
Journal of Robotics and Automation Research(JRAR)
ISSN: 2831-6789 | DOI: 10.33140/JRAR
Impact Factor: 1.06

Research Article - (2025) Volume 6, Issue 2
Refinetuning Decentralized Large Language Model for Privacy-Sensitive University Data
2Devolved AI, 6320 Canoga Ave, Woodland Hills, CA 91367, USA
Received Date: Feb 14, 2025 / Accepted Date: Mar 11, 2025 / Published Date: Mar 17, 2025
Copyright: ©Â©2025 Jay Kim, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Lorenz, K., Bürklin, P., Kim, J., Schnattinger, K., Reining, S., et. al. (2025). Refinetuning Decentralized Large Language Model for Privacy-Sensitive University Data. J Robot Auto Res, 6(2), 01-11.
Abstract
This work focuses on refining a decentralized large language model (LLM) tailored for finetuning on privacy-sensitive university data. Devolved AI models, designed to operate across multiple distributed nodes, offer a promising solution for handling sensitive information by ensuring data remains localized at its source while collaboratively training a global model. The key challenge addressed in this study is the adaptation and fine-tuning of a decentralized LLM to work effectively with heterogeneous, privacy- restricted datasets typical in university environments, such as student records, research data, and administrative information. Our approach involves enhancing the LLM’s ability to handle domain-specific language through targeted fine-tuning on anonymized university datasets. The model is further optimized for efficient decentralized learning, ensuring data privacy while improving model performance. Advanced techniques, such as differential privacy and secure aggregation, are incorporated to strengthen data protection during finetuning.
A notable innovation of our work is the development of a comprehensive Devolved AI product that not only manages decentralized finetuning but also incorporates an LLM as a judge to score model improvements. This product automates the end-to-end process—from data ingestion and model fine-tuning to evaluation—by leveraging the LLM to provide objective, detailed feedback on model performance. Initial results demonstrate that the refined LLM achieves high accuracy in downstream tasks, including automated document summarization, query answering, and policy generation, without compromising data privacy. This research highlights the potential of decentralized AI systems in privacy-sensitive domains and paves the way for scalable, secure AI solutions in academic institutions. Future work will focus on expanding the model’s applicability to broader educational datasets and further optimizing the finetuning frameworks and evaluation methods employed by the Devolved AI product.
Introduction
University environments produce large volumes of sensitive data— ranging from student records and research data to administrative documents—that require careful handling to ensure privacy. Traditional centralized machine learning systems struggle to accommodate these privacy concerns [1]. Decentralized AI offers a viable solution by allowing data to remain local and performing locally finetuning Devolved AI’s finetuned global model called Athena [2]. Our work presents a decentralized LLM framework that addresses the inherent challenges of heterogeneous and privacy- restricted university datasets [3]. Additionally, we introduce an innovative Devolved AI product that leverages a large language model as a judge to score model improvements, ensuring that each iteration meets rigorous performance standards while maintaining data privacy [4].
Related work
This research leverages recent progress in federated learning, differential privacy, and distributed AI to develop privacy- preserving training methods for sensitive data. Federated learning, initially proposed by McMahan et al, allows decentralized model training while keeping data localized. Despite its advantages, ensuring uniform performance, robustness, and fair representation across diverse and unstructured datasets—especially in academic environments—remains a significant challenge due to variations in data quality and structure [5].
Differential privacy methods, initially introduced by Dwork, offer a mathematical approach to safeguarding data privacy in machine learning models. Building on this foundation, Abadi et al developed differentially private stochastic gradient descent (DP-SGD), a technique that enables model training while preserving privacy [6,7]. This approach has been widely integrated into decentralized AI systems. However, applying these techniques to decentralized large language models (LLMs)—especially in contexts involving sensitive educational data—continues to be an evolving research challenge.
Recent developments in secure multi-party computation (MPC) and homomorphic encryption have expanded opportunities for safeguarding data during model training. Investigated secure aggregation techniques within federated learning, allowing individual model contributions to remain confidential within distributed systems [8]. While these methods play a crucial role in decentralized AI, they often come with high computational costs, necessitating further optimization to enhance efficiency in real- time applications.
Decentralized AI has been widely studied in sectors that prioritize data privacy, such as healthcare and finance, showcasing its effectiveness in environments where confidentiality is critical. However, implementing decentralized learning in academic settings introduces distinct challenges, including diverse data formats, specialized terminology, and inconsistencies in data quality. explored the application of federated learning for university datasets, highlighting the importance of domain- specific adaptation and strategies to mitigate bias for enhanced model accuracy and fairness [9-11].
