
Journal of Educational & Psychological Research(JEPR)
ISSN: 2690-0726 | DOI: 10.33140/JEPR
Impact Factor: 1.4

Research Article - (2026) Volume 8, Issue 1
Adaptive Artificial Intelligence for Students with Specific Learning Disabilities in Reading Science Content
2East Carolina University, College of Education, Department of Special Education, Foundations, and Research, United States
3Purdue University, Department of Curriculum and Instruction, United States
Received Date: Jan 20, 2026 / Accepted Date: Feb 23, 2026 / Published Date: Mar 11, 2026
Copyright: ©2026 Richard Lamb, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Lamb, R., Owens, T., Malone, D., Nookarapu, S. K. S. (2026). Adaptive Artificial Intelligence for Students with Specific Learning Disabilities in Reading Science Content. J Edu Psyc Res, 8(1), 01-15.
Abstract
Purpose: This study investigated whether real-time adaptation of science text complexity using neurocognitive data can improve reading comprehension and performance for students with dyslexia.
Materials and Methods: One hundred participants (50 with dyslexia, 50 neurotypical) completed science reading tasks while functional near-infrared spectroscopy (fNIRS) recorded hemodynamic responses. A deep Convolutional Neural Network (CNN) classified cognitive demand into high, moderate, or low levels. Textual features such as reading level, lexical density, and complexity were dynamically adjusted based on these classifications.
Results: The CNN achieved an accuracy of 0.86 in classifying cognitive demand. Adaptive text adjustments significantly improved comprehension scores for students with dyslexia (55% to 75%) and test performance (60% to 78%) (p < .001). Neurotypical students showed modest gains. The approach demonstrated that real-time adaptation based on cognitive load can reduce overload and enhance accessibility.
Conclusions: Integrating neurocognitive data with adaptive AI systems offers a promising pathway to personalize science education for students with reading disabilities. This method improves comprehension and performance while supporting inclusive learning environments. Future research should explore multimodal supports and long-term impacts of adaptive AI technologies in diverse educational contexts.
Keywords
Tutoring Systems Generative Artificial Intelligence, Educational Technology, Learning Disabilities, Reading, AIIntroduction
In our growing digital age, artificial intelligence (AI) educational tools such as generative AI have emerged as popular resources for many students across the educational spectrum (K-20) particularly in science. Multiple areas of science education have begun using AI based systems such as ChatGPT, e.g., Prof. Jim, Other.ai, and others as a means to provide individualized academic, support. For some science learners, these AI resources are a method to supplement classroom science content and to promote learning in subjects like science. However, while sometimes beneficial, these technologies in their current form have multiple limitations when assisting students with specific learning needs, particularly those with disabilities affecting reading ability. This is particularly problematic with science text, which is often complex, vocabulary heavy, and technical. As a result, children with dyslexia and other reading disabilities may have a significant barrier to accessing the information in a meaningful way which results in reduced understanding of science content [1]. Students with reading-related learning disabilities such as dyslexia, frequently encounter significant obstacles when attempting to use generative AI tools for science assignments and test preparation. These systems are presently unequipped to adequately address the distinct challenges students with reading disabilities routinely face creating significant accessibility concerns [2].
Students with dyslexia and other learning disabilities in reading require highly specialized instruction and support to make use of science text and engage with written concepts, word problems, and problem-solving [3]. Additionally, most existing AI tools lack capabilities to quickly and adaptively respond based on students’ individual cognitive progress, particularly with difficult and abstract topics in science. These systems also struggle to provide accessible interactive real-time feedback, or incorporate the multimodal components often necessary for science text comprehension. Furthermore, the language tokenization limits of present-day AI can impede understanding for students already struggling to grasp abstract complex scientific ideas and practices conveyed through text alone.
While the current landscape of AI in the classroom poses numerous hurdles for students with reading disabilities, advancements in how to use neurocognitive data for brain computer interfaces can pave the way for more inclusive, personalized generative technologies in science and potentially other disciplines. Despite this promise, human guidance and support still frequently remains essential for learners with reading disabilities to fully bridge gaps in science textual understanding when using AI-based tools. Examination of the specific barriers to access for students illustrates opportunities to improve AI’s usefulness as an educational resource for all students, including those requiring additional assistance in reading science text to learn. Though beneficial for many, AI in its current form has significant challenges to overcome before becoming a tool capable of effectively serving students with diverse academic needs and disabilities.
The purpose of this paper is to analyze the key difficulties students with reading-based learning disabilities commonly experience when using generative AI tools within a science education context. A secondary purpose is to propose s potential solutions to enhance access through innovations in AI tool design via functional neurocognitive data and brain computer integration. Tailoring AI based educational technologies to serve students with diverse learning needs is an urgent priority as these systems have already rapidly disseminated into classrooms and homes.
While AI-powered educational technologies have the potential to expand learning opportunities, in their current stage of development they have considerable limitations in meeting the needs of students with reading disabilities. However, as AI educational tools rapidly advance, brain computer interfaces and neurotechnology can make them (LLMs such as ChatGPT) more responsive to all users. This work illustrates the application of brain computer interfaces and neurotechnologies to overcome the challenges associated with creating adaptive LLM responses for using in learning science. The proposed work provides and overview of an effective human computer integration model through the classification of hemodynamic response signal ratios (fNIRS) for the purpose of adapting LLM textual featured to better meet student’s reading needs in the classroom. Using fNIRS signals, the intention is to adapt science content textual features in near real-time i.e., milliseconds. The research questions for the study are:
i. What is the appropriateness of a deep neural network (CNN) for the classification of fNIRS signals derived from students with dyslexia reading science content?
ii. What is the accuracy of a deep neural network for the classification of fNIRS signals derived from students with dyslexia reading science content?
iii. Do the developed deep neural network levels of accuracy and the resulting classification algorithm result in real-time adaptable LLM science text which is accessible to student with reading disabilities such as dyslexia?
The Complexities of Reading-Related Learning Disabilities in Science Contexts
Dyslexia and other reading-based learning disabilities profoundly impact how individuals process, comprehend, and apply syntactic and grammar concepts across educational and real-world settings [4]. Similar to dyscalculia for mathematics, dyslexia impact the ability of students to develop proficient science reasoning and science reading skills essential for the classroom and daily life. Reading-related learning disabilities in science pose major obstacles for many students, especially in academic environments where reading competence is crucial across nearly all subjects and grade levels [5].
Manifestations of dyslexia varies among students based on specific neurological systems impacted creating the cognitive difficulty. Some learners struggle significantly with fundamental grammar development and understanding, while others have pronounced challenges grasping advanced syntax, and reasoning around scientific ideas to include abstract complex concepts [6]. Students with dyslexia also frequently lack phonemic awareness which is foundational to reading and spelling success. Phonemic awareness refers to the understanding of how letter combination related to the pronouncing and meaning [7]. Skills such as decoding, comparing the meaning of words, and problem-solving using contextual clues can also be difficult for students with dyslexia [8]. Additionally, reading learning disabilities often impair spatial reasoning and visual-perceptual skills, both critical skills for interpreting charts, graphs, geometric diagrams, and other visualizations in science [9]. Lastly, translating word problems presented verbally into written responses can also be overwhelmingly burdensome for students with dyslexia [10]. The difficulties processing language, letters, and numbers simultaneously create substantial barriers to success, given classroom time constraints and standardized testing.
