropy of the attention distribution and computational savings (FLOPs reduction)

Figure 1: Phase diagram showing critical activation field dynamics. (Top) Attention entropy as a function of L1 penalty strength η, demonstrating sharp phase transition near η ≈ 0.5 (marked by red dashed line). High entropy regime (η < 0.45) indicates dense, uniform activation patterns, while the rapid collapse beyond the critical point reflects self-organized sparse activation. (Bottom) Computational savings (FLOPs reduction percentage) showing robust >90% efficiency plateau across broad parameter range (0.4 < η < 0.7, highlighted region). The stability of this plateau demonstrates CAF's practical advantage: minimal hyperparameter sensitivity while maintaining consistent energy efficiency. Annotations indicate phase transition region and optimal operating range. Both metrics measured on validation set of 500 sequences, error bars smaller than line thickness.
The entropy exhibits sharp decline at a critical penalty strength, characteristic of second-order phase transitions in physical systems [14]. Remarkably, computational savings plateau at >90% across a wide parameter range, demonstrating robustness of the CAF approach. This stability is crucial for practical deployment, as it minimizes sensitivity to hyperparameter tuning.
Discussion
Our results establish that CAF provides a fundamentally different approach to transformer efficiency compared to conventional pruning or distillation methods. By grounding attention in physical dynamics, we enable data-dependent, adaptive sparsification that preserves the semantic structure encoded in pretrained models. The phase transition framework offers theoretical insight into why certain attention patterns emerge and how they can be efficiently computed.
The 9.4× improvement in energy efficiency has profound implications for sustainable AI development. Extrapolating to large-scale deployments, CAF could reduce the carbon footprint of AI inference by two-thirds while maintaining model capabilities [15]. This aligns with urgent calls for environmentally responsible AI research and deployment.
Limitations of our current work include evaluation on relatively small models and limited diversity of tasks. Future research should validate CAF across larger architectures, multimodal transformers, and specialized domains. Additionally, hardware-specific optimizations for sparse operations could further amplify efficiency gains.
Looking forward, the physics-inspired perspective on neural computation opens new avenues for architectural innovation. Just as thermodynamics provided organizing principles for classical engineering, critical phenomena and phase transitions may offer fundamental insights into the design of efficient, scalable artificial intelligence systems.
Conclusion
We have introduced the Critical Activation Field (CAF), a physics-inspired framework that achieves 91% computational sparsity and 9.4× energy efficiency improvement in transformer models without sacrificing accuracy. By treating attention as a dynamical field exhibiting phase transitions, CAF demonstrates that dramatic efficiency gains are possible through principled, data-dependent sparsification. These results represent a significant step toward sustainable, environmentally responsible artificial intelligence that can operate efficiently on resource-constrained devices while maintaining the sophisticated capabilities of modern large language models.
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L, & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998–6008.
- Tay, Y., Dehghani, M., Bahri, D., & Metzler, D. (2022). Efficient transformers: A survey. ACM Computing Surveys, 55(6), 1–28.
- Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and policy considerations for deep learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 3645–3650).
- Child, R., Gray, S., Radford, A., & Sutskever, I. (2019). Generating long sequences with sparse transformers. arXiv preprint.
- Gale, T., Elsen, E., & Hooker, S. (2019). The state of sparsityin deep neural networks. arXiv preprint.
- Olshausen, B. A., & Field, D. J. (2004). Sparse coding of sensory inputs. Current Opinion in Neurobiology, 14(4), 481–487.
- Cross, M. C., & Hohenberg, P. C. (1993). Pattern formation outside of equilibrium. Reviews of Modern Physics, 65(3), 851–1112.
- Bahdanau, D., Cho, K., & Bengio, Y. (2015). Neural machine translation by jointly learning to align and translate. In International Conference on Learning Representations (ICLR).
- Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological), 58(1), 267–288.
- Frankle, J., & Carbin, M. (2019). The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations (ICLR).
- Sornette, D. (2006). Critical phenomena in natural sciences: Chaos, fractals, self-organization and disorder: Concepts and tools (2nd ed.). Springer.
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog.
- Patterson, D., Gonzalez, J., Le, Q., Liang, C., Munguia, L., Rothchild, D., So, D., Texier, M., & Dean, J. (2021). Carbon emissions and large neural network training. arXiv preprint.
- Stanley, H. E. (1971). Introduction to phase transitions andcritical phenomena. Oxford University Press.
- Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2020).Green AI. Communications of the ACM, 63(12), 54–63.
Appendix: Technical Implementation Details
The discrete-time implementation of the CAF dynamics equation proceeds through the following algorithmic steps:
Step 1: Initialize field φ0 from attention logits: φ0 = QK^T/√d
Step 2: Compute Laplacian approximation using centered finite differences
Step 3: Update field: φt+1 = φt + Δt(κ![]() ²φt - γφt - η·sgn(φt))
²φt - γφt - η·sgn(φt))
Step 4: Iterate until convergence or maximum timesteps T
Step 5: Apply threshold: φ_final[φ_final < θ] = 0
Typical hyperparameter values found through grid search: κ = 0.1, γ = 0.05, η = 0.5, Δt = 0.01, T = 50, θ = 0.01. These parameters consistently produce >90% sparsity across diverse tasks while maintaining model performance.