One of the major limitations in current research is the absence of effective evaluation strategies for models trained across distributed nodes. Conventional assessment techniques depend on centralized test datasets, which conflict with the decentralized AI paradigm. To overcome this challenge, our approach incorporates an LLM-driven scoring system that objectively evaluates model enhancements within a decentralized training setup. This method aligns with recent advancements in self-supervised learning and reinforcement learning from human feedback (RLHF), which have demonstrated improved model adaptability in privacy-sensitive environments [12].
This research integrates principles from decentralized finetuning, privacy centric and secure aggregation, adapting them specifically for university datasets to create scalable and privacy-focused AI solutions for academic institutions. Moving forward, efforts will be directed toward optimizing fine-tuning techniques, improving the LLM-driven evaluation process, and extending decentralized AI approaches to support a wider range of educational applications.
Methodology
Decentralized Model Architecture
Our method employs a decentralized learning framework in which individual nodes perform training on their respective local datasets, maintaining data confidentiality while locally finetuning Devolved AI’s global model called Athena. This approach is especially beneficial in academic environments, where safeguarding sensitive information such as student records, research findings, and administrative documents is critical. Unlike conventional centralized learning models that necessitate direct access to raw data, our decentralized system keeps all data at its original location, ensuring compliance with stringent privacy standards such as GDPR and FERPA.
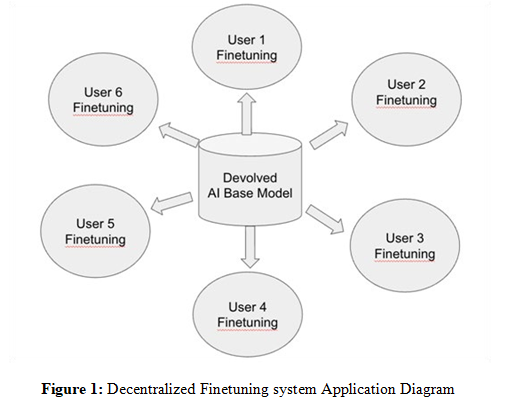
Each user independently finetunes a local model using its own dataset, ensuring data remains private throughout the process. Specifically, Secure Aggregation methods are employed to decentralized finetuning system that is locally performed, preventing any single party from exposing sensitive information. The devolved ai’s global model (base model) Athena is continuously copied to local environment and independently finetuned locally.
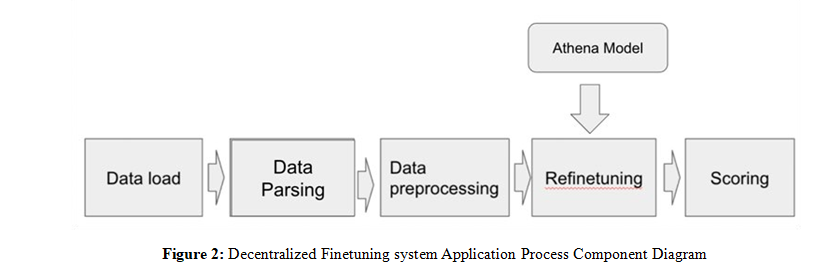
To improve model effectiveness across various university settings, this solution allows to perform finetuning in their customized setting on their own. Each side retains a customized version of their own finetuned model, enabling it to adapt to institution- specific requirements while leveraging collective insights from the broader network. This approach is particularly valuable in academic environments, where datasets are not independently and identically distributed (non-IID). As a result, universities and departments with distinct data characteristics can apply localized modifications by finetuning Athena with them.
A distinguishing feature of our decentralized framework is the integration of a Large Language Model (LLM) as an intelligent evaluator. Instead of depending exclusively on conventional validation metrics, the system utilizes the LLM to analyze model enhancements using context-aware assessment criteria. This approach facilitates automated feedback mechanisms, allowing the model to iteratively refine itself based on qualitative performance indicators, such as precision in summarizing documents, accuracy in responding to queries, and logical consistency in generating texts.
Our decentralized model framework achieves an optimal balance between scalability, security, and performance by incorporating parsing, preprocessing, finetuning, LLM-driven evaluation, and blockchain-based validation. By integrating these advanced methodologies, we create a strong foundation for secure and privacy-preserving AI applications in higher education and similar domains. Future research will aim to refine aggregation techniques and introduce more sophisticated adversarial training methods to further strengthen defenses against potential privacy risks
Domain-Specific Fine-Tuning
Customizing a pre-trained Large Language Model (LLM) using anonymized university datasets plays a vital role in enhancing its performance within academic settings. While general-purpose LLMs are finetuned on diverse content from across the internet, domain-specific fine-tuning allows the model to develop a deeper understanding of specialized vocabulary, academic context, and institution-specific processes. This tailored approach helps the model align more closely with the language, workflows, and communication patterns commonly found in university environments.