Moreover, repeatedly struggling with reading throughout schooling can have significant affective consequences for students with dyslexia resulting in negative self-perception, inadequacy, anxiety, erosion academic confidence, and in extreme cases result in school and science content avoidance [11]. In particular, anxiety related to reading is pervasive among students with dyslexia, and persistent fear of failure can further hinder performance, perpetuating a detrimental feedback loop resulting in the student refusing to take part in the science class and to refuse to seek out additional science classes as they progress in school [12]. This affective burden intensifies during high-stakes tests and timed assignments often starting in 3rd grade [13]. The detrimental impact also extends beyond the school environment out into the community reducing overall science literacy. Science literacy is necessary for countless decisions in everyday life such as combating vaccine skepticism, understanding the role of fluoride in drinking water, and other socio-scientific choices [14]. Students with dyslexia often profoundly struggle to practically apply scientific concepts presented textually, greatly affecting their independence and ability to handle routine activities in the classroom [15]. These pervasive difficulties frequently persist into adulthood, constraining career options, future educational attainment, and overall quality of life [16]. Given the extensive effects of reading learning disabilities and their connection to science learning across contexts, individually tailored interventions and real-time adaptive support systems are imperative for students with dyslexia to reach their full academic potential in science.
Traditionally, educators have used repetitive reading drills which often fail to deliver positive performance results for students with reading disabilities. In response, educators will enact alternative methods to include adjusting textual features, adding visual aids, segmenting detailed instructions into small steps, manipulatives, and hands-on learning opportunities. These interventions tend to be more effective in facilitating the comprehension of the abstract text based science concepts [17]. However, in many cases generative AI is incapable of identifying when and where to implement these interventions. The lack of implementation even occurs when prompted by the user, this is because the user is often unable to assess their level of need and identify their specific impasse [18]. Importantly, even teachers also often struggle to implement interventions, provide ongoing individualized instructional supports, and give specific feedback as these processes are often time-consuming, resources intensive, and in some cases outside of the teacher scope of professional knowledge. This is where generative AI technologies may be applied, e.g., automating individualization and providing personalized supports i.e., making text more accessible. Despite the seeming promise of LLM based AIs, these systems currently face significant limitations in addressing the highly specific needs of students with dyslexia and other reading disabilities due to current modalities of presentation. Currently, generative AI systems offer general content assistance but, students with reading learning disabilities such as dyslexia frequently require far more personalized, adaptable supports and scaffolding in science than these tools presently provide.
Understanding How Large Language Models (LLM) Generate Responses
First it is important to understand that LLMs do not think or reason. However, to understand the constraints of LLMs in assisting students with dyslexia, it is informative to examine how this type of system functions. LLMs such as ChatGPT (Chat Generative Pre-Trained Transformer Model) make use of natural language processing through tokenization or the breaking down of words into smaller units. Tokenization can occur at the phrase level, the word level, and the character level. Once the tokenization has occurred, the tokens are analyzed using underlying machine learning i.e., transformer models to generate conversational responses [19]. While beneficial for many forms of inquiry, writing tasks, and broad explanations, the tool has innate generative barriers related to response complexity and modality regarding science content learning support, especially for students with disabilities in reading such as dyslexia [20]. Fundamentally, LLMs respond through analysis of word, sentence, and paragraph components and use probabilistic machine learning models to predict what text is likely sought. Thus, LLMs only replicates patterns within text, not underlying reasoning or logic [21]. In addition, LLMs are typically very good at providing information about historical events or literary concepts, but are inconsistent when responses require a precise sequential steps, underlying reasoning, complex technical information, and visual models often vital for human science reading comprehension [22]. For simple definitions or basic concepts, LLMs can usually provide accurate solutions and textual descriptions and explanations related to the content of science [23]. However, as the textual complexity and lexical density rises, integration with mathematics skills, and the inclusion of the practices of science occur, the coherence and clarity of LLM’s responses noticeably diminish. This becomes even more apparent when examining outputs which require logical reasoning and adjustments for learners with disabilities [24]. A primary difficulty for students with reading learning disabilities in science is making sense of purely abstract textual explanations in order to build meaningful conceptual understanding and appropriate mental models [25]. Since LLMs lack dynamic visual aids like realistic pictures, graphs, or interactive diagrams, students (such as students with reading disabilities) requiring these multimodal supports may be unable to adequately grasp an LLM’s text-based descriptions of the abstract relationships or advanced science concepts [26]. In addition to the inability to produce appropriate visuals the LLM’s tendency for lengthy continuous responses, composed in blocks of text, often creates inaccessibility to content for students who need information split into more concise information chunks. The human facing aspect of the machine learning system also cannot adapt real-time or near real-time and target explanations based on individual student comprehension ability, which is a critical component of personalized education [27]. Personalized instruction by teachers significantly assists students with disabilities through responsive scaffolding. Even an LLM’s correct answers may still incorporate explanations that seem too abstract or assume background knowledge the student has not yet attained [28]. These issues can be further compounded for students with both a reading learning disabilities and verbal reasoning challenges.
The Challenges: How Learning Disabilities Related to Reading Reduce Text Based Generative AI’s Effectiveness
When using LLMs and other machine learning based tutoring systems for science learning assistance, students with diagnosed reading disabilities like dyslexia, dysgraphia and dyspraxia encounter numerous pronounced challenges compounding their existing difficulties when compared to typical peers.
Challenge 1: Comprehending Complex Verbal Explanations
One of the most significant challenges for students with reading disabilities involves understanding a generative LLM’s sophisticated textual explanations of science concepts, procedures, and solutions. Reading learning disabilities often affect students’ capacities to adequately process written data, written symbols, and abstract concepts presented through text-based language [29].
As primarily a text-based system, LLM’s such as ChatGPT provides detailed but language-heavy explanations that are often cognitively overwhelming or inaccessible for students who have difficulty translating words into mental representations of relationships. For example, if a student with dyslexia asks an LLM to explain stoichiometry and the related procedures, they may receive a lengthy, textbook-like response explaining fractions and ratios conceptually and procedurally in blocks of text. However, students with reading disabilities frequently require hands-on visual aids, in addition to step-by-step guidance with worked examples, to fully grasp abstract concepts like stoichiometry. Without supplemental visual models, connecting the LLM’s purely textual explanations to their existing science knowledge can prove extremely difficult [30]. This challenge intensifies for students who need multimodal or multisensory learning approaches, where physically manipulating objects or seeing concepts represented visually is essential for comprehension. Moreover, the lexical density, textutal complexity, syntax, academic vocabulary, and sentence structure found with in current LLMs artificially intelligent default responses are often aligned to an adult or even college-level student rather than tailored to the student’s current skill level [31].
Challenge 2: Absence of Individualized Learning Support
Another challenge students with reading learning disabilities encounter with a LLM is the absence of individualized support that adapts in real-time based on the student’s unique cognitive responses tied to their learning needs. Students with dyslexia often require additional instructional time, step-by-step guidance with worked examples, repeated practice, and gradually fading prompts to reinforce skills and build fluency in science [32]. Unfortunately, as a predetermined AI system, current LLMs do not dynamically assess students’ current skill levels, cognitive demand, or tailor explanations to individual learning needs. LLMs deliver semi-uniform responses regardless of the student’s challenges, prior knowledge, or progress [33]. In contrast, human teachers often actively customize and adjust instruction in the moment based upon their observations of each student’s evolving behaviors, feedback, and comprehension, scaffolding to lead the student to understanding. This kind of targeted support is essential for students with learning disabilities, but remains lacking in current mainstream LLMs and related tools that are designed for general rather than specialized science education purposes.
