
Advances in Machine Learning & Artificial Intelligence(AMLAI)
ISSN: 2769-545X | DOI: 10.33140/AMLAI
Impact Factor: 1.755

Research Article - (2026) Volume 7, Issue 2
A Lightweight Contrastive System for Misinformation Detection in Social Media Tweets
Received Date: Mar 03, 2026 / Accepted Date: Apr 20, 2026 / Published Date: May 07, 2026
Copyright: ©2026 Priyam Saha. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Saha, P. (2026). A Lightweight Contrastive System for Misinformation Detection in Social Media Tweets. Adv Mach Lear Art Inte, 7(2), 01-06.
Abstract
A compact classification system was developed and submitted to Prompt RecOvery for MisInformation Detection (PROMID) Subtask 3 for the detection of misinformation in tweets about the Russia-Ukraine conflict on the Twitter platform, as provided by the workshop organizers at Forum for Information Retrieval Evaluation (FIRE) 2025, held at the Indian Institute of Technology (BHU) Varanasi, India. The proposed solution combines a frozen RoBERTa encoder, a small projection head trained with a supervised contrastive objective, and a lightweight classifier trained jointly with binary cross-entropy. Design choices were driven by compute and memory constraints; several practical implementation details and evaluation outcomes are reported to support reproducibility of results. The submission of predictions computed on the test dataset as provided by the organizers was made on the Codabench platform as team 'priyam_saha17' and submission ID as 431064. On the official test set, the methodology produced a weighted F1 score of 0.82 (precision 0.87, recall 0.80), thereby securing the 5th rank in the track leaderboard, accessible at Link. For comparison, the leaderboard was topped by team 'ClimateSense', who achieved a weighted F1 score of 0.91 (precision 0.91, recall 0.91). The approach, training pipeline, and error analysis are documented in order to assist future participants and applied researchers working under limited resource conditions.
Keywords
Misinformation Detection, Contrastive Learning, Roberta, Social Media, PROMID
Introduction
Misinformation on social media has been recognized as a substantial challenge for public discourse and policy. Automated detection systems were requested in PROMID Subtask 3 to classify tweets related to the Russia-Ukraine conflict as misinformation or non-misinformation. Building on prior work presented at FIRE, this article presents an extension that consolidates the original methodology and findings in a journal format [1]. This work documents a memory-efficient pipeline that was designed to operate on a single 16 GB Tesla P100 GPU by freezing the transformer encoder and training compact head modules. The central design objective was to maximize representational separation between labeled classes using supervised contrastive learning while keeping the number of trainable parameters low on account of constrained compute resources.
Related work
Contrastive representation learning has been widely adopted for visual and textual tasks due to its effectiveness at structuring embedding spaces. Classical methods for self-supervised contrastive learning were popularized by Chen et al., who demonstrated the power of data augmentations and large-batch contrastive losses [2]. Supervised variants that exploit label information were later proposed by Khosla et al., showing improved downstream classification performance when positive pairs are formed from examples with the same label [3].
Pretrained language encoders such as RoBERTa and BERT have been extensively used for classification tasks; their contextualized representations are commonly fine-tuned end-to-end for high performance [4,5]. Under compute constraints, however, head-only fine-tuning (freezing the encoder) is a pragmatic alternative and has been used in applied settings to balance cost and accuracy as put forward by Zhang et al. [6]. Recent work has also shown that combining contrastive objectives with supervised classification can increase robustness and separation in learned spaces [7].
The Prompt Recovery for Misinformation Detection (PROMID) shared task has been introduced to systematically study misinformation detection under prompt recovery and generalization settings [8]. The task statement, subtasks, datasets, and evaluation metrics are described in detail by the organisers, providing a unified benchmark for multilingual and topic-focused misinformation detection in social media [9].
The PROMID Subtask 3 dataset collection was informed by a link-based annotation framework, namely, AMUSED, proposed by Shahi et al. [10], and the subtask dataset has been shared by the organizers [11].
Dataset and Preprocessing
The PROMID Subtask 3 dataset was provided by the organisers and consisted of manually annotated tweets collected during the first year of the Russia-Ukraine war. Two labeled CSV files were supplied: misinfo_train.csv (positive class) and nonmisinfo_train. csv (negative class). A held-out test CSV without labels was provided for final predictions.