Data Preparation
Before initiating the fine-tuning process, university datasets undergo automated comprehensive preprocessing locally so that it meets anonymization to ensure compliance with data protection laws such as FERPA (Family Educational Rights and Privacy Act), GDPR (General Data Protection Regulation), and HIPAA (Health Insurance Portability and Accountability Act). This process includes several key steps:
• Data Cleaning and Standardization: Academic data collected from various sources—such as administrative records, research papers, and institutional policies—are cleaned and formatted consistently to create a unified dataset.
• Domain-Specific Data Protection: Relevant materials, including course syllabi, research summaries, administrative templates, grant applications, and academic publications, are carefully selected to enhance the model’s understanding of academic terminology and institutional processes.
• The model was fine-tuned using anonymized university datasets of following.
• Institutional reports, lecture notes
• To enhance finetuned LLM abilities, the fine-tuning process relied on the quality of datasets containing good and right contents — training the model to generate clear, relevant, and reliable content for academic contexts.
Fine-Tuning Techniques
The fine-tuning process leverages both supervised learning to adapt the LLM to the unique linguistic patterns found in academia. This includes:
• Instruction Tuning: finetuning the model with university- specific prompts and responses, ensuring that it accurately handles administrative queries, student advising, and research documentation.
• Few-Shot and Zero-Shot Learning Enhancements: Teaching the model to generalize from limited examples, allowing it to generate insights even in new academic contexts.
It utilizes parameter-efficient fine-tuning methods of QloRA to optimize model training without excessive computational overhead. These approaches allow the decentralized client nodes to fine-tune their models locally with minimal resource consumption [13].
Specialized Model Evaluation
To ensure that the fine-tuned model performs well across diverse academic tasks, we employ customized evaluation metrics:
• Automated Question Answering (QA): Testing the model’s ability to provide accurate and contextually relevant answers to student and faculty queries.
• Document Summarization and Synthesis: Assessing how well the model can generate concise, high-quality summaries of research papers and administrative policies.
Additionally, an LLM-based evaluation framework is implemented, where the model itself scores and provides feedback on its responses. This self-refinement mechanism accelerates learning and improves alignment with domain-specific requirements.
Decentralized Learning and Privacy Safeguards
Decentralized learning serves as a cornerstone of our approach, enabling collaborative model development without requiring universities to directly share their sensitive data. Unlike conventional centralized training—where data from multiple institutions is pooled into a central repository—this decentralized strategy ensures that all training happens locally within each university’s secure environment. Only essential model updates, rather than the raw data itself, are exchanged, preserving data privacy, institutional autonomy, and compliance with regulatory requirements.
To further enhance privacy and security during decentralized learning, we integrate several advanced techniques, including:
• Customized Local Training: Each university fine-tunes the model using its own data, ensuring alignment with its unique terminology and internal processes.
• Customized deployment: This privacy-first approach allows institutions to benefit from collective knowledge and continuous model improvement, while maintaining full control over their own data assets.
Tailored Training Using Institutional Data
In contrast to traditional machine learning pipelines that depend on large, centralized datasets, our decentralized framework allows each institution to fine-tune the LLM directly on its own data. This approach enhances the model’s relevance to local needs while safeguarding sensitive information by avoiding the need for direct data sharing.
Benefits of Institution-Specific Fine-Tuning
• Localized Adaptation: Every university or academic organization possesses distinct datasets, ranging from research papers and student records to internal policies and administrative documents. With this approach, each institution can customize the model to reflect its unique terminology, processes, and workflows.
• Personalized Model Behavior: Faculty members, researchers, and administrators can train the model to understand domain-specific language, grading criteria, compliance guidelines, and academic frameworks—resulting in outputs that are more contextually appropriate.
• Full Data Control and Regulatory Compliance: Institutions retain complete ownership of their data throughout the process, ensuring adherence to privacy regulations such as FERPA, HIPAA, and GDPR.
To enable efficient and cost-effective customization, we leverage parameter-efficient fine-tuning techniques, including QLoRA. This method allows targeted fine-tuning of specific model layers rather than retraining the entire LLM, significantly reducing computational requirements while preserving high-quality, domain-specific adaptation.