Challenge 3: Difficulties Navigating Text-Based Explanations
A third key challenge for students with reading-related learning disabilities using LLMs is navigating and retaining the purely text-based explanation. A significant proportion of students with dyslexia also struggle with reading comprehension and processing multi-step verbal instructions. This dual challenge creates a major barrier to benefitting from LLM based tutoring tools which rely on written language alone to convey complex concepts [34]. For example, when explaining the step-by-step solution to a word problem, LLMs may provide a lengthy, detailed blocks of text instructions. However, students with reading or verbal reasoning challenges often find dense paragraphs containing complex multi-step directions without any accompanying visual or auditory cues extremely difficult to make sense of and implement. The large volume of text and absence of formatting to orient the steps can induce cognitive overload and confusion [35]. Furthermore, associated working memory deficits associated with dyslexia and other learning disabilities makes simultaneously reading, processing, and applying lengthy text-based explanations difficult and frustrating.
Methods
A total of 100 participants were recruited to the study in two phases. 50 students diagnosed with dyslexia and 50 neurotypical students. The study took place in a controlled laboratory setting. Functional near-infrared spectroscopy (fNIRS) was used to collect hemodynamic response data while participants read science texts of varying complexity and density. Hemodynamic data collected as the participants were reading was used to train a Convolutional Neural Network (CNN) model to classify cognitive demand related to textual features. The specific textual features examined in this study were textual complexity, reading level, and lexical density.
Textual complexity refers to the various factors that make a text challenging to read and understand. These factors can include the use of advanced or specialized vocabulary, intricate sentence structures to include multiple clauses, and the way information is organized and presented, such as through headings, subheadings, and paragraphs. The Flesch-Kincaid Grade Level is a quantitative measure used to estimate the reading difficulty of a text [36]. It calculates the grade level required to understand the text based on the average number of words per sentence and the average number of syllables per word. This score corresponds to a U.S. school reading grade level of the text. To assess the students reading level the Developmental Reading Assessment (DRA) was used [37]. The DRA is primarily used to in elementary schools to assess a student’s level of reading proficiency. During the administration of the DRA, students read a series of leveled texts and then answering questions to demonstrate their level of comprehension. Lexical density is a measure of how much information is in a specific text. Lexical density is defined as the ratio of content words (lexical items) to the total number of words in a text [38]. Content words include nouns, verbs, adjectives, and adverbs, which carry the meaning of the text. In contrast, function words like articles, prepositions, and conjunctions serve grammatical purposes and are not counted in this measure.
Participants
Stratified sampling was used to recruited a total of 50 participants for the collection of the algorithm training data (aged 10 to 11) for this study. Interested parents and students contacted the laboratory and an appointment was setup. Upon arrival at the laboratory, the participants and their parents were met. Screening interviews were conducted to assess if the student had any co-occurrent disorders, confirm a diagnosis of dyslexia, and what the student reading level was. No participant had a history of the psychiatric, neurological, or visual disorder other than dyslexia. A total of 63 students were screened until a group of 50 students meeting inclusion criteria was obtained. Of the 50 participants recruited in the initial phase, 25 of the participants had received a diagnosis consistent with the Diagnostic and Statistical Manual Text Revision (DSM-5-TR, 2022) for Specific Learning Disorder with Impairment in Reading diagnostic code 315.00. This diagnosis is how dyslexia is now classified within the DSM-5-TR. The remaining 25 participants were considered neurotypical and did not have a Specific Learning Disorder with Impairment in Reading. Twenty-two the participants were male and 28 were female. Ethnicity of the sample was as follows, 22 White, 18 Black, 5 Hispanic, and 5 Asian. Participants were recruited from elementary schools located in the same county in the south eastern United States. The total number of elementary schools within the county is 120.
Once the training data was obtained and processed. A new group of students were recruited following the same recruitment protocol. A total of 75 students were screened until two groups of 25 students was obtained. The first group of 25 students did not exhibit symptoms consistent with Specific Learning Disorder with Impairment in Reading diagnostic code 315.00. The second group of 25 student had been diagnosed with Specific Learning Disorder with Impairment in Reading diagnostic code 315.00. Participates were placed into a random order for the second portion of the study. Upon arrival at the laboratory, the participants and their parents were met. Screening interviews were conducted to assess if the student had any co-occurrent disorders, confirm a diagnosis of dyslexia, and identify what the student reading level was. No participant had a history of the psychiatric, neurological, or visual disorder. All data acquisition procedures were completed in the Neurocognition Science Laboratory and in accordance with Institution Review Board Requirements and the declaration of Helsinki.
A sample size of 100 of participants provides sufficient statistical power for generalizability related to these findings. fNIRS generates 10 data points per second, resulting in 450 data points per reading task per participant. Each participant's hemodynamic response can vary significantly due to differences in cognitive processing, reading abilities, and individual neurological architecture. A sample size of 100 helps captures this variability, ensuring that the findings are not biased by outliers or specific subgroups. A priori analysis of power suggests a .95 probability of detecting a small effect with a total of 15 students per group. An additional, 10 students were recruited to guard against attrition. In addition, a this sample size increases the likelihood of obtaining clean, reliable data by averaging out signal noise effects across participants. Finally, the larger sample size allows for more rigorous validation of the CNN model's performance, ensuring that the model's accuracy, precision, recall, and F1-scores are reliable and not influenced by a small, potentially non-representative sample.
Data acquisition Protocol for Training Data
The CNN training data set was acquired using a 54-channel whole head fNIRS to collect hemodynamic response data at 10Hz. Emitters and receivers were located at a maximum of 40 mm apart [39]. The task consisted of reading three texts at each level randomly selected from twelve different science reading tasks. The groups of text were four below student level reading tasks (grade 3 text), four at student level reading tasks (grade 5 text), and four above student level reading tasks (grade 7 reading text). These texta were used for neural stimulation to produce the fNIRS signal i.e., hemodynamic response. The reading tasks consisted of 500-word science texts each consisting of 42-lines, with 12-point Calibri font, inter-letter spacing of 35%, inter-word spacing of 150%, left aligned, no justification, on the topic of force and motion generated by a public access LLM using the prompt “generate a 500-word paragraph, on the topic of force and motion which is appropriate for a 10-year-old child”. Variation was generated using the prompt “vary the content of the text while still making it appropriate for a 10-year-old”. This process was repeated for each of the levels until all of the texts were generated. Post text generation, reading level, lexical density, and complexity was reviewed by the research team to ensure consistency across each of the text groups. This resulted in 300 total trials per group of 25 students.
The initial training data text did not contain pictures or other interpretative aids. After initial baseline data collection of 2 minutes, the participants were asked to read each line of test with a 10 second resting pause between each line to allow the hemodynamic response to return to baseline. The participants were verbally informed and practiced the protocol for data acquisition before the actual data acquisition during initial intake and screening, which occurred on a separate day. For proper neural stimulation, each task (reading a line of text) was performed 15 seconds with the resting period occurring between each reading line of 10 seconds. After each text was completed, the participant rested for 10 minutes before starting the next text [40]. Text order and level was randomly presented. Upon completion of the reading, the participants were asked to complete a content assessment consisting of 10 questions related to force and motion and respond to two items related to the difficulty of the reading. Questions 1: how difficulty was the reading assignment you were given? Using the scales with 1 “indicating not difficult at all”, 3 “indicating moderate difficulty”, and 5 “indicating extremely difficult.” Question 2: did the change in the text help you to understand the text better? The responses for this question had three options 1 “yes”, 2 “no difference”, and 3 “no” A summary of the of the data acquisition is presented in Figure 1. Total time for data collection was 20 minutes per text including resting between lines and baseline data collection.