A compact summary of data used in experiments is shown in Table 1. The negative class was heavily over-represented in the original collection and was downsampled to form a balanced training set so that contrastive positives and negatives were both balanced at a count of 364 during mini-batch training. Empty or very short text entries were removed. Tokenization was performed using the RoBERTa tokenizer with truncation to a maximum length of 512 tokens.
|
Split |
# samples |
Notes |
|
Misinfo (original) |
364 |
positives extracted from misinfo_train.csv |
|
Non-misinfo (original) |
34,174 |
full negative pool before downsampling |
|
Combined (balanced) |
728 |
positives + downsampled negatives |
|
Train (80%) |
582 |
stratified split |
|
Validation (20%) |
146 |
stratified split |
|
Test (held-out) |
2,414 |
Final predictions were produced for these samples |
Table 1: Dataset Statistics Used in the Experiments
Methodology
The pipeline was intentionally simple and reproducible. The core modules are:
• Encoder. A pretrained Roberta-base model was used to extract contextual token embeddings. The encoder parameters were frozen during head-only training to reduce memory consumption and runtime.
• Pooling. Mean pooling across token embeddings (masked by the attention mask) was used to obtain a single vector representation per tweet from the token-level embeddings obtained from the encoder.
• Projection head. A small feedforward projection head (Dense → Dropout → Dense → LayerNorm) was trained with stochastic dropout active during training so that calling the projection head twice produced two stochastic views of the same example.
• Classifier head. A compact classifier (Dense (256, gelu) → Dropout → Dense (1, sigmoid)) was trained jointly to produce final binary predictions.
The training objective combined a supervised contrastive loss and a binary cross-entropy loss so that the representation space was encouraged to bring same-label examples closer while the classifier learned decision boundaries on the pooled vectors.
Contrastive Learning: Conceptual and Mathematical Description
Contrastive learning aims to structure the representation space such that similar (positive) pairs are close while dissimilar (negative) pairs are separated. In supervised contrastive learning, the class labels are used to generate positive pairs for each anchor.
Given a minibatch of N examples, two stochastic views of each example were produced through dropout in the projection head, resulting in 2N projections {zi}2N i=1 (each zi is P2-normalized).Let yi denote the integer label for the example corresponding to projection zi; labels are duplicated to match the 2N projections.
The supervised contrastive loss used in this work is defined per anchor i as:
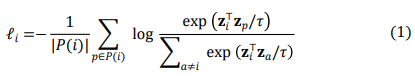
where ![]()
is the set of positive indices for anchor i, and ![]() > 0 is a temperature hyperparameter. The final contrastive loss is averaged across anchors:
> 0 is a temperature hyperparameter. The final contrastive loss is averaged across anchors:

The supervised contrastive formulation encourages clusters corresponding to the same label while using all other examples in the batch as implicit negatives, improving utilization of batch information compared to pairwise binary losses. For reference, early self-supervised instantiations such as SimCLR used two augmented views of the same instance and an InfoNCE loss; the supervised extension is discussed extensively in [2,3].
Combined Loss and Optimization
The classifier produced a scalar probability y^ ![]() (0,1). The binary cross-entropy loss was computed in the usual way:
(0,1). The binary cross-entropy loss was computed in the usual way:
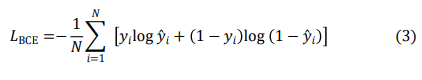
The final training objective was a weighted sum:
![]()
with ![]() = ß = 1.0 selected after light tuning. Gradient updates were applied only to the projection and classifier head parameters (unless an experimental unfreeze of top encoder layers was explicitly activated).
= ß = 1.0 selected after light tuning. Gradient updates were applied only to the projection and classifier head parameters (unless an experimental unfreeze of top encoder layers was explicitly activated).
Implementation Details
The overall system architecture is summarized in the flowchart shown in Figure 1, which illustrates the preprocessing steps, the frozen encoder, the contrastive projection pathway, and the classifier used to produce final predictions.

Figure 1: Flowchart Illustrating the Complete Pipeline of the Proposed Lightweight Contrastive System
The system was implemented in TensorFlow 2.x using HuggingFace models. Key configuration choices were:
• Model: roberta-base (encoder), projection dim = 64.
• Input: Tokenization via RoBERTa tokenizer, max length = 512, truncation enabled.
• Batching: batch size = 16, training with shuffling and prefetch for tf.data pipelines.
• Optimizer: Adam with initial learning rate 3×10-4 on head parameters.