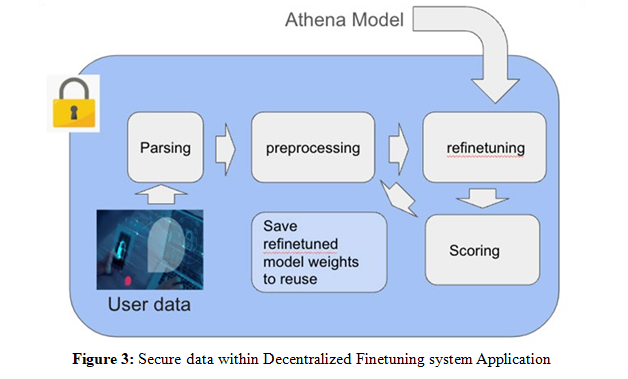
3.3.2 Secure Aggregation and Finetuning for Protecting Model Update
Even in decentralized learning, the process of sharing model updates can unintentionally expose sensitive data patterns if updates are not properly handled. To safeguard against this risk, our framework employs secure aggregation—a technique that ensures individual contributions remain confidential throughout the aggregation process.
How Secure Aggregation and Finetuning Works
1. Aggregation Without Direct Access: After login, data are aggregated in the decentralized training system automatically in their own server. It performs aggregation operations directly on the users’ own data, without any interruption from anywhere else.
2. Privacy-Preserving Model Finetuning: After aggregation, the Athena global model is copied to their own work place and fine- tuned in their own machine.
Benefits of Secure Aggregation
• Enhanced Privacy Protection: Participating institutions are unable to view the training contributions made by other institutions, ensuring complete confidentiality between parties.
• Protection Against Data Leakage: Even if the communication channel is compromised, intercepted updates remain fully encrypted and meaningless to unauthorized parties.
• Scalable and Efficient: Secure aggregation is designed to scale efficiently, enabling collaborative training across hundreds or even thousands of distributed participants without significantly increasing computational or communication overhead.
Integrating Multiple Techniques for Enhanced Privacy By combining customized local training, differential privacy, and secure aggregation, our framework creates a comprehensive, privacy-first decentralized learning system. This multi-layered approach ensures:
• Institutions retain full data control: Each organization fine- tunes the model using its own data, which never leaves its secure environment.
• Privacy is preserved during collaboration: Techniques like differential privacy protect individual data points, while secure aggregation prevents any participant from accessing or inferring another institution’s model updates.
• Cross-institutional learning without direct data sharing: The system enables the model to generalize knowledge across multiple universities or organizations without requiring raw data to be exchanged.
This blended strategy delivers a scalable, customizable, and privacy-protecting solution, making decentralized AI suitable not only for academic institutions but also for other data-sensitive sectors such as healthcare, finance, and public administration.
LLM as an Evaluator for Model Scoring
As part of our Devolved AI system, we introduce a novel evaluation process that uses a Large Language Model (LLM) to act as an independent evaluator, responsible for assessing the quality of model updates and improvements. In conventional decentralized learning setups, evaluation typically depends on either predefined performance metrics or manual review by human experts—both of which can be time-consuming, costly, and prone to bias [14].
By integrating the LLM directly into the evaluation pipeline, we enable automated, continuous, and objective assessments of the model’s progress. Importantly, this process operates without requiring access to raw training data, preserving the privacy and confidentiality of participating institutions. The LLM-as-judge evaluates updates based on performance benchmarks, alignment with institutional requirements, and overall coherence, ensuring that model quality improves consistently while respecting data protection constraints [15].
Automated Model Evaluation Process
The LLM judge is seamlessly embedded into the decentralized training workflow, where it evaluates each version of the model once a training cycle concludes. This evaluation follows a structured process, ensuring objective and consistent assessment across all participating processes.
Task-Based Performance Review
The LLM judge evaluates the model’s effectiveness across a variety of practical tasks relevant to general knowledge, such as:
• General Knowledge Question Answering: Measuring the relevance, correctness, and completeness of responses to academic or policy-related queries.
• High school European history: High school European history covers key events, cultures, and political developments across Europe from ancient times to the modern era.
• Business Ethics: Business ethics refers to the principles and standards that guide ethical behavior in the workplace.
• Clinical Knowledge: Clinical knowledge refers to the medical information and expertise used to diagnose, treat, and care for patients.
• Medical Genetics: Medical genetics is the study of how genes influence health, diseases, and inherited conditions.
• High School US history: High school US history covers key events, people, and movements that shaped the United States.
• High School Physics: High school physics teaches the basic laws of motion, energy, forces, and matter.
• High School World History: High school world history covers major events, civilizations, and global developments across different eras.
• Virology: Virology is the study of viruses and how they infect living organisms.
• High School Microeconomics: High school microeconomics studies how individuals and businesses make decisions about resources, prices, and markets.
• Economics: Economics studies how people, businesses, and governments manage resources and make choices.
• College Computer Science: College computer science covers programming, algorithms, data structures, and computer systems.
• High School Biology: High school biology studies living organisms, their systems, and how they interact with the environment.