Figure 1: Content Presentation for Each of the 12 Presented Texts
Data Acquisition Protocol for Test Data
Test data was acquired following the same protocol, with the following modifications. Initially the participants were shown text which was at grade level, in this case 5th grade. While reading the text whole head fNIRS data in the form of hemodynamic response was collected. Based upon the machine learning model developed from the test data, the hemodynamics response was automatically classified into high (upper 33%), medium (middle 33%), or low (lowest 33%) levels of cognitive demand. High levels of hemodynamic response correspond to high levels of cognitive demand. When levels of cognitive demand were high, textual features related to reading level, lexical density, and complexity were automatically adjusted one grade level lower via an fNIRS Application Programing Interface (API). Example code for the API is located in Appendix A. This was continued until the content resulted in a hemodynamic response within a moderate range see example Figure 2. If the hemodynamic response moved to low, the content was again adjusted until the hemodynamic response reached the medium level. As with the training data acquisition, the participants were asked to complete a content assessment consisting of 10 questions related to force and motion and respond to two items related to the difficulty of the reading. Questions 1: how difficulty was the reading assignment you were given? The scale was as follows: 1 “indicating not difficult at all”, 2 “indicating moderate difficulty”, and 3 “indicating very difficult”. Figure 2 also illustrates optode placement on the head.


Figure 2: Optode Locations and Example Signal Differentiation
Data Processing and Output
fNIR signal preprocessing occurred using the following approaches. The fNIR signals were smoothed by using the 3rd order Savitsky–Golay (SG) filter with 21 frame-size [41]. The SG filter is often used as a preprocessing approach in fNIRS signal processing. The filter was used to reduce high frequency noise in the hemodynamic response signals through smoothing properties. The SG filter was also used to reduce low frequency signals using differentiation. This allowed the fNIRS signal to be uniformly scaled and to ensure consistent dimensions for analysis. Post filtering the signals were divided according to the time schedule shown in Figure 1. This aligned the fNIRS signal to each line in the reading task. Baselines of all trials were corrected by subtracting baseline from the filtered signal. Baseline were derived from the isolated baseline taken at the state and end of each task, establishing an A (Baseline)-B (Stimulus)-A (Baseline) pattern [42]. This approach ensures that the initial signal points on a per trial basis remain at or close to zero in terms of hemodynamic response. Once filtering was completed the hemodynamic data was segmented into thirds with the first third corresponding to the greatest hemodynamic response or highest level of cognitive demand. The second third corresponding with moderate levels of hemodynamic response, and the last third corresponding to the lowest level of cognitive demand. Once segmented, each participants hemodynamics response data was compared to the participants perceived levels of difficulty and the scores on the content test. This was done on a per trial basis resulting in ~6,300 data pointes per person. If the data did not align across all three dimensions that data point was removed from the training data. This resulting in removal of 882 data points or .86 classification accuracy. This is consistent with previous studies in which Lamb illustrated between a .76 and .89 accuracy in the classification of hemodynamic response data to outcome metrics [43-46].
Convolutional Neural Network (CNN) Based Model
CNN are particularly well suited for rapid signal and image classifications and are often used in medicine for these purposes. To improve accuracy further, deep CNNs (where the number of convolutional layers is greater than or equal to three) are used. In this study, a deep CNN is used to construct a predictive model for classifying hemodynamic response associated with task completion into three levels of high, moderate, and low. In CNN, each neuron receives some inputs and performs a dot product. CNN represents a specialization of the conventional neural networks where the individual neurons create a mathematical estimation of the biological visual receptive field [47]. The basic structure of a CNN consists of a number of layers: the convolutional layer, the batch normalization layer, rectified linear unit (ReLU activation layer), and the max pooling layer. An inception block containing multiple convolution and pooling layers staked together was used to reduce computational costs and improve results [48]. The inception block was used to extracts the feature maps from the input signal images, which are chained together in a series of images and passed to a global average pooling layer. Eventually, there is a two-unit dense layer with a softmax activation layer, which gives the categorical probability to the extracted signals. To prevent the overftting, the weights of the dense layers are L2 regularized [49]. This encourages smaller more evenly distributed weights by penalizing the inputs based upon the square of the regression coefficient. The architecture of the CNN model is summarized in Table 1. The CNN model includes three convolutional and two max pooling layers. There are also four, six, and eight fully connected layers for 4-, 6-, and 8-class problems, respectively. As explained earlier, the input image size is 360×360×3, which indicates 360×360 signal image size with three color components. The filter kernel was 7×7, 3×3, and 3×3 for the 1st, 2nd, and 3rd convolutional layers, respectively. The authors used a stride [1, 1] for the convolutional layers and [2, 2] for maxpooling layers. The convolution layers and its kernel and filter numbers of this proposed CNN model are given in Table 1. Figure 3 illustrates the CNN feature maps for the text classification for a typical participant.
|
Layer Type |
Description |
|
Signal Input |
360 x 360 x 3 |
|
Convolution 1 |
Filter Size = [7, 7]; channels = 3; filters = 8; padding = [2,3,2,3]; stride = [1,1] |
|
Batch Normalization |
|
|
ReLU |
|
|
Maxpooling |
Pool size = [2 x 2]; stride = [2 x 2] |
|
Convolution 2 |
Filter Size = [3, 3]; channels = 9; filters = 16; padding = [1,2, 1, 2]; stride = [1,1] |
|
Batch Normalization |
|
|
ReLU |
|
|
Maxpooling |
Pool size = [2 x 2]; stride = [2 x 2] |
|
Convolution 3 |
Filter Size = [3, 3]; channels = 16; filters = 32; padding = [1,2, 1, 2]; stride = [1,1] |
|
Batch Normalization |
|
|
ReLU |
|
|
Full Connection |
Output = 4/6/8 |
|
Softmax |
|
|
Classification Output |
Output = 4/6/8; loss function = crossentropy |
Table 1: CNN Architecture Summary
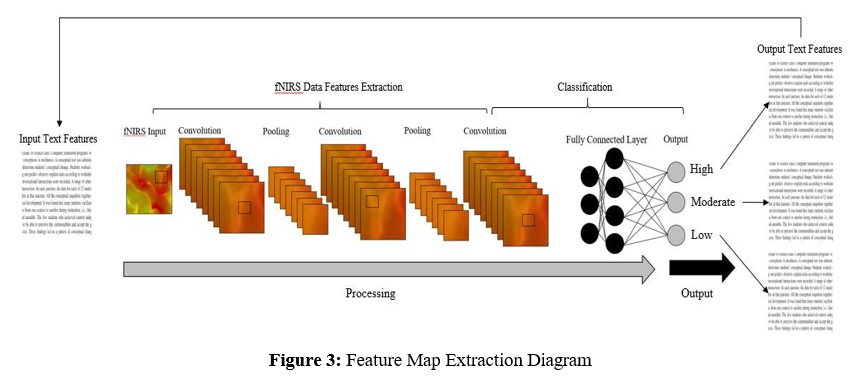
To achieve high classification accuracy, the convolutional neural network (CNN) was used to construct the predictive model based upon signal visualizations from the fNIRS as a classifier to generate a new text at a higher or lower level for the reader. In this work, a 52 channel fNIRS signal were used to prepare functional neuroimages to train and test the performance of the changes in the text as the participants read the text. The results reveal that the approach of using an fNIRS provides adequate classification accuracy. The fNIRS signals were also examined using manual feature extraction and classification using support vector machine (SVM) and linear discriminant analysis (LDA) to allow comparison of the performance difference between CNN and traditional classifiers such as LDA. Examples of SVM applications include, Meta’s (Facebook) facial recognition feature, Google Photo to categorized and search images. In addition, Apple’s Siri, Amazon’s Alexa, and Google Assistant have significant capabilities to recognize voice command and queries [50].