• Regularization: Dropout in heads and gradient clipping (global norm = 10).
• Training policy: Early stopping after 6 epochs with no validation F1 improvement; LR reduced by a factor of 0.5 after 3 non-improving epochs.
• Compute: Encoder parameters were frozen to limit memory; A standard Kaggle notebook was utilized for fine-tuning the model, leveraging a Tesla P100 GPU with 16 GB of memory, a maximum of 29 GB of RAM, and up to 57.6 GB of disk space.
During training, the projection head was invoked twice per batch with training=True (dropout active) to generate the two stochastic views without performing two encoder forward passes. This choice was made to minimize memory and computation while still obtaining the stochasticity required for contrastive training.
Results
Validation Dynamics
Training was monitored with average losses (contrastive and classifier) and validation precision/recall/F1. The contrastive loss decreased rapidly in early epochs as the projection head learned to structure the embedding space; classifier loss dominated later epochs, indicating head-level weight adjustments for the classification boundary. Learning rate reductions and early stopping were used to prevent overfitting on the small, balanced training set.
Final Evaluation
Final predictions were produced on the provided test CSV and scored by the organizers' program. The official classification report returned the following per-class and aggregated metrics:
• nonmisinfo: precision = 0.96, recall = 0.80, F1 = 0.87, support = 2002.
• misinfo: precision = 0.4567, recall = 0.8285, F1 = 0.59 support = 414.
• weighted average F1: 0.8213.
The submission was made by the name of priyam_saha17 (ID 431064) on the PROMID leaderboard for the hackathon hosted by PROMID Subtask 3 organisers on CodaBench.
The three panels in Figure 2 summarize the optimization trajectory. The learning rate remains flat until the scheduler triggers two stages of reductions. Contrastive loss converges rapidly as the projection space stabilises, while classifier loss declines more gradually as the boundary is refined. The validation curves reflect the model's high recall behavior throughout training and improving F1 until early stopping.

Figure 2: Training Dynamics of the Lightweight Contrastive System. Panel (a) Shows Scheduled Learning Rate Reductions. Panel (b) Shows a Rapid Decrease in Contrastive Loss and Slower BCE Convergence. Panel (c) Shows Stable Recall with More Variable Precision, Resulting in Steady F1 Improvement
Ablation Study
An ablation study was conducted to evaluate the contribution of the supervised contrastive objective and the binary cross-entropy classifier loss to the final performance based on a validation split off the training dataset. The full model jointly optimizes both objectives with equal weights (α = β = 1.0). Two reduced variants were evaluated: (i) a classifier-only configuration where the contrastive term was removed (α = 0), and (ii) a contrastive-only configuration where the classifier loss was removed (β = 0) in Table 2. Table 2:
|
Configuration |
α |
β |
Validation F1 |
Validation Recall |
Validation Precision |
|
Classifier only |
0.0 |
1.0 |
0.6667 |
1.0000 |
0.5000 |
|
Contrastive only |
1.0 |
0.0 |
0.0941 |
0.0548 |
0.3333 |
|
Contrastive + Classifier |
0.5 |
0.5 |
0.7973 |
0.8082 |
0.7867 |
|
Contrastive + Classifier |
1.0 |
1.0 |
0.8387 |
0.7927 |
0.8904 |
Table 2: Ablation Study Showing the Impact of Individual Loss Components. α Denotes the Weight of the Contrastive Loss and β the Weight of the Classifier (Binary Cross-Entropy) Loss The results indicate that the joint optimization of contrastive representation learning and supervised classification is necessary to achieve a balanced precision-recall trade-off and best F1 scores under constrained compute settings. Further, it is observed that weights of α = β = 1.0 yield a higher F1 score on validation data rather than an averaged approach ( α = β = 0.5 ). Hence, the configuration α = β = 1.0 was adopted for prediction on test data.
Discussion
The system exhibited a high recall for the misinformation class but a comparatively low precision, indicating a tendency to over-predict the positive class. Manual inspection of false positives revealed common patterns:
• Tweets that quoted or criticised a claim were sometimes classified as endorsing it because the local text included keywords associated with misinformation; the model lacked explicit modeling of quotation or negation scope.
• Very short tweets, or tweets consisting primarily of a URL or an image reference, were often misclassified due to missing contextual signals.
• Some practical remediation strategies are suggested as follows for future considerations:
• Enriching tweet inputs with surrounding context (linked article title or claim summary) when available.