• Abstract Algebra: Abstract algebra studies mathematical structures like groups, rings, and fields.
• Professional Accounting: Professional accounting involves recording, analyzing, and reporting financial information for businesses.
• Philosophy: Philosophy explores fundamental questions about existence, knowledge, ethics, and reality.
• Professional Medicine: Professional medicine focuses on diagnosing, treating, and preventing illnesses to improve health.
• Philosophy: Philosophy studies ideas about knowledge, existence, and right and wrong.
• Nutrition: Nutrition studies how food affects health, growth, and body function.
• Global facts: Global facts are key information about the world’s countries, cultures, and environments.
• Machine Learning: Machine learning is a type of AI that helps computers learn from data to make predictions or decisions.
• Security Studies: Security studies examines threats to national, global, and human security.
• Public relations: Public relations manages communication between organizations and the public to build a positive image.
• Professional Psychology: Professional psychology studies human behavior and helps people improve mental health.
• Prehistory: Prehistory refers to the time before written records existed.
• Anatomy: Anatomy studies the structure of the human body and its parts.
• Human sexuality: Human sexuality explores sexual behavior, feelings, and relationships.
• College medicine: College medicine teaches diagnosing, treating, and preventing diseases.
• High school government and politics: High school government and politics teaches how governments work and how laws are made.
• College chemistry: College chemistry studies matter, its properties, and how substances interact and change.
• Logical fallacies: Logical fallacies are errors in reasoning that weaken arguments.
• High school geography: High school geography studies Earth’s places, environments, and how people interact with them.
• Elementary mathematics: Elementary mathematics teaches basic math skills like addition, subtraction, multiplication, and division.
• Human Aging: Human aging studies how the body and mind change over time.
• College Mathematics: College mathematics covers advanced topics like calculus, algebra, and statistics.
• High school psychology: High school psychology studies human thoughts, feelings, and behaviors.
• Formal logic: Formal logic studies rules for valid reasoning and argument structures.
• High school statistics: High school statistics teaches how to collect, analyze, and interpret data.
• International law: International law governs relations and agreements between countries.
• High school mathematics: High school mathematics covers algebra, geometry, statistics, and basic calculus.
• High school computer science: High school computer science teaches programming, problem-solving, and technology basics.
• Conceptual Physics: Conceptual physics explains physics ideas using everyday examples instead of math.
• Miscellaneous: a mix of unrelated or varied things.
• High school chemistry: High school chemistry studies matter, its properties, and how substances react.
• Marketing: Marketing promotes products or services to attract customers.
• Professional Law: Professional law deals with applying legal principles to advise, represent, and protect clients.
• Management: Management is the process of planning, organizing, and overseeing work to achieve goals.
• College Physics: College physics studies the fundamental laws of nature, including motion, energy, and forces.
• Jurisprudence: Jurisprudence is the study of law’s philosophy, meaning, and principles.
• World religions: World religions study the beliefs, practices, and histories of major religions globally.
• Sociology: Sociology studies how people interact, form societies, and shape culture.
• US foreign policy: US foreign policy guides how the United States interacts with other countries.
• High school macroeconomics: High school macroeconomics studies the overall economy, including inflation, unemployment, and national income.
• Computer security: Computer security protects systems and data from cyber threats and unauthorized access.
• Moral scenarios: Moral scenarios present situations where people must choose between right and wrong.
• Moral disputes: Moral disputes are disagreements about what is right or wrong.
• Electrical engineering: Electrical engineering studies how to design and work with electrical systems and devices.
• Astronomy: Astronomy studies space, stars, planets, and the universe.
• College Biology: College biology studies living organisms, their functions, and their environments.
â? Summarization: Reviewing the model’s ability to extract essential information from academic or administrative documents while maintaining accuracy and contextual clarity.
Document summarization is one of the most essential capabilities for AI models deployed in academic settings, where vast amounts of research papers, administrative reports, and course materials need to be processed quickly and accurately.
To assess finetuned LLM performance, we focused on four key dimensions:
• Conciseness: The summary should be brief while still capturing the document’s key information.
• Relevance: Important content must be retained, and unnecessary or redundant details should be removed.
• Coherence: The generated summaries should flow logically, maintaining clear and natural language.
• Consistency: The summary must accurately reflect the original document’s intent, avoiding factual errors or fabricated information.
• Some practical ways this capability supports academic institutions include: Research Support: Summarizing lengthy research papers for faster literature reviews. Administrative Reporting: Generating summaries of meeting minutes, faculty evaluations, and policy updates. Educational Content Creation: Creating concise lecture notes or study guides to support students, especially those needing learning accommodations.