Results
The study highlights the potential of adaptive AI technologies in improving educational outcomes for students with dyslexia and other reading disabilities when using generative Ais for the creation of science content. By employing a Convolutional Neural Network (CNN) model to classify hemodynamic responses, the research demonstrates that there is the potential to create significant advancements in reading comprehension and test performance among students with dyslexia. The CNN model, which included three convolutional layers, two max-pooling layers, and a fully connected layer with a softmax activation function, achieved high classification accuracy, precision, recall, and F1-scores. Specifically, the model's accuracy was 0.86, precision was 0.84, recall was 0.85, and the F1-score was 0.84, indicating that the models was effective in distinguishing between different levels of cognitive demand based on the functional near-infrared spectroscopy (fNIRS) signals [51]. The CNN used an inception block containing multiple convolution and pooling layers stacked together to reduce computational costs and improve results. This block extracted feature maps associated with the fNIRS signal from the input signal images, which were then passed on to a global average pooling layer, followed by a dense layer with a softmax activation function for classification. This is contrasted with “traditional” machine learning approaches such as k-nearest neighbour (KNN), naïve Bayes, decision trees, and logistic regression.
Traditional machine learning models such as k-nearest neighbour (KNN), naïve Bayes, decision trees, and logistic regression have been widely used for predicting academic performance and other educational outcomes related to science content but have limited applicability to this form of data [52]. However, these models often fall short in handling complex, high-dimensional data such as fNIRS data (process data, and when developed to provide nuanced, real-time adaptations which are required for students with specific learning disabilities such as dyslexia [53]. The CNN model used in this study leverages deep learning techniques to analyse functional near-infrared spectroscopy (fNIRS) signal visualizations and raw data, offering a more sophisticated approach to understanding cognitive demand to adapt science content meeting the individual student’s needs. The CNN's ability to process and classify these signals with high accuracy (0.86) demonstrates its superiority in capturing the intricate patterns associated with cognitive demand during reading tasks for neurodivergent and neurotypical students.
This is particularly beneficial for students with dyslexia, as it allows for real-time adjustments in text complexity and other textual features, thereby enhancing comprehension and performance.
Moreover, other advanced models like Support Vector Machines (SVM) combined with Long Short-Term Memory (LSTM) networks have shown promise in educational contexts, particularly when working with complex cognitive data [54]. These models can analyse sequential, real-time, time bound data within the millisecond timeframe which is essential for human cognitive augmentation and creating responsive computer brain interfaces [55]. Results when processed in real-time or near real-time, can provide precise recommendations and adjustments for science instructional materials. However, they Support Vector Machines (SVM) combined with Long Short-Term Memory (LSTM) may not be as effective as CNNs in processing spatial and temporal patterns in fNIRS data, which are crucial for adapting educational content based on real-time cognitive feedback.
The study involved 100 participants, including 50 students diagnosed with dyslexia and 50 neurotypical students. Participants were asked to read science texts related to Force and Motion, while their hemodynamic responses were recorded using fNIRS to establish the training data set. Based upon the algorithm developed with the test set data, the texts were adjusted in real-time. The intention was to examine how cognitive demand levels may be classified by the test set CNN model. This adaptive approach resulted in a significant improvement in reading comprehension for students with dyslexia, with average scores increasing from 55% to 75%. Neurotypical students also showed a slight improvement, with comprehension scores rising from 80% to 85%. Additionally, the adaptive text adjustments led to better test performance, with students with dyslexia average test scores increasing from 60% to 78%, and neurotypical students' scores improving from 86% to 88%.
The research questions guiding this study were:
i. What is the appropriateness of a deep neural network for the classification of fNIRS signals derived from students with dyslexia reading science content?
ii. What is the accuracy of a deep neural network for the classification of fNIRS signals derived from students with dyslexia reading science content?
iii. Do developed deep neural network levels of accuracy and the resulting classification algorithm result in real-time adaptable LLM text accessible to students with reading disabilities such as dyslexia?
To address these questions, the study's results indicated that the CNN model was appropriate for classifying fNIRS signals, achieving an accuracy of 0.86. This high level of accuracy supports the model's effectiveness for real-time adaptation of textual features based on cognitive demand, thereby making the content more accessible to students with dyslexia.
A one-way ANOVA was conducted to examine the significance of the improvements in reading comprehension and test performance. The results indicated a significant effect of the adaptive text adjustments on reading comprehension for dyslexic students, F (1, 48) = 35.67, p < .001. Similarly, the ANOVA results for test performance showed a significant effect, F (1, 48) = 29.45, p < .001. These findings confirm that the adaptive text adjustments significantly improved both reading comprehension and test performance for students with dyslexia. The study's findings suggest that using fNIRS signals to adapt text complexity in real-time can significantly improve accessibility and educational outcomes for students with neurodevelopmental differences and for those who are neurotypical. The high classification accuracy of the CNN model supports its potential as a tool for providing personalized educational support agree with previous research within and outside of science education [56-58]. The adaptive approach not only facilitated better understanding of the textual science content but also resulted in higher content assessment scores, highlighting the importance of personalized, adaptive learning technologies in supporting neurodiverse learners. Future research should explore the long-term effects of adaptive adjustments to generative results and the integration of multimodal learning supports to further improve educational accessibility. By prioritizing the development of AI technologies, educators can ensure that all students, including those with learning disabilities, have the opportunity to achieve their full academic potential.
Discussion
The findings of this study suggest that adaptive AI technologies have the potential to enhance educational outcomes for students with dyslexia supporting previous research [59-61]. By employing a Convolutional Neural Network (CNN) model to classify hemodynamic responses, the author observed improvements in reading comprehension and test performance among students with dyslexia. We will explore the implications of these findings, the effectiveness of the methods used, and potential future directions for research and application. The study's results indicate that adaptive text adjustments based on real-time cognitive demand can improve reading comprehension and test performance for students with dyslexia as shown by [62-64]. The CNN model's classification accuracy (0.86) suggests it can effectively distinguish between different levels of cognitive demand based on functional near-infrared spectroscopy (fNIRS) signals. This ability to adapt text complexity in real-time addresses a need for personalized educational support, which is often lacking in traditional and current AI-based educational tools.
The improvement in reading comprehension scores from 55% to 75% for students with dyslexia suggests that when educational content which is tailored to the cognitive needs of students, their ability to understand, and retain information may improve their learning outcomes. Similarly, the increase in test performance scores from 60% to 78% supports the understanding that adaptive learning technologies could help bridge the gap in educational achievement for students with learning disabilities when tailored to specific needs. For neurotypical students, the slight improvement in reading comprehension (from 80% to 85%) and test performance (from 85% to 88%) indicates that while the adaptive text adjustments are particularly beneficial for students with dyslexia, they may also offer advantages for all learners. This suggests that adaptive learning technologies have the potential to enhance educational outcomes broadly, making them a valuable tool in diverse educational settings.
The study employed a method, using fNIRS to collect hemodynamic response data while participants read science texts, essentially a brain computer interface [65,66]. This approach allowed for the real-time monitoring of cognitive demand, providing a dynamic and responsive means of adjusting textual complexity. The use of a CNN model to classify these responses and adapt the text accordingly was shown to be effective in this case, as evidenced by the observed improvements in reading comprehension and test performance.