• If resources permit, unfreezing the encoder or at least the top transformer layers for a small number of epochs to allow the encoder to learn features corresponding to this domain.
Limitations
The principal limitations are the reliance on a relatively small balanced training set obtained by downsampling and the use of a frozen encoder, which limits representation adaptation. The resulting trade-off was computational feasibility vs. maximum attainable performance. The reported system should therefore be interpreted as a strong baseline for low-resource scenarios rather than as a final state-of-the-art submission.
Conclusion
A lightweight supervised contrastive plus classifier system was described and evaluated for PROMID Task 3. The system produced a weighted F1 of 0.8213 on the provided test data. The design choices prioritized memory efficiency and reproducibility: encoder freezing, stochastic projection views via dropout, and a joint contrastive/BCE objective. The results indicate that contrastive separation helps achieve high recall for the misinformation class under constrained resources, and that further improvements are likely if complete or selective unfreezing is introduced.
Acknowledgments
The PROMID organizing committee is gratefully acknowledged for the dataset and the scoring infrastructure. The AMUSED framework and the dataset references provided by the organizers were used as background during the model pipeline design.
Ethical Approval
This study involves the use of social media data (Twitter/X) collected as part of the PROMID shared task. The data was provided by the task organizers for research purposes. No direct interaction with human participants was conducted. All data was handled in accordance with applicable data usage guidelines, and no attempt was made to identify individual users.
Author Contributions
The author was solely responsible for conceptualization, methodology, implementation, experimentation, analysis, and manuscript preparation.
Al Usage Statement
During the preparation of this work, the author used GPT-5.1 for organization and better polishing of the phrases and language used in the article, and Grammarly for grammar and spelling checks. After using these services, the author reviewed and edited the content as needed and takes full responsibility for the publication's content.
References
- Saha, P. (2025). A Lightweight Contrastive System for Misinformation Detection in Social Media Tweets. Working Notes of FIRE, 17-20.
- Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020, November). A simple framework for contrastive learning of visual representations. In International conference on machine learning (pp. 1597-1607). PmLR.
- Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., ... & Krishnan, D. (2020). Supervised contrastive learning. Advances in neural information processing systems, 33, 18661-18673.
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019, June). Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) (pp. 4171-4186).
- X. Zhang, A. Smith. (2021). Head-Only Fine-Tuning: A Practical Approach for Low-Resource Adaptation. Workshop Report. (Discussion of head-only strategies.)
- B. Gunel, T. Afouras, A. Bas, M. C. Miller, A. Zisserman. (2020). Supervised Contrastive Learning for Limited Labels. ICLR Workshop.
- Shahi, G. K., Hegde, A., Satapara, S., Mehta, P., Modha, S., Ganguly, D., ... & Mandl, T. (2025). Overview of the first shared task on prompt recovery for misinformation detection (promid 2025). Working Notes of FIRE, 17-20.
- Mehta, P., Hegde, A., Shahi, G. K., Satapara, S., Modha, S., Ganguly, D., ... & Mandl, T. (2025, December). Prompt Recovery for Misinformation Detection at FIRE 2025. In Proceedings of the 17th annual meeting of the Forum for Information Retrieval Evaluation (pp. 37-40).
- Shahi, G. K. (2020). AMUSED: An Annotation Framework of Multi-modal Social Media Data. ArXiv.
- Shahi, G. K., & Mejova, Y. (2025, May). Too little, too late: Moderation of misinformation around the Russo-Ukrainian conflict. In Proceedings of the 17th ACM Web Science Conference 2025 (pp. 379-390).
A. Reproducibility Checklist
• Code: training script uses TensorFlow 2.x and HuggingFace TFRobertaModel.
• Model: roberta-base, projection , classifier head as described.
• Hyperparameters: MAX_LEN = 512, BATCH_SIZE = 16, LR = 3e-4, gradient clipping norm = 1.0.
• Loss weights: α = β = 1.0.
• Training: early stopping patience , LR reduction factor after 3 non-improving epochs.
B. Code and Notebook
The training notebook script, prediction CSVs, plots used in the article, and the public Kaggle notebook carrying all fine-tuned model artifacts can be found on GitHub1.
C. Additional Resources
This article is an extension of a previously published workshop note [11] at FIRE 2025, where the core methodology and results were originally presented. The corresponding conference presentation, which provides a high-level overview of the approach, is publicly available and can be accessed online2.