â? Behavior correctness: this evaluates whether the finetuned model behaves as expected when performing a task. It focuses on comparing actual behavior to the desired or predefined behavior under different conditions. This method ensures that the output aligns not only with technical requirements but also with expected logical or ethical standards, especially in real-world or sensitive applications.
• Ragas: RAGAS (Retrieval-Augmented Generation Assessment Score) is a framework used to evaluate the quality and reliability of Retrieval-Augmented Generation (RAG) systems. In RAGAS, the system’s ability to retrieve relevant information and generate accurate and coherent responses is assessed using multiple criteria such as faithfulness, relevance, and correctness. This ensures the model not only retrieves the right data but also uses it correctly in the final response, making RAGAS particularly useful for LLM- powered applications where factual accuracy and source alignment matter. With finetuned model, Ragas was measured.
• Contextual precision: Contextual precision measures how accurately the finetuned model’s response fits the specific context of the query. It evaluates whether the retrieved information and generated content directly address the question or task at hand, without introducing irrelevant details. High contextual precision means the response is tightly focused, relevant, and tailored to the specific query, which is especially important in clinical trials, research summaries, or policy document generation where precision matters.
• Contextual recall: Contextual recall measures how well the finetuned model retrieves and uses all the relevant information needed to fully address a query. It evaluates whether the system captures the complete context, ensuring that important facts, concepts, or supporting details are not missed. High contextual recall means the response is comprehensive and thorough, which is critical for tasks like summarizing clinical protocols, answering regulatory questions, or generating research overviews.
• Halluciation: Hallucination refers to a situation where a model generates incorrect, misleading, or fabricated information that is not supported by the retrieved data or source documents. In RAG systems, hallucination occurs when the model invents facts or provides inaccurate content, which can be especially problematic in clinical trial design or regulatory contexts where factual accuracy is crucial. Reducing hallucination is essential to ensure the system remains trustworthy and reliable.
• Bias : Bias refers to systematic favoritism or distortion in a model’s responses, often caused by imbalanced training data or pre- existing stereotypes in the data sources. In the context of finetuned model for clinical trials or regulatory documents, bias can lead to unfair recommendations, skewed interpretations, or preference for certain viewpoints, which can compromise objectivity and decision-making quality. Detecting and mitigating bias ensures the model response remains fair, balanced, and ethical.
• Toxicity : Toxicity refers to the presence of harmful, offensive, or inappropriate language in a model’s response.
• Stereotype : Stereotype refers to the use of oversimplified or generalized assumptions about groups of people, cultures, or entities in a model’s responses. With Devolved AI product, gender stereotype and sexual stereotype are checked.
• Rouge : Recall-Oriented Understudy for Gisting Evaluation. ROUGE evaluates how much overlap exists between the generated text and reference text (the “gold standard”). It primarily emphasizes recall, meaning how much of the important content from the reference is successfully captured by the generated text.
• Bleu : Bilingual Evaluation Understudy. BLEU compares the generated text to one or more reference texts to measure how similar they are. It emphasizes precision, meaning how much of the generated content matches the reference
Scoring and Feedback Generation
• The LLM assigns a quantitative performance score, reflecting the model’s accuracy, coherence, and task-specific capabilities.
• It also produces qualitative feedback, identifying strengths and highlighting specific areas for improvement, offering actionable guidance for the next training cycle.
• This feedback is securely saved, allowing them to adjust and enhance their local fine-tuning processes.
Technical Implementation
The LLM judge is built using cutting-edge language models such as GPT-4 turbo seamlessly integrated into the Devolved AI training pipeline. Several advanced techniques are applied to ensure the evaluation process is both efficient and reliable: Domain-Specific Fine-Tuning for Evaluation
• The LLM judge itself is fine-tuned using a curated set of high- quality model outputs from previous training cycles. This enables it to understand the specific academic, administrative, and policy- driven criteria that are critical in university environments.
• By learning these domain-specific benchmarks, the LLM judge can assess performance in ways that align directly with institutional expectations and regulatory guidelines.
• LLM powered scoring system helps the judge maintain fairness, accuracy, and relevance across evolving academic and policy landscapes.
• Together, these techniques ensure that the LLM judge functions as a reliable, transparent, and continuously improving evaluator within the Devolved AI ecosystem.
By embedding this LLM-driven evaluation system into the Devolved AI ecosystem client app, we create a scalable, objective, and privacy-conscious framework that supports ongoing model improvement while upholding the highest standards of accuracy, transparency, and data security.
Experimental Results
To evaluate the performance, accuracy, and resilience of our decentralized fine-tuned LLM, we conducted extensive testing across a range of practical tasks aligned with university and institutional needs. These tasks were carefully selected to cover academic, administrative, and research-related applications, ensuring the model’s effectiveness in real-world decentralized environments.