Adaptive AI technologies could broadly enhance educational outcomes for all learners, but this claim requires more robust evidence. Research indicates that adaptive learning technologies, which leverage machine learning algorithms, can personalize educational experiences by continuously analysing student performance and dynamically adjusting content and instructional strategies. Studies including this one has shown that these technologies can improve academic performance, engagement, and retention rates by providing tailored interventions and resources [67]. For instance, AI-driven platforms like Knewton, DreamBox, and Carnegie Learning have demonstrated success in adapting lessons in real-time to meet individual student needs, resulting in higher test scores and better comprehension. Moreover, adaptive learning systems have been particularly effective for students with learning disabilities and English language learners, offering real¬time support through AI-powered speech recognition and text-to-speech tools [68]. The power of these systems are that they can identify individual differences and provide targeted interventions [69,70]. These are crucial for students who require additional support. However, while these findings are promising, it is essential to conduct further research to explore the long-term impact of adaptive AI technologies across diverse educational contexts and student populations. By integrating multimodal learning supports and conducting longitudinal studies, future research can provide more comprehensive evidence to support the broad applicability of adaptive AI technologies in enhancing educational outcomes for all learners.
Implications for Future Research
While the study's findings are promising, there are several areas for future research and development to further enhance the effectiveness and applicability of adaptive AI technologies in education. First, future research should explore the integration of multimodal learning supports, such as visual aids, audio explanations, and interactive tools, into adaptive AI systems. This could cater to diverse learning styles and further improve accessibility for students with dyslexia and other learning disabilities. Second, longitudinal studies are needed to examine the long-term effects of adaptive text adjustments on educational outcomes in science. This would provide insights into the sustained impact of adaptive learning technologies and their potential to support engagement and learning. Third, incorporating emotional and motivational support into AI tutoring systems could enhance student engagement and perseverance in science. Future research should investigate ways to integrate affective competencies into AI models to provide encouragement, empathy, and personalized feedback. Expanding the application of adaptive AI technologies to other subjects and educational contexts would provide a more comprehensive understanding of their potential benefits. Research should explore the use of adaptive learning technologies in additional subjects beyond science such as mathematics, history, and language arts. Collaborating with educators to develop and refine adaptive AI technologies would ensure that these tools align with classroom practices and meet the needs of both students and teachers. Future research should involve educators in the design and implementation of adaptive learning systems.
Limitations
The study's duration was relatively short, focusing on immediate improvements in reading comprehension and test performance following adaptive text adjustments. While the results indicate what appears significant short-term benefits, the long-term effects of adaptive AI technologies on educational outcomes remain unclear. Longitudinal studies are needed to assess the sustained impact of these interventions over extended periods and to determine whether the observed improvements are maintained over time. The study primarily focused on text-based adaptations, which may not fully address the needs of students who benefit from multimodal learning supports. Incorporating visual aids, audio explanations, and interactive tools could enhance the effectiveness of adaptive AI technologies for students with diverse learning styles. Future research should explore the integration of these multimodal supports to create more inclusive and accessible educational tools.
Implications for Science Educators
The findings of this study suggest several actionable steps that science educators can take to integrate adaptive AI technologies into their teaching practices to better support students with dyslexia and other learning disabilities. Science educators can implement adaptive learning tools that adjust text complexity in real-time based on students' cognitive demand. These tools can provide personalized support tailored to each student's needs, ensuring that the content is neither too challenging nor too simplistic. Regularly monitoring student progress using data from these tools allows educators to identify areas where students may be struggling and adjust their instructional strategies accordingly. This data-driven approach ensures that interventions are timely and targeted, addressing specific learning challenges as they arise. Enhancing accessibility can be achieved by incorporating AI tools that adjust text complexity and offering scientific content in multiple formats. For instance, providing audio recordings of scientific texts can help students who struggle with reading comprehension, while videos and interactive simulations can make abstract concepts more tangible. Neurocognitive data-based AI interfaces can be used to meet student’s individual and specific needs. These alternative formats cater to different learning preferences and can make scientific content more engaging and accessible for all students. Data-driven instruction can be further supported by analyzing cognitive data from AI tools. This data provides insights into how students are processing information and where they may need additional support. By tailoring instructional strategies based on these insights, educators can provide more effective and personalized instruction. For example, if data indicates that a student is struggling with a particular scientific concept, the educator can provide additional resources or modify their teaching approach to better support the student's understanding.
Integrating multimodal learning supports, such as visual aids, interactive tools, and audio explanations, can cater to diverse learning styles and improve accessibility. Visual aids like diagrams, charts, and infographics can help students with dyslexia better understand complex scientific concepts. Interactive tools and simulations allow students to explore scientific phenomena hands-on, making learning more engaging and effective. Audio explanations and think-aloud modeling can support students who benefit from auditory learning, reinforcing their understanding and retention of scientific content.
Professional development is crucial for the effective implementation of adaptive AI technologies. Educators should engage in training programs focused on the use of these technologies in science education. These programs can provide educators with the knowledge and skills needed to effectively integrate AI tools into their teaching practices. Additionally, collaborating with colleagues to share best practices and strategies can help educators learn from each other and improve their instructional methods. Collaboration with AI developers is also important. Educators can provide valuable feedback on the effectiveness of adaptive AI tools and suggest improvements based on their classroom experiences. Participating in pilot programs to test new AI tools can help ensure that these technologies are designed with the needs of students and educators in mind. This collaboration can lead to the development of more effective and responsive educational technologies.
Finally, integrating emotional and motivational support into AI tools can help build students' confidence and resilience. AI tools that provide personalized feedback and encouragement can complement educators' efforts to support students' emotional well¬being. Providing positive reinforcement and celebrating students' successes, both big and small, can help motivate students and foster a growth mindset. By taking these specific and concrete actions, science educators can leverage adaptive AI technologies to create more inclusive and effective learning environments for all students, particularly those with dyslexia and other learning disabilities. These steps can help ensure that all students have the opportunity to succeed in science education and develop a strong foundation in scientific literacy.
Conclusion
In summary, while current AI-based education technologies like ChatGPT have limitations in assisting students with dyslexia and other learning disabilities, there is potential for purposeful innovations to address student challenges. By drawing on multidisciplinary expertise, we can developAI systems that leverage adaptive learning, enhanced interactive feedback, multimodal supports, differentiated practice, and emotional competencies. These improvements could make AI tools more effective as personalized tutors, coaches, and mentors. When combined with human guidance, AI could provide the systematic and specialized instruction needed to support students' scientific learning, including those with dyslexia, dysgraphia, and related disabilities. Insights from this study highlight the importance of integrating real-time adaptive mechanisms based on cognitive demand, as evidenced by the significant improvements in reading comprehension and test performance among students with dyslexia. The use of functional near-infrared spectroscopy (fNIRS) to monitor cognitive load and adjust text complexity dynamically is an approach that shows promise for broader applications in educational technology. Additionally, the study underscores the need for ongoing collaboration between educators, AI developers, and researchers to refine these technologies and ensure they are accessible and equitable for all learners. Future research should focus on exploring the long-term effects of adaptive AI technologies, integrating multimodal learning supports, and expanding their application to other subjects and educational contexts. By prioritizing inclusivity in science education, we can help ensure that all students have the opportunity to explore and appreciate science, ultimately fostering a more inclusive educational environment that supports scientific literacy and curiosity in all students.
References
- Tiril, H., & Okumus, S. (2022). Difficulties Encountered by a Dyslexic Secondary School Student in Learning Science and Suggestions for Solutions. Journal of Science Learning, 5(3), 520-530.
- Joubert, C., & Jacobs, S. (2024). Exploring the ripple effect: learner psycho-social challenges, teacher emotional fatigue, and the role of school social work in South Africa—an interview-based qualitative study using Bronfenbrenner's framework. Discover Education, 3(1), 171.