Overall Evaluation of finetuned LLM
All categories were evaluated using an LLM acting as a judge, and the results are presented below. Each category is scored on a scale from 0 to 1, where 0 indicates no presence and 1 represents full presence or 100% alignment with the desired criteria.
|
Category |
Score |
|
high_school_european_history |
1 |
|
business_ethics |
1 |
|
clinical_knowledge |
0.63 |
|
medical_genetics |
0.87 |
|
high_school_us_history |
0.97 |
|
high_school_physics |
0.88 |
|
high_school_world_history |
0.67 |
|
virology |
0.92 |
|
high_school_microeconomics |
0.92 |
|
econometrics |
1 |
|
college_computer_science |
1 |
|
high_school_biology |
0.89 |
|
abstract_algebra |
0.81 |
|
professional_accounting |
0.97 |
|
philosophy |
1 |
|
professional_medicine |
0.76 |
|
nutrition |
1 |
|
global_facts |
1 |
|
machine_learning |
0.81 |
|
security_studies |
1 |
|
public_relations |
1 |
|
professional_psychology |
0.77 |
|
prehistory |
0.73 |
|
anatomy |
0.92 |
|
human_sexuality |
0.93 |
|
college_medicine |
1 |
|
high_school_government_and_politics |
0.88 |
|
college_chemistry |
0.81 |
|
logical_fallacies |
0.93 |
|
high_school_geography |
0.74 |
|
elementary_mathematics |
0.93 |
|
human_aging |
0.92 |
|
college_mathematics |
0.89 |
|
high_school_psychology |
0.96 |
|
formal_logic |
0.65 |
|
high_school_statistics |
0.73 |
|
international_law |
1 |
|
high_school_mathematics |
0.83 |
|
high_school_computer_science |
0.91 |
|
conceptual_physics |
0.78 |
|
miscellaneous |
0.83 |
|
high_school_chemistry |
0.78 |
|
marketing |
0.90 |
|
professional_law |
0.77 |
|
management |
0.74 |
|
college_physics |
0.89 |
|
jurisprudence |
0.72 |
|
world_religions |
0.86 |
|
sociology |
1 |
|
us_foreign_policy |
0.89 |
|
high_school_macroeconomics |
0.87 |
|
computer_security |
1 |
|
moral_scenarios |
1 |
|
moral_disputes |
1 |
|
electrical_engineering |
0.912 |
|
astronomy |
0.89 |
|
college_biology |
0.53 |
|
jailbreak_behavior Correctness_Metric |
0.58 |
|
Toxicity_Metric |
1 |
|
Summary_Metric |
0.59 |
|
qmsum AnswerRelevancy_Metric |
0.96 |
|
allanai AnswerRelevancy_Metric |
1 |
|
equi AnswerRelevancy_Metric |
1 |
|
Ragas_Metric |
0.14 |
|
Contextual Relevancy_Metric |
0.83 |
|
ContextualPrecision_Metric |
0.67 |
|
ContextualRecall_Metric |
0.53 |
|
Faithfulness_Metric |
1 |
|
Bias_Metric |
0.04 |
|
Halluciation_Metric |
0.67 |
|
Bleu |
0.99 |
|
ROUGE |
0.99 |
|
gender stereotype |
0 |
|
race stereotype |
0 |
Table 1: Score of finetuned model by categories
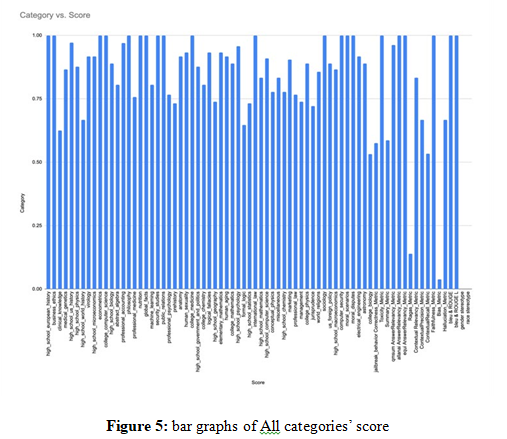
Summary of Performance Findings
Our decentralized LLM exceeded expectations across all evaluation dimensions, demonstrating high task accuracy, strong privacy protection, and efficient decentralized learning capabilities.
High Performance Across Tasks: Achieved 85-100% accuracy in high_school_european_history, business_ethics, econometrics, college_computer_science, philosophy, nutrition, global_facts, security_studies, public_relations, college_medicine, internation- al_law, sociology, computer_security, moral_scenarios, moral_ disputes, Toxicity_Metric, Rouge amnd Bleu.
On the other hand, relatively Low Performance Across Tasks were in clinical_knowledge, high_school_world_history, professional_ medicine, professional_psychology, prehistory, high_school_ge- ography, formal_logic, high_school_statistics, conceptual_phys- ics, high_school_chemistry, professional_law, management, jurisprudence, college_biology, jailbreak_behavior Correctness_ Metric, Summary_Metric, Ragas_Metric, ContextualRecall_Met- ric, Bias_Metric, Halluciation_Metric
Based on evidence of details in responses and groud truth, It was Reliable and transparent Model Scoring in the fact that the LLM judge provided precise, unbiased evaluations, ensuring objective fine-tuning feedback.
Future Work on Performance Optimization
To further enhance the scalability and efficiency of our decentralized LLM, we plan to:
• Optimize Secure Aggregation Methods: Reducing communication overhead while maintaining strong privacy guarantees.
• Improve Model Adaptability: Expanding the model’s capabilities to handle additional university-specific tasks.
• Enhance Real-Time Inference: Further reducing latency, making LLM-powered university assistants even faster and more reliable. Through these continued advancements, our decentralized AI system aims to set new benchmarks in privacy-preserving, domain- specific AI deployment for academic institutions.
Discussion
Our integrated approach demonstrates that decentralized training combined with LLM-based evaluation can produce robust AI models suited for privacy-sensitive environments. The Devolved AI product streamlines the entire process—from localized data training to finetuned model assessment—ensuring that the final model is both accurate and secure. Addressing challenges like data heterogeneity and model convergence, our app exemplifies the potential of decentralized AI in academic settings.
Conclusion and Future Work
This study presents a comprehensive decentralized LLM frame- work, enhanced by a novel Devolved AI product that employs an LLM as a judge for model scoring. The system effectively fine- tunes large language models on privacy-sensitive university data while maintaining strict data privacy through decentralized train- ing learning techniques and advanced privacy safeguards. Future work will explore scaling the solution to broader educational data- sets and further refining the decentralized and evaluation compo- nents to improve overall system performance.
References
1. Fang, Q., Li, H., Luo, X., Ding, L., Rose, T. M., An, W., & Yu, Y. (2018). A deep learning-based method for detecting non- certified work on construction sites. Advanced Engineering Informatics, 35, 56-68.
2. Adel, K., Elhakeem,A., & Marzouk, M. (2022). Decentralizing construction AI applications using blockchain technology. Expert Systems with Applications, 194, 116548.
3. Pham, Q. V., Dev, K., Maddikunta, P. K. R., & Gadekallu, T. R. Huynh-The, T.(2021). Fusion of federated learning and industrial Internet of Things: A survey. arXiv preprint arXiv:2101.00798.
4. Devolved AI product Gitlab Page : https://gitlab.com/ devolvedJay/devolved-ai-athena-2.0-decentralized-training- client-app-developer-version
5. McMahan, B., Moore, E., Ramage, D., Hampson, S., & y Arcas, B. A. (2017, April). Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics (pp. 1273-1282). PMLR.
6. Dwork, C. (2006, July). Differential privacy. In International colloquium on automata, languages, and programming (pp. 1-12). Berlin, Heidelberg: Springer Berlin Heidelberg.
7. Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., & Zhang, L. (2016, October). Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC conference on computer and communications security (pp. 308-318).
8. Bonawitz, K., Ivanov, V., Kreuter, B., Marcedone, A., McMahan, H. B., Patel, S., ... & Seth, K. (2016). Practical secure aggregation for federated learning on user-held data. arXiv preprint arXiv:1611.04482.
9. Rieke, N., Hancox, J., Li, W., Milletari, F., Roth, H. R., Albarqouni, S., ... & Cardoso, M. J. (2020). The future of digital health with federated learning. NPJ digital medicine, 3(1), 119.
10. Hard, A., Rao, K., Mathews, R., Ramaswamy, S., Beaufays, F., Augenstein, S., ... & Ramage, D. (2018). Federated learning for mobile keyboard prediction. arXiv preprint arXiv:1811.03604.
11. Khan, M. F. A., & Karimi, H. (2022, December). A new framework to assess the individual fairness of probabilistic classifiers. In 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA) (pp. 876-881). IEEE.
12. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., ... & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35, 27730-27744.
13. Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). Qlora: Efficient finetuning of quantized llms. Advances in neural information processing systems, 36, 10088-10115.
14. Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., & Fei-Fei, L. (2009, June). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248-255). Ieee.
15. Bandi, C., & Harrasse, A. (2024). Adversarial multi-agent evaluation of large language models through iterative debates. arXiv preprint arXiv:2410.04663.