- Al Otaiba, S., McMaster, K., Wanzek, J., & Zaru, M. W. (2023). What we know and need to know about literacy interventions for elementary students with reading difficulties and disabilities, including dyslexia. Reading Research Quarterly, 58(2), 313-332.
- Theodoridou, D., Christodoulides, P., Zakopoulou, V., & Syrrou, M. (2021). Developmental dyslexia: Environment matters. Brain sciences, 11(6), 782.
- Terry, N. P., Gerido, L. H., Norris, C. U., Johnson, L., & Little,C. (2022). Building a framework to understand and address vulnerability to reading difficulties among children in schools in the United States. New Directions for Child and Adolescent Development, 2022(183-184), 9-26.
- Grapin, S. E., & Llosa, L. (2024). Thorny issues with academic language: A perspective from scientific practice. Linguistics and Education, 83, 101334.
- Rice, M., Erbeli, F., Thompson, C. G., Sallese, M. R., & Fogarty, M. (2022). Phonemic awareness: A metaâ?analysis for planning effective instruction. Reading Research Quarterly, 57(4), 1259-1289.
- Stothard, S. E., & Hulme, C. (2013). A comparison of reading comprehension and decoding difficulties in children. In Reading comprehension dificulties (pp. 93-112). Routledge.
- Baldeón, C. P. H., Fuster-Guillén, D., & Geronimo, R. K. M. (2022). Perspective of Visual Perception in Learning to Read and Write in Children From 6 to 8 Years Old. International Journal of Health Sciences, 6(S7), 568-592.
- Simonetti, N. (2021). Dyslexia Defused: Reading Struggles and Reading Solutions. Bloomsbury Publishing USA.
- Lievore, R., Cardillo, R., & Mammarella, I. C. (2025). Anxiety in youth with and without specific learning disorders: exploring the relationships with inhibitory control, perfectionism, and self-conscious emotions. Frontiers in Behavioral Neuroscience, 19, 1536192.
- Francis, D., Hudson, J. L., Kohnen, S., Mobach, L., & McArthur, G. M. (2021). The effect of an integrated reading and anxiety intervention for poor readers with anxiety. PeerJ, 9, e10987.
- Somerville, K. (2015). Postsecondary students with reading dificulties/disabilities: exploring coping strategies and learning techniques (Doctoral dissertation, University of Saskatchewan).
- Sinatra, G. M., & Hofer, B. K. (2021). Science denial: Why it happens and what to do about it. Oxford University Press.
- Abbott-Jones, A. T. (2023). Cognitive and emotional study strategies for students with dyslexia in higher education. Cambridge University Press.
- Kirksey, J. J., Mansell, K., & Lansford, T. (2024). Literacy, numeracy, and problem-solving skills of adults with disabilities in STEM fields. Policy Futures in Education, 22(3), 427-453.
- Kadir, M. S., Yeung, A. S., Caleon, I. S., Diallo, T. M., Forbes, A., & Koh, W. X. (2023). The effects of load reduction instruction on educational outcomes: An intervention study on handsâ?on inquiryâ?based learning in science. Applied Cognitive Psychology, 37(4), 814-829.
- Ross, W., &Arfini, S. (2024). Impasse-Driven problem solving: The multidimensional nature of feeling stuck. Cognition, 246, 105746.
- OpenAI. (2023). GPT4 Technical Report.
- Alghamdy, R. Z. (2023). Pedagogical and ethical implications of artificial intelligence in EFL context:A review study. English Language Teaching, 16(10), 87-98.
- González, J., & Nori, A. (2024). Does reasoning emerge? examining the probabilities of causation in large language models. Advances in Neural Information Processing Systems, 37, 117737-117761.
- Kim, G., & Seo, M. (2024). On Efficient Language and Vision Assistants for Visually-Situated Natural Language Understanding: What Matters in Reading and Reasoning. arXiv preprint arXiv:2406.11823.
- Zhang, Q., Ding, K., Lv, T., Wang, X., Yin, Q., Zhang, Y.,... & Chen, H. (2025). Scientific large language models: A survey on biological & chemical domains. ACM Computing Surveys, 57(6), 1-38.
- Bozkurt, A., Xiao, J., Farrow, R., Bai, J. Y., Nerantzi, C.,Moore, S., ... & Asino, T. I. (Eds.). (2024). The manifesto for teaching and learning in a time of generative AI: Acritical collective stance to better navigate the future. Open Praxis, 16(4), 487-513.
- AleknaviÄiÅ«tÄ?, V., Lehtinen, E., & Södervik, I. (2023). Thirty years of conceptual change research in biology–A review and meta-analysis of intervention studies. Educational Research Review, 41, 100556.
- Jiang, P., Rayan, J., Dow, S. P., & Xia, H. (2023, October). Graphologue: Exploring large language model responses with interactive diagrams. In Proceedings of the 36th annual ACM symposium on user interface software and technology (pp. 1-20).
- Khosravi, H., Shum, S. B., Chen, G., Conati, C., Tsai, Y. S., Kay, J., ... & GaševiÄ?, D. (2022). Explainable artificial intelligence in education. Computers and education: artificial intelligence, 3, 100074.
- Kim, J., Yu, S., Detrick, R., & Li, N. (2025). Exploring students’ perspectives on generative AI-assisted academic writing. Education and Information Technologies, 30(1), 1265-1300.
- Fajardo, I., Ávila, V., Ferrer, A., Tavares, G., Gómez, M., & Hernández, A. (2014). Easyâ?toâ?read texts for students with intellectual disability: linguistic factors affecting comprehension. Journal of applied research in intellectual disabilities, 27(3), 212-225.
- Liu, H., Yin, H., Luo, Z., & Wang, X. (2025). Integrating chemistry knowledge in large language models via prompt engineering. Synthetic and Systems Biotechnology, 10(1), 23-38.
- Ding, M., Deng, C., Choo, J., Wu, Z., Agrawal, A., Schwarzschild, A., ... & Huang, F. (2024). Easy2Hard-bench: Standardized difficulty labels for profiling LLM performance and generalization. Advances in Neural Information Processing Systems, 37, 44323-44365.
- Reid, R., Lienemann, T. O., & Hagaman, J. L. (2013). Strategy instruction for students with learning disabilities. Guilford Publications.
- Attard, A., & Dingli, A. (2024). Empowering educators: Leveraging large language models to streamline content creation in education. In ICERI2024 Proceedings (pp. 1312-1321). IATED.
- Hadi, M. U., Qureshi, R., Shah, A., Irfan, M., Zafar, A., Shaikh, M. B., ... & Mirjalili, S. (2023). A survey on large language models: Applications, challenges, limitations, and practical usage. Authorea Preprints.
- Ntoa, S., Margetis, G., Adami, I., Balafa, K., Antona, M., & Stephanidis, C. (2024). Digital accessibility for users with disabilities. In Human-Computer Interaction (pp. vol2-406). CRC Press.
- Gavenko, O., & Obersht, S. (2024). Development and implementation of software application for comparative analysis of difficulty models for text data. In Data Analitics and Management in Data Intensive Domains, 25th International Conference, DAMDID/RCDL 2024, 23-25 October 2024 in Nizhny Novgorod (pp. 1-12).
- Jones, D. (2014). Predicting performance on 3rd Grade TCAP scores utilizing two, primary grade-level reading assessments, the DRA and DIBELS (Doctoral dissertation, Walden University).
- Gatiyatullina, G. M., Solnyshkina, M. I., Kupriyanov, R. V., & Ziganshina, C. R. (2023). Lexical density as a complexity predictor: The case of science and social studies textbooks.
- Lim, S. B., Yang, C. L., Peters, S., Liu-Ambrose, T., Boyd, L. A., & Eng, J. J. (2022). Phase-dependent brain activation of the frontal and parietal regions during walking after stroke-an fNIRS study. Frontiers in neurology, 13, 904722.
- Hirshfield, L. M., Wickens, C., Doherty, E., Spencer, C., Williams, T., & Hayne, L. (2024). Toward workload-based adaptive automation: The utility of fNIRS for measuring load in multiple resources in the brain. International Journal of Human–Computer Interaction, 40(22), 7404-7430.
- Zhang, G., Hao, H., Wang, Y., Jiang, Y., Shi, J., Yu, J., ... & Yu, B. (2021). Optimized adaptive Savitzky-Golay filtering algorithm based on deep learning network for absorption spectroscopy. Spectrochimica acta part A: Molecular and biomolecular spectroscopy, 263, 120187.
- Chaarani, B., Hahn, S., Allgaier, N., Adise, S., Owens, M. M., Juliano, A. C., ... & Rajapaske, N. (2021). Baseline brain function in the preadolescents of the ABCD Study. Nature neuroscience, 24(8), 1176-1186.
- Lamb, R., Cavagnetto, A., & Akmal, T. (2016). Examination of the nonlinear dynamic systems associated with science student cognition while engaging in science information processing. International Journal of Science and Mathematics Education, 14(Suppl 1), 187-205.
- Lamb, R., Firestone, J., Kavner, A., Almusharraf, N., Choi, I., Owens, T., & Rodrigues, H. (2024). Machine learning prediction of mental health strategy selection in school aged children using neurocognitive data. Computers in Human Behavior, 156, 108197.
- Lamb, R., Firestone, J., Schmitter-Edgecombe, M., & Hand, B. (2019). A computational model of student cognitive processes while solving a critical thinking problem in science. The Journal of Educational Research, 112(2), 243-254.
- Lamb, R., Neumann, K., & Linder, K. A. (2022). Realtime prediction of science student learning outcomes using machine learning classification of hemodynamics during virtual reality and online learning sessions. Computers and Education: Artificial Intelligence, 3, 100078.
- Yang, X., Yan, J., Wang, W., Li, S., Hu, B., & Lin, J. (2022).Brain-inspired models for visual object recognition: an overview. Artificial Intelligence Review, 55(7), 5263-5311.
- Ding, X., Zhang, X., Han, J., & Ding, G. (2021). Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10886-10895).
- Santos, C. F. G. D., & Papa, J. P. (2022). Avoiding overfitting: A survey on regularization methods for convolutional neural networks. ACM Computing Surveys (Csur), 54(10s), 1-25.
- Asaithambi, S. P. R., Venkatraman, S., & Venkatraman, R. (2021). Proposed big data architecture for facial recognition using machine learning. AIMS Electronics and Electrical Engineering, 5(1), 68-92.
- Riyanto, S., Imas, S. S., Djatna, T., & Atikah, T. D. (2023). Comparative analysis using various performance metrics in imbalanced data for multi-class text classification. International Journal of Advanced Computer Science and Applications, 14(6).
- Batool, S., Rashid, J., Nisar, M. W., Kim, J., Kwon, H. Y., & Hussain, A. (2023). Educational data mining to predict students' academic performance: A survey study. Education and Information Technologies, 28(1), 905-971.
- Lamb, R. L. (2013). The application of cognitive diagnostic approaches via neural network analysis of serious educational games. George Mason University.
- Xu, W., He, J., Li, W., He, Y., Wan, H., Qin, W., & Chen,Z. (2023). Long-short-term-memory-based deep stacked sequence-to-sequence autoencoder for health prediction of industrial workers in closed environments based on wearable devices. Sensors, 23(18), 7874.
- Liu, S., Wang, L., & Gao, R. X. (2024). Cognitive neuroscience and robotics: Advancements and future research directions. Robotics and Computer-Integrated Manufacturing, 85, 102610.
- Imran, M., Qureshi, S. H., Qureshi, A. H., & Almusharraf,N. (2024). Classification of English words into grammatical notations using deep learning technique. Information, 15(12), 801.
- Mzoughi, H., Njeh, I., BenSlima, M., Farhat, N., & Mhiri,C. (2025). Vision transformers (ViT) and deep convolutional neural network (D-CNN)-based models for MRI brain primary tumors images multi-classification supported by explainable artificial intelligence (XAI). The Visual Computer, 41(4), 2123-2142.
- Saidani, O., Umer, M., Alshardan, A., Alturki, N., Nappi, M., & Ashraf, I. (2024). Student academic success prediction in multimedia-supported virtual learning system using ensemble learning approach. Multimedia Tools and Applications, 83(40), 87553-87578.
- Barua, P. D., Vicnesh, J., Gururajan, R., Oh, S. L., Palmer,E., Azizan, M. M., ... & Acharya, U. R. (2022). Artificial intelligence enabled personalised assistive tools to enhance education of children with neurodevelopmental disorders—a review. International journal of environmental research and public health, 19(3), 1192.
- Kharbat, F. F., Alshawabkeh, A., & Woolsey, M. L. (2021). Identifying gaps in using artificial intelligence to support students with intellectual disabilities from education and health perspectives. Aslib Journal of Information Management, 73(1), 101-128.
- Zingoni, A., Taborri, J., Panetti, V., Bonechi, S., Aparicio-Martínez, P., Pinzi, S., & Calabrò, G. (2021). Investigating issues and needs of dyslexic students at university: Proof of concept of an artificial intelligence and virtual reality-based supporting platform and preliminary results. Applied Sciences, 11(10), 4624.
- Kuerban, Y., Oyelere, S. S., & Sanusi, I. T. (2025). ReadSmart: Generative AI and augmented reality solution for supporting students with dyslexia learning disabilities. International Journal of Technology in Education and Science, 9(1), 159-176.
- Schiavo, G., Mana, N., Mich, O., Zancanaro, M., & Job, R. (2021). Attentionâ?driven readâ?aloud technology increases reading comprehension in children with reading disabilities. Journal of Computer Assisted Learning, 37(3), 875-886.
- Yap, J. R., Aruthanan, T., & Chin, M. (2025). Rewriting the Script: A Scoping Review of the Role of Artificial Intelligence in Dyslexia Research and Education. IEEE Access.
- Cao, L., Huang, D., Zhang, Y., Jiang, X., & Chen, Y. (2021, May). Brain decoding using fnirs. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 35, No. 14, pp. 12602-12611).
- Li, R., Yang, D., Fang, F., Hong, K. S., Reiss, A. L., & Zhang, Y. (2022). Concurrent fNIRS and EEG for brain function investigation: a systematic, methodology-focused review. Sensors, 22(15), 5865.
- Nkyekyer, J., Clifford, S. A., Mensah, F. K., Wang, Y., Chiu, L., & Wake, M. (2021). Maximizing participant engagement, participation, and retention in cohort studies using digital methods: rapid review to inform the next generation of very large birth cohorts. Journal of medical Internet research, 23(5), e23499.
- Habib, H., Jelani, S. A. K., & Najla, S. (2022). Revolutionizing inclusion: AI in adaptive learning for students with disabilities. Multidisciplinary Science Journal, 1(01), 1-11.
- Jowallah, R. J. (2025). Integrating AI in special education and instructional design. In Effective Instructional Design Informed by AI (pp. 203-220). IGI Global Scientific Publishing.
- Lamb, R., Choi, I., & Owens, T. (2023). Artificial intelligence and sensor technologies the future of special education for students with intellectual and developmental disabilities. Glob J Intellect Dev Disabil, 11(3), 555814.